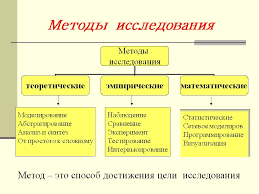
2014-02-02
2014-02-02 420
420В принципе запрос на информацию можно было бы сравнить с содержимым файлов и выявить наилучшее соответствие. На практике, однако, содержание как запроса, так и элементов хранимой информации надо сначала определить более четко. Таким образом, в управлении базой данных содержание каждой записи оценивается согласно некоторому масштабу значений; в системе поиска ссылки документ представляется набором терминов, каждый из которых имеет значение (вес), зависящее от важности термина в документе.
Процесс накопления и поиска информации состоит из некоторого вида индексации, записи в файл, формулирования запроса и операций просмотра и выборки, выполняемых над хранимыми записями при ответе на запрос об информации.
Индексация. Обычно индексация осуществляется вручную. Индекс (предметный указатель, словарь) может содержать много терминов, взятых из естественного языка, или может быть ограничен некоторыми специальными терминами. Словарь специальных терминов может определять термины с более широкими границами применимости, чем некоторый заданный термин, а также более узкие термины, синонимы и т.д. Документу назначается от 6 до 20 терминов. Ручная индексация представляет собой своего рода искусство, и не следует ожидать какой-либо согласованности между результатами действий отдельных индексаторов.
Были разработаны разнообразные методы автоматической индексации. В простейшем случае для индексации используется каждое слово отрывка из документа, за исключением союзов и предлогов. В более сложных системах выбираются термины, и им назначается вес по частоте появления в отдельных документах: чем выше частота появления данного слова, тем больше назначаемый ему вес. Слова, часто появляющиеся на протяжении всего собрания данных, не представляются подходящими для индексации, поскольку при осуществлении поиска они могут создать ложное представление относительно предпочтительности одних элементов перед другими. В случае автоматической индексации содержание документа может быть представлено не более чем сотней терминов.
Формулирование запроса. В запросах должны использоваться термины, имеющие вероятность совпасть с терминами-индексами, назначенными отыскиваемому документу. Формулировки запросов зачастую сложны. Так, запрос «А и В» означает, что должны отыскиваться документы, содержащие как термин А, так и термин В; запрос «А или В» относится к документам, содержащим либо термин А, либо термин В. В обычных системах поиска отыскиваются только те документы, в которых термины точно совпадают с терминами соответствующего запроса. В более совершенных системах формулировки запросов автоматически конструируются из формулировок, предъявляемых пользователем на естественном языке. Затем эти формулировки используются для идентификации документов на основе сходства терминов.
Организация и поиск файлов. Последовательный просмотр, при котором запрос сравнивается с каждым хранимым элементом по очереди, является неприемлемо медленным, исключая случай малых файлов. Если бы файл состоял из терминов в алфавитном порядке, по одному на элемент, его можно было бы использовать как телефонную книгу, и поиск был бы быстрым. Когда каждому документу назначается много поисковых терминов, документы можно разбить на группы сходных терминов. Этот способ известен как кластерная организация файла. Затем каждой группе, или кластеру, может быть присвоена метка, и термины запроса сравниваются только с подходящей меткой.
Быстрый поиск можно осуществить путем использования справочных файлов, которые содержат список идентификаторов документов для каждого термина-индекса. Тогда выполняется просмотр справочных файлов на предмет обнаружения идентификаторов, соответствующих данному термину. Например, списки идентификаторов документов для терминов-индексов «ЯБЛОНЯ» и «ГРУША» могли бы выглядеть как
ЯБЛОНЯ: 23,25,27,31,38
ГРУША: 22,25,26,31
В ответ на запрос «ЯБЛОНЯ и ГРУША» были бы выданы документы 25 и 31, а на запрос «ЯБЛОНЯ или ГРУША» – документы 22, 23, 25, 26, 27, 31 и 38. Существует несколько методов для сравнения и слияния списков в файле этого типа, который известен как инвертированный файл.
Многие поисковые системы предлагают процедуры переформулировки запроса после первоначальной операции поиска. Переформулированный запрос включает некоторые релевантные термины, извлеченные из документов, найденных в ответ на первоначальный запрос.