 2020-06-30
2020-06-30 388
388
Задание на лабораторную работу выдается каждому студенту индивидуально на специальном бланке и содержит:
– наименование агрегата, механизма, узла или системы;
– выборку значений наработок на отказ заданного объекта;
– величину затрат на проведение операции ТР – с;
– величину затрат на проведение операции ТО – d;
Лабораторная работа предусматривает определение периодичности технического обслуживания.
Для проведения расчетов предусмотрено использование компьютеров с использование программы Microsoft Officе Excel или с использованием разработанной программы для определения режимов технического обслуживания и диагностирования.
3.2 Расчет периодичности технического обслуживания
Периодичность ТО может быть определена: по допустимому уровню безотказной работы агрегата, узла или системы; технико-экономическим методом; экономико-вероятностным методом.
3.2.1 Метод определения периодичности по допустимому уровню безотказности
Метод определения периодичности по допустимому уровню безотказности предусматривает выбор такой периодичности 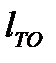 , при которой вероятность возникновения отказа или неисправности ранее установленной периодичности будет меньше обусловленного уровня. При этом для агрегатов, узлов и систем, обеспечивающих безопасность движения, допустимая вероятность безотказной работы принимается Rд = 0,90…0,95, для прочих узлов и агрегатов Rд = 0,85…0,90.
, при которой вероятность возникновения отказа или неисправности ранее установленной периодичности будет меньше обусловленного уровня. При этом для агрегатов, узлов и систем, обеспечивающих безопасность движения, допустимая вероятность безотказной работы принимается Rд = 0,90…0,95, для прочих узлов и агрегатов Rд = 0,85…0,90.
Искомая периодичность 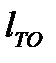 может быть получена путем использования зависимости:
может быть получена путем использования зависимости:
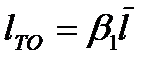 , (3.1)
, (3.1)
где 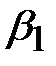 - коэффициент оптимальной периодичности, учитывающий величину и характер вариации наработки на отказ, а также принятую допустимую вероятность безотказной работы. Величина
- коэффициент оптимальной периодичности, учитывающий величину и характер вариации наработки на отказ, а также принятую допустимую вероятность безотказной работы. Величина 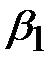 может быть определена из таблицы 3.1.
может быть определена из таблицы 3.1.
Таблица 3.1 – Значения β1
| Rg | β1 при ν | |||
| 0.2 | 0.4 | 0.6 | 0.8 | |
| 0.85 | 0.80 | 0.55 | 0.40 | 0.25 |
| 0.95 | 0.67 | 0.37 | 0.20 | 0.10 |
Для анализа статистических данных при определении периодичности ТО по данному методу рекомендуется использовать статистические процедуры надстройки Пакет анализа (Analysis Tool Pak) и статистические функции библиотеки встроенных функций Excel.
Основные сведения обо всех этих средствах имеются в электронной справочной системе Excel.
Для доступа к процедурам Пакета анализа необходимо в меню Сервис (Tools) щелкнуть указателем мыши на строке Анализ данных (Data Analysis). Откроется диалоговое окно с соответствующим названием, в котором перечислены процедуры статистического анализа данных (рисунок 2.1).
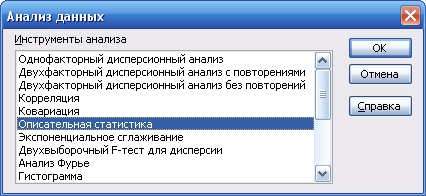
Рисунок 3.1 – Диалоговое окно процедуры Описательная статистика
Для того, чтобы запустить в работу нужную статистическую процедуру, нужно выделить ее указателем мыши и щелкнуть на кнопке ОК. На экране появится диалоговое окно вызванной процедуры. На рисунке 3.2 для примера показано диалоговое окно процедуры Описательная статистика (Descriptive statistics).
Диалоговое окно каждой процедуры содержит элементы управления: поля ввода, раскрывающиеся списки, переключатели, флажки и т. п. Эти элементы позволяют задать нужные параметры используемой процедуры. Некоторые элементы управления имеют специфический характер, присущий одной процедуре или небольшой группе процедур.
К числу общих для большинства процедур элементов управления относятся:
• поле ввода Входной интервал (Input Range). В это поле вводится ссылка на диапазон, содержащий статистические данные, подлежащие обработке. Входной диапазон может быть столбцом или группой столбцов (строкой или группой строк);
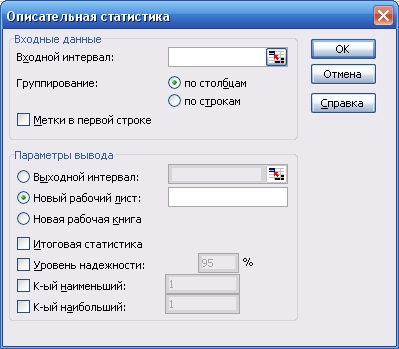
Рисунок 3.2 – Диалоговое окно процедуры Описательная статистика
• переключатель Группирование (Grouped By). В том случае, когда входной диапазон представляет собой столбец или группу столбцов, переключатель устанавливается в положение по столбцам (Columns). Если же входной диапазон представляет собой строку или группу строк, то переключатель устанавливается в положение по строкам (Rows). Более точным названием этого переключателя было бы название Расположение;
• флажок Метки (Labels in First Row). Флажок устанавливается в тех случаях, когда первая строка (первый столбец) входного диапазона содержит заголовки. Если такие заголовки отсутствуют, флажок Метки не устанавливают. При этом Excel автоматически создает и выводит на экран стандартные названия для данных выходного диапазона (Столбец 1., Столбец 2,... или Строка 1., Строка 2,...);
• переключатели Выходной интервал/Новый рабочий лист/Новая книга (Output Range/New Worksheet/New Workbook). Эти переключатели определяют место вывода таблицы, содержащей результаты реализации статистической процедуры. В группе может быть выбран только один переключатель.
При выборе переключателя Выходной интервал таблица результатов решения выводится на тот же рабочий лист, на котором находятся исходные данные. Справа от переключателя открывается поле ввода, в которое надо ввести ссылку на левую верхнюю ячейку таблицы результатов.
В положении Новый рабочий лист открывается новый лист рабочей книги. На этот лист, начиная с ячейки A1, и выводится таблица результатов решения. Справа от переключателя имеется поле ввода, в которое в случае необходимости можно ввести имя нового рабочего листа.
Следует заметить, что результаты, получаемые с помощью статистических процедур Пакета анализа, не имеют постоянной связи с исходными данными — в случае изменения исходных данных результаты решения автоматически не изменяются. В том случае, когда необходимо получить результаты, автоматически изменяющиеся вместе с исходными данными, нужно использовать подходящие статистические функции библиотеки встроенных функций.
После вычисления выборочных характеристик необходимо рассчитать коэффициент вариации наработки на отказ равный отношению стандартного отклонения к математическому ожиданию (среднему значению наработки на отказ) по формуле:
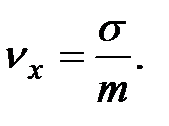 (3.2)
(3.2)
Затем необходимо рассчитать периодичность технического обслуживания по формуле 3.1.
3.2.2 Определение периодичности ТО экономико–вероятностным методом
Экономико–вероятностный метод предусматривает проведение технического обслуживания с периодичностью 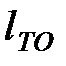 при которой суммарные удельные затраты на проведение ТО и ТР будут минимальными. При этом удельные затраты определяются как отношение средневзвешенной по вероятности стоимости соответствующей операции к средневзвешенной наработке:
при которой суммарные удельные затраты на проведение ТО и ТР будут минимальными. При этом удельные затраты определяются как отношение средневзвешенной по вероятности стоимости соответствующей операции к средневзвешенной наработке:
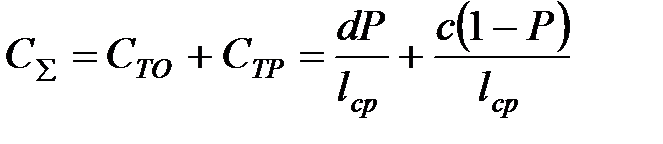 , (3.3)
, (3.3)
где 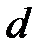 - затраты на операции ТО;
- затраты на операции ТО;
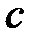 - затраты на операции ТР;
- затраты на операции ТР;
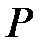 - вероятность безотказной работы при пробеге .
- вероятность безотказной работы при пробеге .
Величина средневзвешенной наработки 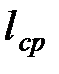 может быть определена:
может быть определена:
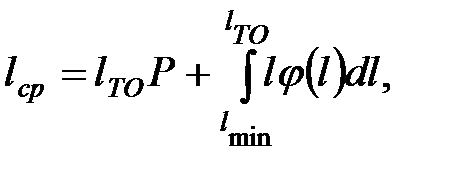 (3.4)
(3.4)
где 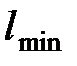 - минимальная наработка на отказ по выборке;
- минимальная наработка на отказ по выборке;
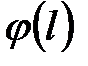 - дифференциальная функция распределения отказов.
- дифференциальная функция распределения отказов.
Для определения периодичности ТО, используя данный метод, необходимо провести статистическую обработку исходных данных, используя методику, рассмотренную н лабораторных работах по курсу "Основы теории надежности" /1/. Методика приведена в приложении А.
Для этого необходимо:
– для заданной выборки наработки на отказ рассчитать основные статистические характеристики: выборочное среднее, выборочную дисперсию, выборочное среднее квадратическое отклонение, наименьшее и наибольшее значения, размах выборки, асимметрию, эксцесс, коэффициент вариации;
– данные для случайной величины наработка на отказ разбить на 10 групп и сформировать статистический ряд, содержащий границы и середины частичных интервалов, а также соответствующие частоты; вычислить относительные, накопленные и накопленные относительные частоты;
– для случайной величины построить полигон и кумуляту частот, построить гистограмму по плотностям относительных частот;
–установить ее соответствие заданным законам распределения, используя критерий 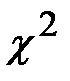 ;
;
– с помощью критерия выполнить проверку справедливости гипотезы о соответствии статистических данных выбранным распределениям, уровень значимости при подборе подходящего распределения принять равным 0,05.
Для того, чтобы определить оптимальную периодичность обслуживания, необходимо, изменяя в достаточно широких пределах величину , произвести вычисления по формулам (3.3) и (3.4) до достижения минимального значения 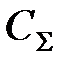 .
.
В рамках выполнения данной лабораторной работы определение производится на ЭВМ, используя специально разработанную программу. При этом результаты расчета заносятся в таблицу 3.2. Затем результаты расчета представляются в виде графика, отражающего зависимости:

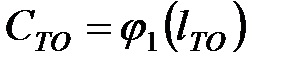 ,
, 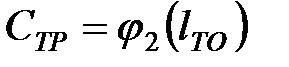 ,
, 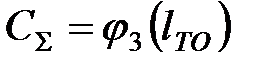 .
.
Таблица 3.2 – Определение оптимальной периодичности ТО экономико – вероятностным методом
|
| 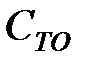
| 
| 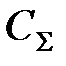
|
| 1 | 2 | 3 | 4 |
Определить оптимальную периодичность технического обслуживания, используя коэффициент оптимальной периодичности:
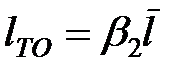 , (3.5)
, (3.5)
где 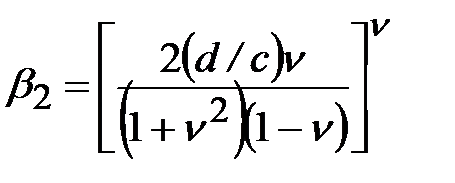 .
.
В формуле (3.5) величина 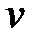 представляет собой коэффициент вариации наработки на отказ.
представляет собой коэффициент вариации наработки на отказ.
После проведения расчетов и определения периодичности ТО с использованием различных методов провести сравнение полученных значений и сделать выводы.
4 Содержание отчета
1 Наименование и цель работы.
2 Основные определения и расчетные формулы.
3 Исходные данные и результаты вычислений (таблицы, графики).
4 Выводы и заключение.
Контрольные вопросы
1 Какой из методов учитывает технические и экономические характеристики объектов, для которых определяется периодичность ТО?
2 Что означает понятие «упорядочение данных»?
3 Что означает понятие «группировка данных»?
Список литературы
1 Методические указания к выполнению лабораторных работ по дисциплине: «Основы теории надежности» для студентов направления 190600.62. – Курган: Изд–во Курганского гос. ун–та, 2013. –15 с.
2 Шарыпов А.В., Осипов Г.В. Основы теории надежности транспортных систем: Учебное пособие. – Курган: Изд–во Курганского гос. ун–та, 2006. –128–с.
3 Половко А.М.,Гуров С.В. Основы теории надежности. – СПб.: БХВ-Петербург, 2006. – 704 с.
4 Половко А.М.,Гуров С.В. Основы теории надежности. Практикум. – СПб.: БХВ-Петербург, 2006. – 560 с.
Приложение А
(информационное)
1 Статистическая обработка данных
1.1 Вычисление основных характеристик выборки
Основными числовыми характеристиками выборочной совокупности являются: выборочное среднее, выборочная дисперсия, выборочное среднее квадратическое (или стандартное) отклонение, наименьшее и наибольшее значения, размах выборки, асимметрия, эксцесс.
Для расчета указанных характеристик в Excel необходимо поставить курсор в ячейку, в которую будет записано значение характеристики, вызвать соответствующую функцию и в качестве ее аргумента указать блок ячеек со статистическими данными.
Для удобства следующих операций значения случайной величины Z (статистические данные) перепишем на другой лист в прямоугольный блок ячеек, например в ячейки Al: J10.
Значения вычисляемых характеристик будем располагать в ячейках с G12 по G19, как показано в таблице 4.3.
Вычисление выборочных характеристик осуществляется по формулам:
– выборочное среднее: G12 = СРЗНАЧ (А1: J10);
– выборочная дисперсия: G13 = ДИСП (Al: J10);
– выборочное среднее квадратическое отклонение:
G14 = СТАНДОТКЛОН(Al: J10) ИЛИ G14 = КОРЕНЬ(G13);
– наименьшее значение: G15 = МИН(А1: J10);
– наибольшее значение: G16 = МАКС (Al: J10);
– размах выборки: G17 = G16 – G15;
– асимметрия: G18 = СКОС (Al: J10);
– эксцесс: G19 = ЭКСЦЕСС(Al: J10).
Таблица 1.1 – Расчет выборочных характеристик
| А | В | С | D | Е | F | G | Н | I | J | |||
| 1 | 17,68 | 29,19 | 17,75 | 34,38 | 6,29 | 4,98 | 5,70 | 3,44 | 21,96 | 17,51 | ||
| 2 | 38,68 | 9,52 | 16,03 | 9,53 | 27,22 | 15,66 | 19,10 | 13,64 | 25,46 | 5,91 | ||
| 3 | 2,87 | 6,58 | 4,86 | 8,98 | 8,53 | 24,33 | 19,38 | 39,52 | 41,72 | 27,54 | ||
| 4 | 28,55 | 14,08 | 4,53 | 16,62 | 27,99 П | 30,43 | 7,87 | 18,60 | 9,58 | 2,58 | ||
| 5 | 4,86 | 28,76 | 2,61 | 26,79 | 43,88 | 17,28 | 19,70 | 20,41 | 15,08 | 20,05 | ||
| 6 | 12,84 | 17,23 | 84,86 | 15,76 | 56,95 | 5,46 | 16,34 | 25,38 | 35,96 | 9,76 | ||
| 7 | 33,74 | 16,93 | 8,92 | 58,53 | 4,52 | 20,64 | 9,94 | 27,92 | 12,78 | 35,14 | ||
| 8 | 13.24 | 14,71 | 4,64 | 5,90 | 28,99 | 43,44 | 53,56 | 23,23 | 24,53 | 15,20 | ||
| 9 | 42,10 | 17,22 | 29,16 | 15,64 | 4,38 | 17,55 | 3,45 | 6,95 | 17,31 | 20,73 | ||
| 10 | 11,04 | 20,31 | 23,33 | 10,48 | 12,85 | 17,93 | 26,95 | 15,20 | 11,86 | 23,21 | ||
| 11 |
| |||||||||||
| 12 | Выборочное среднее | 19,79 |
| |||||||||
| 13 | Выборочная дисперсия | 190,76 |
| |||||||||
| 14 | Выборочное ср. квадр. отклонение | 13,81 |
| |||||||||
| 15 | Наименьшее значение | 2,58 |
| |||||||||
| 16 | Наибольшее значение | 84,86 |
| |||||||||
| 17 | Размах выборки | 82,28 |
| |||||||||
| 18 | Асимметрия | 1,69 |
| |||||||||
| 19 | Эксцесс | 4,62 |
| |||||||||
1.2 Формирование статистического ряда и графическое представление данных
Для наглядного представления статистических данных используется группировка. Числовая ось разбивается на интервалы, и для каждого интервала подсчитывается число элементов выборки, которые в него попали. Группировка данных производится в следующей последовательности:
– наименьшее значение округляется в меньшую сторону, а наибольшее — в большую сторону до «хороших» чисел хmin и х max;
– выбирается количество групп k, удовлетворяющее неравенству 6 < k < 20; иногда оно определяется по формуле 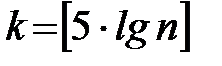 . Например, если объем выборки п= 100, то к = 10;
. Например, если объем выборки п= 100, то к = 10;
– находится шаг по формуле 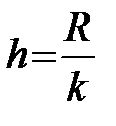 ,
,
где R = хтах – хmin — длина промежутка, в котором содержатся статистические данные;
– определяются границы частичных интервалов:
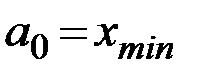 ,
, 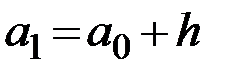 ,
, 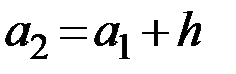 ,...
,... 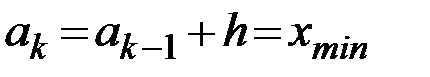 ; (1.1)
; (1.1)
– в каждом интервале вычисляются средние значения 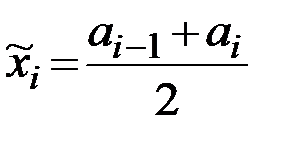 ;
;
– для каждого интервала 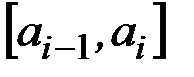 , i = 1, 2,... ,k находятся:
, i = 1, 2,... ,k находятся:
а) частоты пi, т. е. число выборочных значений, попавших в интервал;
б) относительные частоты 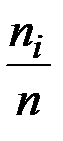 ;
;
в) накопленные частоты 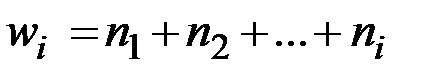 ;
;
г) накопленные относительные частоты 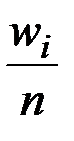 .
.
Для выборочной совокупности (таблица 1.1) результаты группировки в Excel представлены в таблице 1.2.
Сначала следует указать объем выборки, максимальное и минимальное значения, размах выборки, количество групп и шаг:
А23 = 100, В23 = 100, С23 = 0, D23 = В23 - С23, Е23 = 10, F23 = D23 / Е23.
В ячейках А25: Н25 указываются заголовки будущей таблицы. В этой таблице колонки В и С можно заполнить в соответствии с формулами (1.1) или за полнить две строки и скопировать их в последующие так, чтобы всего получилось k = 10 строк. Колонку D можно заполнить, используя формулу:
D26 = (В26 + С26) / 2
с последующим копированием в ячейки D27: D35.
Таблица 1.2 – Группировка статистических данных
| А | В | С | D | Е | F | G | Н | |
| 21 | ||||||||
| 22 | п | xmax | xmin | R | k | h | ||
| 23 | 100 | 100 | 0 | 100 | 10 | 10 | ||
| 24 | ||||||||
| 25 | Группа | Левая граница | Правая граница | Середина | Частота | Относ. частота | Накоп. частота | Накоп. относ. частота |
| 26 | 1 | 0 | 10 | 5 | 27 | 0,27 | 27 | 0,27 |
| 27 | 2 | 10 | 20 | 15 | 34 | 0,34 | 61 | 0,61 |
| 28 | 3 | 20 | 30 | 25 | 24 | 0,24 | 85 | 0,85 |
| 29 | 4 | 30 | 40 | 35 | 7 | 0,07 | 92 | 0,92 |
| 30 | 5 | 40 | 50 | 45 | 4 | 0,04 | 96 | 0,96 |
| 31 | 6 | 50 | 60 | 55 | 3 | 0,03 | 99 | 0,99 |
| 32 | 7 | 60 | 70 | 65 | 0 | 0 | 99 | 0,99 |
| 33 | 8 | 70 | 80 | 75 | 0 | 0 | 99 | 0,99 |
| 34 | 9 | 80 | 90 | 85 | 1 | 0,01 | 100 | 1 |
| 35 | 10 | 90 | 100 | 95 | 0 | 0 | 100 | 1 |
Для заполнения колонки Е следует выделить ячейки Е26: Е35 и обратиться к функции ЧАСТОТА, указав массив статистических данных и массив правых границ интервалов:
{= ЧАСТОТА(А1:J10; С26:С35)}.
Одновременное нажатие клавиш <Ctrl>+<Shift>+<Enter> приведет к заполнению выделенных ячеек.
Заполнение колонки F производится по формуле:
F26 = Е26 / $А$23
с последующим копированием в ячейки F27: F35.
Далее заполняются две ячейки колонки G по формулам:
G26 = Е26, G27 = G26 + Е27
с последующим копированием G27 в ячейки G28: G35.
Колонка Н заполняется по формуле: Н26 = G26 / $А$23
с последующим копированием в ячейки Н27: Н35.
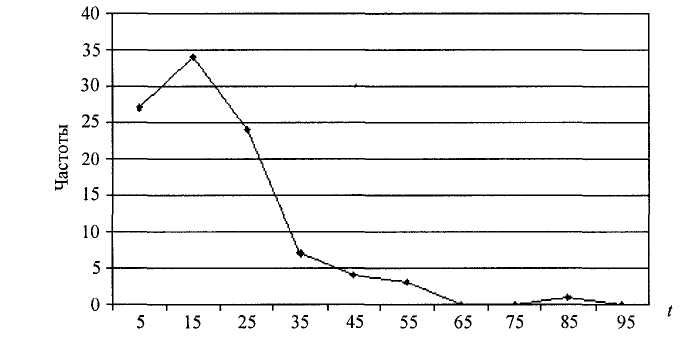
| Рисунок 1.1 – Полигон частот |
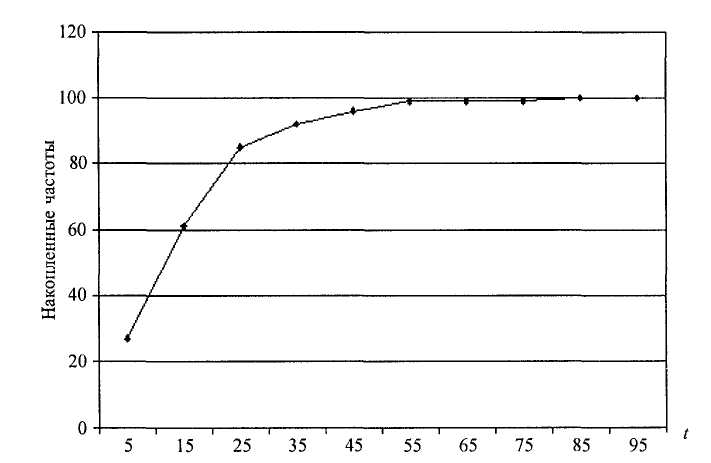
| Рисунок 1.2 – Кумулята частот |
Данные, собранные в таблице 1.2, нуждаются в наглядном представлении. Формами такого наглядного представления являются:
– полигоны частот – графическая зависимость частот (относительных частот) от середин интервалов (рисунок 1.1);
– кумуляты частот – графическая зависимость накопленных частот (накопленных относительных частот) от середин интервалов (рисунок 1.2).
4.2.3 Подбор подходящего закона распределения вероятностей
При достаточно большом объеме выборки статистические данные позволяют подобрать подходящее распределение вероятностей. С этой целью можно рассмотреть некоторые известные распределения, например равномерное, нормальное и гамма-распределение.
Предположим, что случайная величина X имеет функцию распределения F(x). Будем называть это предположение гипотезой о виде распределения случайной величины X. Чтобы иметь полную информацию о распределении случайной величины, надо знать параметры этого распределения или их некоторые оценки. Как правило, параметры распределений берутся такими, чтобы математическое ожидание случайной величины X было равно выборочной средней, а среднее квадратическое отклонение случайной величины X – выборочному среднему квадратическому отклонению. Указанные выборочные характеристики находятся в ячейках G12 и G14 соответственно.
Откроем новый лист Excel и поместим эти значения в ячейки А2 и В2 соответственно (таблица 1.3). Определим параметры равномерного, нормального и гамма-распределений в соответствии с формулами:
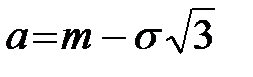 ,
, 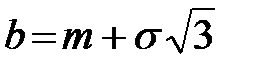 ,
, 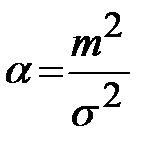 ,
, 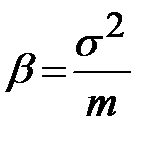
и запишем их в ячейки:
B5 = А2 – В2·КОРЕНЬ(3),
B6 = А2 + В2·КОРЕНЬ(3),
B8 = А2,
B9 = В2,
B11 = (А2/В2)^2,
B12 = В2^2/А2.
Далее построим таблицу, шапка которой располагается в ячейках А14: Е14.
В ячейках А15: А24 содержатся середины частичных интервалов, взятые из ячеек D26: D35 предыдущего листа. В ячейках В15: В24 вычислены плотности относительных частот как частное от деления относительных частот предыдущего листа (ячейки F26: F35) на шаг (ячейка $F$23).
Таблица 1.3 – Значения плотностей распределения
| А | В | С | D | Е | |
| 1 | Матем. ожидание | Сред. кв. отклон | |||
| 2 | 19,79 | 13,81 | |||
| 3 | |||||
| 4 | Параметры равномерного распределения | ||||
| 5 | а | -4,13 | |||
| 6 | b | 43,71 | |||
| 7 | Параметры нормального распределения | ||||
| 8 | т | 19,79 | |||
| 9 | σ | 13,81 | |||
| 10 | Параметры гамма - распределения | ||||
| 11 | α | 2,05 | |||
| 12 | β | 9,64 | |||
| 13 | |||||
| 14 | Середина | Плотность относит, частот | Плотность равномер. распред. | Плотность нормал распред. | Плотность гамма-распред. |
| 15 | 5 | 0,027 | 0,021 | 0,016 | 0,030 |
| 16 | 15 | 0,034 | 0,021 | 0,027 | 0,034 |
| 17 | 25 | 0,024 | 0,021 | 0,027 | 0,021 |
| 18 | 35 | 0,007 | 0,021 | 0,016 | 0,010 |
| 19 | 45 | 0,004 | 0,000 | 0,005 | 0,005 |
| 20 | 55 | 0,003 | 0,000 | 0,001 | 0,002 |
| 21 | 65 | 0,000 | 0,000 | 0,000 | 0,001 |
| 22 | 75 | 0,000 | 0,000 | 0,000 | 0,000_ |
| 23 | 85 | 0,001 | 0,000 | 0,000 | 0,000 |
| 24 | 95 | 0,000 | 0,000 | 0,000 | 0,000 |
Плотности равномерного, нормального и гамма-распределений рассчитываются в соответствии с формулами:
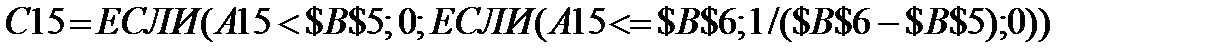 ,
,
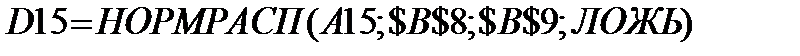 ,
,
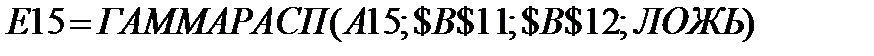 ,
,
затем они копируются в блок ячеек С16:Е24.
Построим гистограмму частот, совмещенную с плотностью каждого из указанных ранее распределений. Гистограмма частот – это графическое изображение зависимости плотности относительных частот ni / nh от соответствующего интервала группировки.
В этом случае площадь гистограммы равна единице, и гистограмма может служить аналогом плотности распределения вероятностей случайной величины X. Графическое изображение гистограммы и кривых различных распределений приведено на рисунках 1.3 – 1.5. При этом используется нестандартная диаграмма типа «График | гистограмма».
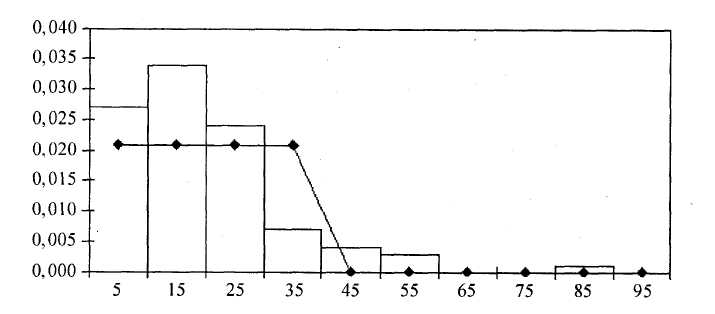
| Рисунок1.3 – Сглаживание гистограммы плотностью равномерного распределения |
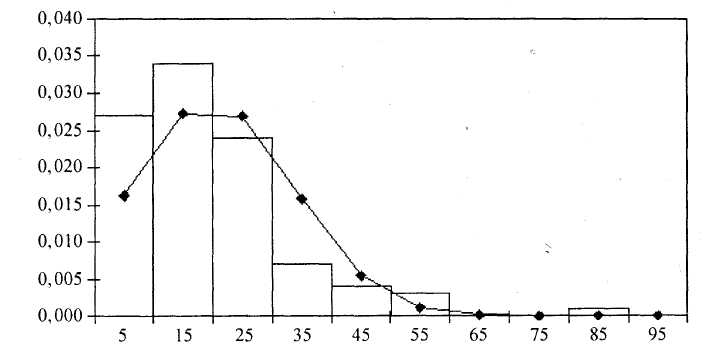
| Рисунок 1.4 – Сглаживание гистограммы плотностью нормального распределения |
По внешнему виду этих графиков вполне можно судить о соответствии кривой распределения данной гистограмме, т. е. о том, какая кривая ближе к полученной гистограмме.
Используя критерий 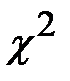 , надо установить, верна ли принятая нами гипотеза о распределении случайной величины X, т. е. о соответствии функции распределения F(x) экспериментальным данным, чтобы ошибка не превышала заданного уровня значимости
, надо установить, верна ли принятая нами гипотеза о распределении случайной величины X, т. е. о соответствии функции распределения F(x) экспериментальным данным, чтобы ошибка не превышала заданного уровня значимости 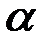 (вероятность того, что будет отвергнута правильная гипотеза).
(вероятность того, что будет отвергнута правильная гипотеза).
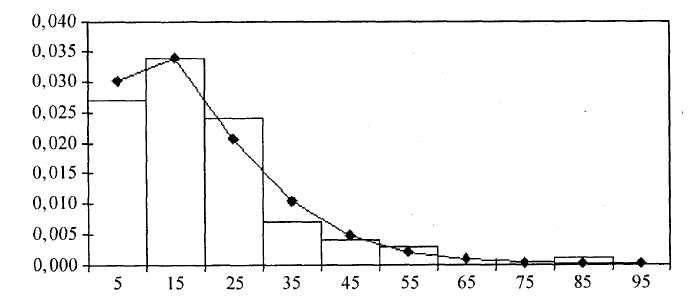
| Рисунок 1.5 – Сглаживание гистограммы плотностью гамма - распределения |
Для применения критерия 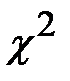 необходимо, чтобы частоты пi, соответствующие каждому интервалу, были не меньше 5. Если это не так, рядом стоящие интервалы объединяются, а их частоты суммируются. В результате общее количество интервалов может уменьшиться до значения
необходимо, чтобы частоты пi, соответствующие каждому интервалу, были не меньше 5. Если это не так, рядом стоящие интервалы объединяются, а их частоты суммируются. В результате общее количество интервалов может уменьшиться до значения 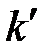 . Далее вычисляется следующая сумма:
. Далее вычисляется следующая сумма:
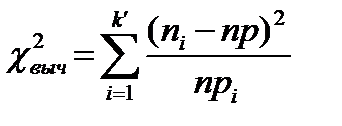 , (1.2)
, (1.2)
где рi – теоретическая вероятность того, что случайная величина X примет значение из интервала [ ai-1, аi ]. Мы предположили, что случайная величина X имеет функцию распределения F(x), поэтому pt =F(ai)-F(ai-1). Образец расчетов по формуле (1.2) в Excel для трех распределений показан в таблице 1.3.
В колонке А содержатся левые, а в колонке В – правые границы интервалов. В колонке С находятся соответствующие частоты. Заметим, что интервалы с 5-го по 10-й объединены в один, чтобы все частоты были не менее пяти. Количество интервалов вместо k = 10 стало равным k' = 5. В колонке D рассчитываются теоретические вероятности в зависимости от вида распределения. Как обычно, вычисляется одно значение, которое копируется в другие ячейки:
– для равномерного распределения:
D45 = ЕСЛИ(В45 < $В$5; 0; ЕСЛИ(В45 <= $В$6;
(В45 - $В$5)/($В$6 - $В$5); 1)) - ЕСЛИ(А45 < $В$5; 0;
ЕСЛИ(А45 <= $В$6; (А45 - $В$5)/($В$6 - $В$5); 1));
– для нормального распределения:
D52 = НОРМРАСП(В52; $В$8; $В$9; ИСТИНА) - НОРМРАСП(А52; $В$8; $В$9; ИСТИНА);
– для гамма-распределения:
D59 = ГАММАРАСП(В59; $В$11; $В$12; ИСТИНА)- ГАММАРАСП(А59; $В$11; $В$12; ИСТИНА).
Таблица 1.3 – Подбор распределения на основе критерия χ2
| А | В | С | D | Е | |
| 43 | Левая граница | Правая граница | Частота | Вероятности | χ2 |
| 44 | Равномерное распределение | ||||
| 45 | 0 | 10 | 27 | 0,209 | 1,778 |
| 46 | 10 | 20 | 34 | 0,209 | 8,206 |
| 47 | 20 | 30 | 24 | 0,209 | 0,459 |
| 48 | 30 | 40 | 7 | 0,209 | 9,247 |
| 49 | 40 | 100 | 8 | 0,078 | 0,008 |
| 50 | Сумма | 19,698 | |||
| 51 | Нормальное распределение | ||||
| 52 | 0 | 10 | 27 | 0,163 | 6,978 |
| 53 | 10 | 20 | 34 | 0,267 | 2,004 |
| 54 | 20 | 30 | 24 | 0 264 | 0,220 |
| 55 | 30 | 40 | 7 | 0,158 | 4,916 |
| 56 | 40 | 100 | 8 | 0,072 | 0,097 |
| 57 | Сумма | 14,214 | |||
| 58 | Гамма-распределение | ||||
| 59 | 0 | 10 | 27 | 0,263 | 0,017 |
| 60 | 10 | 20 | 34 | 0,335 | 0,007 |
| 61 | 20 | 30 | 24 | 0,208 | 0,477 |
| 62 | 30 | 40 | 7 | 0,106 | 1,243 |
| 63 | 40 | 100 | 8 | 0,086 | 0,045 |
| 64 | Сумма | 1,789 | |||
| 65 | |||||
| 66 | Критическое значение критерия | 5,991 | |||
В колонке Е рассчитываются слагаемые соотношения (4.2) по формуле:
Е45 = (С45 - 100·D45)^2/(100·D45), которая копируется в другие ячейки колонки Е.
Согласно формулы (4.2) для каждого рассмотренного распределения определяются итоговые суммы:
Е50 = СУММ(Е45:Е49),
Е57 = СУММ(Е52:Е5б),
Е64 = СУММ(Е59:Е63),
которые равны соответственно 19,698, 14,214 и 1,789.
Гипотеза о виде закона распределения должна быть принята, если вычисленное значение 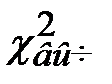 достаточно мало, а именно не превосходит критического значения
достаточно мало, а именно не превосходит критического значения 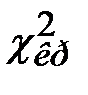 , которое определяется по распределению
, которое определяется по распределению 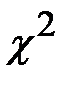 в зависимости от заданного уровня значимости
в зависимости от заданного уровня значимости 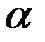 и числа степеней свободы
и числа степеней свободы 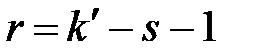 . Здесь s – число неизвестных параметров распределения, которые были определены по выборке (для равномерного, нормального и гамма-распределений s = 2). В данном примере r = k' - s -1 = 5-3 = 2. Полагая
. Здесь s – число неизвестных параметров распределения, которые были определены по выборке (для равномерного, нормального и гамма-распределений s = 2). В данном примере r = k' - s -1 = 5-3 = 2. Полагая 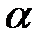 = 0,05, критическое значение критерия в Excel рассчитывается по формуле:
= 0,05, критическое значение критерия в Excel рассчитывается по формуле:
Е66 = ХИ2ОБР(0,05;2)
и, как следует из таблицы 4.6, равно 5,991.
Поскольку 1,789 < 5,991, то принимается гипотеза о том, что статистические данные имеют гамма-распределение с параметрами 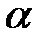 = 2,05 и
= 2,05 и 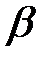 = 9,64 соответственно.
= 9,64 соответственно.
Шарыпов Александр Владимирович
Осипов Георгий Владимирович








