 2014-02-04
2014-02-04 2662
2662 |
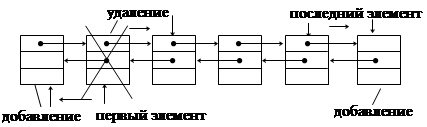 |
Рис.1.10. Организация дека с ограниченным выходом на основе двусвязанного линейного списка
Очередь с ограниченным входом или с ограниченным выходом также как дек или очередь можно организовать на основе линейного двунаправленного списка.
Разновидностями очередей являются очередь с ограниченным входом и очередь с ограниченным выходом. Они занимают промежуточное положение между деком и простой очередью.
Причем дек с ограниченным входом может быть использован как простая очередь или как стек.
2. Задачи поиска в структурах данных
Одно из наиболее часто встречающихся в программировании действий – поиск. Существует несколько основных вариантов поиска, и для них создано много различных алгоритмов. При дальнейшем рассмотрении делается принципиальное допущение: группа данных, в которой необходимо найти заданный элемент, фиксирована. Будет считаться, что множество из N элементов задано в виде такого массива
a: array[0..N–1] of Item
Обычно тип Item описывает запись с некоторым полем, играющим роль ключа. Задача заключается в поиске элемента, ключ которого равен заданному «аргументу поиска» x. Полученный в результате индекс i, удовлетворяющий условию а[i].key = x, обеспечивает доступ к другим полям обнаруженного элемента. Так как здесь рассматривается, прежде всего, сам процесс поиска, то мы будем считать, что тип Item включает только ключ.
2.1. Линейный поиск
Если нет никакой дополнительной информации о разыскиваемых данных, то очевидный подход – простой последовательный просмотр массива с увеличением шаг за шагом той его части, где желаемого элемента не обнаружено. Такой метод называется линейным поиском. Условия окончания поиска таковы:
Элемент найден, т. е. аi = x.
Весь массив просмотрен и совпадения не обнаружено.
Это дает нам линейный алгоритм:
Алгоритм 1.
i:=0;
while (i<N) and (а[i]<>х) do i:=i+1
Следует обратить внимание, что если элемент найден, то он найден вместе с минимально возможным индексом, т. е. это первый из таких элементов. Равенство i=N свидетельствует, что совпадения не существует.
Очевидно, что окончание цикла гарантировано, поскольку на каждом шаге значение i увеличивается, и, следовательно, оно достигнет за конечное число шагов предела N; фактически же, если совпадения не было, это произойдет после N шагов.
На каждом шаге алгоритма осуществляется увеличение индекса и вычисление логического выражения. Можно упростить шаг алгоритма, если упростить логическое выражение, которое состоит из двух членов. Это упрощение осуществляется путем формулирования логического выражения из одного члена, но при этом необходимо гарантировать, что совпадение произойдет всегда. Для этого достаточно в конец массива поместить дополнительный элемент со значением x. Такой вспомогательный элемент называется «барьером». Теперь массив будет описан так:
а: array[0..N] of integer
и алгоритм линейного поиска с барьером выглядит следующим образом:
Алгоритм 1’.
a[N]:=x; i:=0;
while a[i]<>x do i:=i+1
Ясно, что равенство i=N свидетельствует о том, что совпадения (если не считать совпадения с барьером) не было.
2.2. Поиск делением пополам (двоичный поиск)
Совершенно очевидно, что других способов убыстрения поиска не существует, если, конечно, нет еще какой-либо информации о данных, среди которых идет поиск. Хорошо известно, что поиск можно сделать значительно более эффективным, если данные будут упорядочены. Поэтому приведем алгоритм (он называется «поиском делением пополам»), основанный на знании того, что массив A упорядочен, т. е. удовлетворяет условию
ak-1 £ ak, где 1 £ k < N
Основная идея – выбрать случайно некоторый элемент, предположим am, и сравнить его с аргументом поиска x. Если он равен x, то поиск заканчивается, если он меньше x, то делается вывод, что все элементы с индексами, меньшими или равными m, можно исключить из дальнейшего поиска; если же он больше x, то исключаются индексы больше и равные m. Выбор m совершенно не влияет на корректность алгоритма, но влияет на его эффективность. Очевидно, что чем большее количество элементов исключается на каждом шаге алгоритма, тем этот алгоритм эффективнее. Оптимальным решением будет выбор среднего элемента, так как при этом в любом случае будет исключаться половина массива.
 | |||
 | |||
Рис.2.1. Поиск делением пополам
В этом алгоритме используются две индексные переменные L и R, которые отмечают соответственно левый и правый конец секции массива a, где еще может быть обнаружен требуемый элемент.
Алгоритм 2.
L:=0; R:=N-1; Found:=false;
while(L<=R) and not Found do begin
m:=(L+R) div 2;
if a[m]=x then begin
Found:=true
end else begin
if a[m]<x then L:=m+1 else R:=m-1
end
end
Максимальное число сравнений для этого алгоритма равно log2n, округленному до ближайшего целого. Таким образом, приведенный алгоритм существенно выигрывает по сравнению с линейным поиском, ведь там ожидаемое число сравнений – N/2.
Эффективность несколько улучшается, если поменять местами заголовки условных операторов. Проверку на равенство можно выполнять во вторую очередь, так как она встречается лишь единожды и приводит к окончанию работы. Но более существенный выигрыш даст отказ от окончания поиска при фиксации совпадения. На первый взгляд это кажется странным, однако, при внимательном рассмотрении обнаруживается, что выигрыш в эффективности на каждом шаге превосходит потери от сравнения с несколькими дополнительными элементами (число шагов в худшем случае равно logN).
Алгоритм 2’.
L:=0; R:=N;
while L<R do begin
m:=(L+R) div 2;
if а[m]<x then L:=m+1 else R:=m
end
Окончание цикла гарантировано. Это объясняется следующим. В начале каждого шага L<R. Для среднего арифметического m справедливо условие L £ m < R. Следовательно, разность L-R действительно убывает, ведь либо L увеличивается при присваивании ему значения m+1, либо R уменьшается при присваивании значения m. При L ³ R повторение цикла заканчивается.
Выполнение условия L=R еще не свидетельствует о нахождении требуемого элемента. Здесь требуется дополнительная проверка. Также, необходимо учитывать, что элемент a[R] в сравнениях никогда не участвует. Следовательно, и здесь необходима дополнительная проверка на равенство a[R]=x. Следует отметить, что эти проверки выполняются однократно.
Приведенный алгоритм, как и в случае линейного поиска, находит совпадающий элемент с наименьшим индексом.
2.3. Поиск в таблице
Поиск в массиве иногда называют поиском в таблице, особенно если ключ сам является составным объектом, таким, как массив чисел или символов. Часто встречается именно последний случай, когда массивы символов называют строками или словами. Строковый тип определяется так:
String = array[0..М–1] of char
соответственно определяется и отношение порядка для строк x и y:
x = y, если xj = yj для 0 £ j < M
x < y, если xi < yi для 0 £ i < M и xj = yj для 0 £ j < i
Для того чтобы установить факт совпадения, необходимо установить, что все символы сравниваемых строк соответственно равны один другому. Поэтому сравнение составных операндов сводится к поиску их несовпадающих частей, т. е. к поиску «на неравенство». Если неравных частей не существует, то можно говорить о равенстве. Предположим, что размер слов достаточно мал, скажем, меньше 30. В этом случае можно использовать линейный поиск и поступать таким образом.
Для большинства практических приложений желательно исходить из того, что строки имеют переменный размер. Это предполагает, что размер указывается в каждой отдельной строке. Если исходить из ранее описанного типа, то размер не должен превосходить максимального размера M. Такая схема достаточно гибка и подходит для многих случаев, в то же время она позволяет избежать сложностей динамического распределения памяти. Чаще всего используются два таких представления размера строк:
Размер неявно указывается путем добавления концевого символа, больше этот символ нигде не употребляется. Обычно для этой цели используется «непечатаемый» символ со значением 00h. (Для дальнейшего важно, что это минимальный символ из всего множества символов.)
Размер явно хранится в качестве первого элемента массива, т. е. строка s имеет следующий вид: s = s0, s1, s2,..., sM-1. Здесь s1,..., sM-1 – фактические символы строки, а s0 = Chr(M). Такой прием имеет то преимущество, что размер явно доступен, недостаток же в том, что этот размер ограничен размером множества символов (256).
В последующем алгоритме поиска отдается предпочтение первой схеме. В этом случае сравнение строк выполняется так:
i:=0;
while (x[i]=y[i]) and (x[i]<>00h) do i:=i+1
Концевой символ работает здесь как барьер.
Теперь вернемся к задаче поиска в таблице. Он требует «вложенных» поисков, а именно: поиска по строчкам таблицы, а для каждой строчки последовательных сравнений – между компонентами. Например, пусть таблица T и аргумент поиска x определяются таким образом:
T: array[0..N-1] of String;
x: String
Допустим, N достаточно велико, а таблица упорядочена в алфавитном порядке. При использовании алгоритма поиска делением пополам и алгоритма сравнения строк, речь о которых шла выше, получаем такой фрагмент программы:
L:=0; R:=N;
while L<R do begin
m:=(L+R) div 2; i:=0;
while (T[m,i]=x[i]) and (x[i]<>00h) do i:=i+1;
if T[m,i]<x[i] then L:=m+1 else R:=m
end;
if R<N then begin
i:=0;
while (T[R,i]=х[i]) and (х[i]<>00h) do i:=i+1
end
{(R<N) and (T[R,i]=x[i]) фиксирует совпадение}
2.3.1. Прямой поиск строки
Часто приходится сталкиваться со специфическим поиском, так называемым поиском строки. Его можно определить следующим образом. Пусть задан массив s из N элементов и массив p из M элементов, причем 0 < M £ N. Описаны они так:
s: array[0..N–1] of Item
р: array[0..M–1] of Item
Поиск строки обнаруживает первое вхождение p в s. Обычно Item – это символы, т.е. s можно считать некоторым текстом, а p – словом, и необходимо найти первое вхождение этого слова в указанном тексте. Это действие типично для любых систем обработки текстов, отсюда и очевидная заинтересованность в поиске эффективного алгоритма для этой задачи. Разберем алгоритм поиска, который будем называть прямым поиском строки.
Алгоритм 3.
i:=-1;
repeat
i:=i+1; j:=0;
while (j<M) and (s[i+j]=p[j]) do j:=j+1;
until (j=M) or (i=N-M)
Вложенный цикл с предусловием начинает выполняться тогда, когда первый символ слова p совпадает с очередным, i-м, символом текста s. Этот цикл повторяется столько раз, сколько совпадает символов текста s, начиная с i-го символа, с символами слова p (максимальное количество повторений равно M). Цикл завершается при исчерпании символов слова p (перестает выполняться условие j<M) или при несовпадении очередных символов s и p (перестает выполняться условие s[i+j]=p[j]). Количество совпадений подсчитывается с использованием j. Если совпадение произошло со всеми символами слова p (т.е. слово p найдено), то выполняется условие j=M, и алгоритм завершается. В противном случае поиск продолжается до тех пор, пока не просмотренной останется часть текста s, которая содержит символов, меньше, чем есть в слове p (т.е. этот остаток уже не может совпасть со словом p). В этом случае выполняется условие i=N-M, что тоже приводит к завершению алгоритма. Это показывает гарантированность окончания алгоритма.
Этот алгоритм работает достаточно эффективно, если допустить, что несовпадение пары символов происходит после незначительного количества сравнений во внутреннем цикле. При большой мощности типа Item это достаточно частый случай. Можно предполагать, что для текстов, составленных из 128 символов, несовпадение будет обнаруживаться после одной или двух проверок. Тем не менее, в худшем случае производительность будет внушать опасение.
2.3.2. Алгоритм Кнута, Мориса и Пратта
Приблизительно в 1970 г. Д. Кнут, Д. Морис и В. Пратт изобрели алгоритм, фактически требующий только N сравнений даже в самом плохом случае. Новый алгоритм основывается на том соображении, что после частичного совпадения начальной части слова с соответствующими символами текста фактически известна пройденная часть текста и можно «вычислить» некоторые сведения (на основе самого слова), с помощью которых потом можно быстро продвинуться по тексту. Приведенный пример поиска слова ABCABD показывает принцип работы такого алгоритма. Символы, подвергшиеся сравнению, здесь подчеркнуты. Обратите внимание: при каждом несовпадении пары символов слово сдвигается на все пройденное расстояние, поскольку меньшие сдвиги не могут привести к полному совпадению.
ABCABCABAABCABD
ABCABD
A BCABD
ABC ABD
AB CABD
ABCABD
Основным отличием КМП-алгоритма от алгоритма прямого поиска является осуществления сдвига слова не на один символ на каждом шаге алгоритма, а на некоторое переменное количество символов. Таким образом, перед тем как осуществлять очередной сдвиг, необходимо определить величину сдвига. Для повышения эффективности алгоритма необходимо, чтобы сдвиг на каждом шаге был бы как можно большим.
Если j определяет позицию в слове, содержащую первый несовпадающий символ (как в алгоритме прямого поиска), то величина сдвига определяется как j-D. Значение D определяется как размер самой длинной последовательности символов слова, непосредственно предшествующих позиции j, которая полностью совпадает с началом слова. D зависит только от слова и не зависит от текста. Для каждого j будет своя величина D, которую обозначим dj.
Так как величины dj зависят только от слова, то перед началом фактического поиска можно вычислить вспомогательную таблицу d; эти вычисления сводятся к некоторой предтрансляции слова. Соответствующие усилия будут оправданными, если размер текста значительно превышает размер слова (M<<N). Если нужно искать многие вхождения одного и того же слова, то можно пользоваться одними и теми же d. Приведенные примеры объясняют функцию d.
Последний пример на рис. 2.2 показывает: так как pj равно A вместо F, то соответствующий символ текста не может быть символом A из-за того, что условие si<>pj заканчивает цикл. Следовательно, сдвиг на 5 не приведет к последующему совпадению, и поэтому можно увеличить размер сдвига до шести. Учитывая это, предопределяем вычисление dj как поиск самой длинной совпадающей последовательности с дополнительным ограничением pdj<>pj. Если никаких совпадений нет,

Рис. 2.2. Частичное совпадение со словом и вычисление dj.
то считается dj=-1, что указывает на сдвиг «на целое» слово относительно его текущей позиции. Следующая программа демонстрирует КМП-алгоритм.
Program KMP;
const
Mmax = 100; Nmax = 10000;
var
i, j, k, M, N: integer;
p: array[0..Mmax-1] of char; {слово}
s: array[0..Mmax-1] of char; {текст}
d: array[0..Mmax-1] of integer;
begin
{Ввод текста s и слова p}
Write('N:'); Readln(N);
Write('s:'); Readln(s);
Write('M:'); Readln(M);
Write('p:'); Readln(p);
{Заполнение массива d}
j:=0; k:=-1; d[0]:=-1;
while j<(M-1) do begin
while(k>=0) and (p[j]<>p[k]) do k:=d[k];
j:=j+1; k:=k+1;
if p[j]=p[k] then
d[j]:=d[k]
else
d[j]:=k;
end;
{Поиск слова p в тексте s}
i:=0; j:=0;
while (j<M) and (i<N) do begin
while (j>=0) and
(s[i]<>p[j]) do j:=d[j]; {Сдвиг слова}
i:=i+1; j:=j+1;
end;
{Вывод результата поиска}
if j=M then Writeln('Yes') {найден }
else Writeln('No'); {не найден}
Readln;
end.
Точный анализ КМП-поиска, как и сам его алгоритм, весьма сложен. Его изобретатели доказывают, что требуется порядка M+N сравнений символов, что значительно лучше, чем M*N сравнений из прямого поиска. Они так же отмечают то положительное свойство, что указатель сканирования i никогда не возвращается назад, в то время как при прямом поиске после несовпадения просмотр всегда начинается с первого символа слова и поэтому может включать символы, которые ранее уже просматривались. Это может привести к негативным последствиям, если текст читается из вторичной памяти, ведь в этом случае возврат обходится дорого. Даже при буферизованном вводе может встретиться столь большое слово, что возврат превысит емкость буфера.
2.3.3. Алгоритм Боуера и Мура
КМП-поиск дает подлинный выигрыш только тогда, когда неудаче предшествовало некоторое число совпадений. Лишь в этом случае слово сдвигается более чем на единицу. К несчастью, это скорее исключение, чем правило: совпадения встречаются значительно реже, чем несовпадения. Поэтому выигрыш от использования КМП-стратегии в большинстве случаев поиска в обычных текстах весьма незначителен. Метод же, предложенный Р. Боуером и Д. Муром в 1975 г., не только улучшает обработку самого плохого случая, но дает выигрыш в промежуточных ситуациях.
БМ-поиск основывается на необычном соображении – сравнение символов начинается с конца слова, а не с начала. Как и в случае КМП-поиска, слово перед фактическим поиском трансформируется в некоторую таблицу. Пусть для каждого символа x из алфавита величина dx – расстояние от самого правого в слове вхождения x до правого конца слова. Представим себе, что обнаружено расхождение между словом и текстом. В этом случае слово сразу же можно сдвинуть вправо на dpM-1 позиций, т.е. на число позиций, скорее всего большее единицы. Если несовпадающий символ текста в слове вообще не встречается, то сдвиг становится даже больше, а именно сдвигать можно на длину всего слова. Вот пример, иллюстрирующий этот процесс:
ABCABCABFABCABD
ABCAB D {Не совпало с ‘C’, d[‘C’]=3}
ABCAB D {Не совпало с F, ‘F’ нет в слове}
ABCABD {Полное совпадение, слово найдено}
Ниже приводится программа с упрощенной стратегией Боуера-Мура, построенная так же, как и предыдущая программа с КМП-алгоритмом. Обратите внимание на такую деталь: во внутреннем цикле используется цикл с repeat, где перед сравнением s и p увеличиваются значения k и j. Это позволяет исключить в индексных выражениях составляющую -1.
Program BM;
const
Mmax = 100; Nmax = 10000;
var
i, j, k, M, N: integer;
ch: char;
p: array[0..Mmax-1] of char; {слово}
s: array[0..Nmax-1] of char; {текст}
d: array[' '..'z'] of integer;
begin
{Ввод текста s и слова p}
Write('N:'); Readln(N);
Write('s:'); Readln(s);
Write('M:'); Readln(M);
Write('p:'); Readln(p);
{Заполнение массива d}
for ch:=' ' to 'z' do d[ch]:=M;
for j:=0 to M-2 do d[p[j]]:=M-j-1;
{Поиск слова p в тексте s}
i:=M;
repeat
j:=M; k:=i;
repeat {Цикл сравнения символов }
k:=k-1; j:=j-1; {слова, начиная с правого.}
until (j<0) or (p[j]<>s[k]); {Выход, если сравнили все}
{слово или несовпадение. }
i:=i+d[s[i-1]]; {Сдвиг слова вправо }
until (j<0) or (i>N);
{Вывод результата поиска}
if j<0 then Writeln('Yes') {найден }
else Writeln('No'); {не найден}
Readln;
end.
Почти всегда, кроме специально построенных примеров, данный алгоритм требует значительно меньше N сравнений. В самых же благоприятных обстоятельствах, когда последний символ слова всегда попадает на несовпадающий символ текста, число сравнений равно N/M.
Авторы алгоритма приводят и несколько соображений по поводу дальнейших усовершенствований алгоритма. Одно из них – объединить приведенную только что стратегию, обеспечивающую большие сдвиги в случае несовпадения, со стратегией Кнута, Морриса и Пратта, допускающей «ощутимые» сдвиги при обнаружении совпадения (частичного). Такой метод требует двух таблиц, получаемых при предтрансляции: d1 – только что упомянутая таблица, а d2 – таблица, соответствующая КМП-алгоритму. Из двух сдвигов выбирается больший, причем и тот и другой «говорят», что никакой меньший сдвиг не может привести к совпадению. Дальнейшее обсуждение этого предмета приводить не будем, поскольку дополнительное усложнение формирования таблиц и самого поиска, кажется, не оправдывает видимого выигрыша в производительности. Фактические дополнительные расходы будут высокими и неизвестно, приведут ли все эти ухищрения к выигрышу или проигрышу.
3. Методы ускорения доступа к данным
3.1. Хеширование данных
Для ускорения доступа к данным в таблицах можно использовать предварительное упорядочивание таблицы в соответствии со значениями ключей.
При этом могут быть использованы методы поиска в упорядоченных структурах данных, например, метод половинного деления, что существенно сокращает время поиска данных по значению ключа. Однако при добавлении новой записи требуется переупорядочить таблицу. Потери времени на повторное упорядочивание таблицы могут значительно превышать выигрыш от сокращения времени поиска. Поэтому для сокращения времени доступа к данным в таблицах используется так называемое случайное упорядочивание или хеширование. При этом данные организуются в виде таблицы при помощи хеш-функции h, используемой для «вычисления» адреса по значению ключа.
адрес = h (ключ)
 таблица (файл базы данных)
таблица (файл базы данных)
| Ключ | поле данных | |
  |

поля (имеют фиксированный тип)
Рис.3.1. Хеш-таблица
Идеальной хеш-функцией является такая hash-функция, которая для любых двух неодинаковых ключей дает неодинаковые адреса.
k1 ¹ k2 Þ h(k1) ¹ h(k2)
Подобрать такую функцию можно в случае, если все возможные значения ключей заранее известны. Такая организация данных носит название “совершенное хеширование“. В случае заранее неопределенного множества значений ключей и ограниченной длины таблицы подбор совершенной функции затруднителен. Поэтому часто используют хеш-функции, которые не гарантируют выполнение условия.
Рассмотрим пример реализации несовершенной хеш-функции на языке TurboPascal. Предположим, что ключ состоит из четырех символов. При этом таблица имеет диапазон адресов от 0 до 10000.
function hash (key: string[4]): integer;
var
f: longint;
begin
f:=ord (key[1]) - ord (key[2]) + ord (key[3]) -ord (key[4]);
{вычисление функции по значению ключа}
f:=f+255*2;
{совмещение начала области значений функции с начальным
адресом хеш-таблицы (a=1)}
f:=(f*10000) div (255*4);
{совмещение конца области значений функции с конечным адресом
хеш-таблицы (a=10 000)}
hash:=f
end;
При заполнении таблицы возникают ситуации, когда для двух неодинаковых ключей функция вычисляет один и тот же адрес. Данный случай носит название “коллизия”, а такие ключи называются “ключи-синонимы”.
3.1.1. Методы разрешения коллизий
Для разрешения коллизий используются различные методы, которые в основном сводятся к методам “цепочек“ и “открытой адресации“.
Методом цепочек называется метод, в котором для разрешения коллизий во все записи вводятся указатели, используемые для организации списков – “цепочек переполнения”. В случае возникновения коллизии при заполнении таблицы в список для требуемого адреса хеш-таблицы добавляется еще один элемент.
Поиск в хеш-таблице с цепочками переполнения осуществляется следующим образом. Сначала вычисляется адрес по значению ключа. Затем осуществляется последовательный поиск в списке, связанном с вычисленным адресом.
Процедура удаления из таблицы сводится к поиску элемента и его удалению из цепочки переполнения.

