 2014-02-02
2014-02-02 6237
6237В настоящее время примерно одинаковое распространение получили два способа построения вычислительных машин: с непосредственными связями и на основе шины.
Типичным представителем первого способа может служить классическая фон-неймановская вычислительная машина (рис. 1.3). В ней между взаимодействующими устройствами (процессор, память, устройство ввода/вывода) имеются непосредственные связи. Особенности связей (число линий в шинах, пропускная способность и т. п.) определяются видом информации, характером и интенсивностью обмена Достоинством архитектуры с непосредственными связями можно считать возможность развязки «узких мест» путем улучшения структуры и характеристик только определенных связей, что экономически может быть наиболее выгодным решением. У фон-неймановских ВМ таким «узким местом» является канал пересылки данных между ЦП и памятью. Кроме того, ВМ с непосредственными связями плохо поддаются реконфигурации.
В варианте с общей шиной все устройства вычислительной машины подключены к магистральной шине, служащей единственным трактом для потоков команд, данных и управления (рис. 1.4). Наличие общей шины существенно упрощает реализацию ВМ, позволяет легко менять состав и конфигурацию машины. Благодаря этим свойствам шинная архитектура получила широкое распространение в мини-и микроЭВМ. Вместе с тем, именно с шиной связан и основной недостаток архитектуры: в каждый момент передавать информацию по шине может только одно устройство. Основную нагрузку на шину создают обмены между процессором и памятью, связанные с извлечением из памяти команд и данных и записью в память результатов вычислений. На операции ввода/вывода остается лишь часть пропускной способности шины. Практика показывает, что даже при достаточно быстрой шине для 90% приложений этих остаточных ресурсов обычно не хватает, особенно в случае ввода или вывода больших массивов данных.
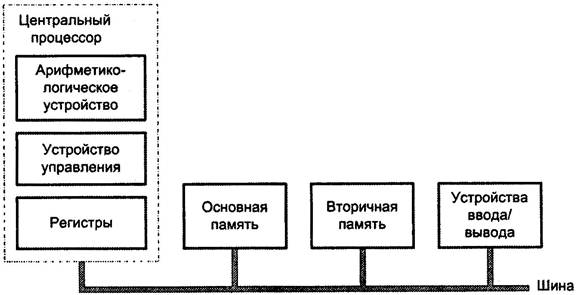
Рис. 1.4. Структура вычислительной машины на базе общей шины
При сохранении фон-неймановской концепции последовательного выполнения команд программы шинная архитектура в чистом ее виде оказывается недостаточно эффективной. Более распространена архитектура с иерархией шин, где помимо магистральной шины имеется еще несколько дополнительных шин. Они могут обеспечивать непосредственную связь между устройствами с наиболее интенсивным обменом, например процессором и кэшпамятью. Другой вариант использования дополнительных шин – объединение однотипных устройств ввода/вывода с последующим выходом с дополнительной шины на магистральную. Всеэти меры позволяют снизить нагрузку на общую шину и более эффективно расходовать ее пропускную способность.
В современных ВМ общая шина состоит из нескольких «подшин» – шины адреса, шины данных и шины управления. В персональных машинах для экономии места на системной плате шины адреса и данных иногда выполняют в виде одной разделяемой во времени шины; тогда адрес и данные по ней передаются только поочередно.
Базовым элементом компьютера является триггер. На его основе выполняются другие узлы компьютера.
Триггер – электронная схема, которая может находиться в одном из двух устойчивых состояний «0» и «1». Внешними сигналами можно переводить триггер из одного состояния в другое.
Регистр – это несколько определенным образом соединенных триггеров, т.е. можно записать двоичное слово в регистр, прочитать его, сдвинуть, инвертировать.
Счетчик позволяет определить число поступивших на него сигналов. Он также строится на основе триггеров.
Логическая схема реализует определенную логическую функцию, т. е. формирует выходной сигнал при определенных комбинациях сигналов на ее входах.
Содержимое счетчика команд (СчК) процессора передается по адресной шине на регистр адреса (РгА) основной памяти (рис. 1.5). В момент включения компьютера в счетчике команд всегда находится один и тот же начальный адрес. Таким образом, запрашивается содержимое ячейки памяти с этим начальным адресом, принадлежащим BIOS. Как правило, эта ячейка содержит код команды безусловного перехода, служащей для изменения содержимого счетчика команд. Этот код передается на регистр команд (РгК) процессора по шине данных. Содержимое ячейки памяти поступает на регистр команд РгК, поскольку запрос к памяти произведен из счетчика команд; это обязательное требование для любого компьютера традиционной архитектуры.
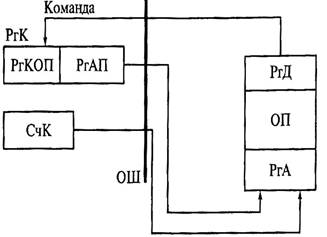
Рис. 1.5. Передача команд из ОП в ЦП
Регистр команд процессора РгК, в свою очередь, состоит из нескольких регистров – регистра кода операции (РгКОП) и регистров адресов процессора (РгАП). Часть слова, попавшая в регистр кода операции, передается в блок управления (БУ), вырабатывающий последовательность управляющих сигналов.
Когда выполняется команда безусловного перехода, вторая адресная часть слова, попавшая в один из регистров адреса процессора, под управлением сигналов с БУ передается вновь на счетчик команд. Эта команда одноадресная, т.е. ее адресная часть содержит только один адрес. На этом и завершается ее выполнение. Блок управления формирует сигнал об окончании выполнения команды, а содержимое СчК вновь передается на РгА памяти, т. е. происходит запрос следующей команды.
Таким образом, процедура обращения к памяти повторяется. Содержимое ячейки памяти, к которой произведено повторное обращение, рассматривается в качестве новой команды, т.е. вновь загружается на РгК процессора. Обычно вторая команда служит для начала загрузки ОЗУ с магнитного диска; она уже не является командой безусловного перехода. При ее выполнении под давлением кода операции (часть команды, попавшая на РгКОП) вырабатываются иные управляющие сигналы, а содержимое первого регистра РгАП, представляющего собой часть РгК, передается на адресный регистр памяти и рассматривается в качестве адреса первого операнда.
Для ОЗУ безразлично, откуда пришел запрос – из счетчика команд или адресного регистра, поэтому в регистре данных (РгД) памяти слово формируется так же, как и раньше. Однако в процессоре оно помещается на первый регистр данных АЛУ, поскольку запрос этого слова поступил из адресного регистра РгАП процессора. Затем блок управления формирует аналогичные сигналы для передачи на регистр адреса РгА основной памяти содержимого второго регистра адреса РгАП процессора; в результате содержимое ячейки памяти с адресом, находящимся в регистре адресов процессора РгАП, поступает на второй регистр данных арифметического устройства.
Затем блок управления вырабатывает сигналы в зависимости от кода операции в регистре кода операции РгКОП, подает их в АЛУ, которое выполняет соответствующую операцию, а ее результат помещает в выходной регистр-аккумулятор. После этого содержимое регистра-аккумулятора передается в ячейку памяти, адрес которой обычно находится в первом регистре адресов процессора РгАП, т. е. выполняется еще одно обращение к ОП. Информация из регистра-аккумулятора передается на шину данных, а адрес ячейки из регистра адресов процессора РгАП – на адресную шину. В зависимости от конструкции машины, числа адресов в выполняемой команде (адресности) и других особенностей, содержимое регистра-аккумулятора может сохраняться в нем, передаваться в ячейку ОП по адресу, находящемуся в первом или втором РгАП.
После сохранения содержимого регистра-аккумулятора к счетчику команд (СчК) добавляется длина текущей команды в байтах (часто говорят «единица»), чтобы обратиться к следующей ячейке памяти, и начинается новый цикл выполнения очередной команды.
Таким образом, выполнение программы происходит последовательно: каждый раз в машине реализуется лишь одна команда, попадающая в регистр команд из ОП. Чтобы увеличить производительность компьютера, нужно либо повысить скорость выполнения команды, либо выполнять несколько последовательных команд одновременно. Повышение скорости выполнения команды связано с улучшением технических характеристик и увеличением быстродействия всех компонентов, входящих в компьютер – ЦП, ОП, шин интерфейсов, устройств ввода-вывода. Но увеличение скорости выполнения команды принципиально ограничено – скорость распространения сигналов в машине не может превышать скорость света, а длина пути определяется числом вентилей и применяемой технологией. Второй путь, заключающийся в параллельном выполнении нескольких команд, наиболее перспективен.

