 2014-02-02
2014-02-02 3091
3091Якщо кожному символу алфавіту зіставити певне ціле число (наприклад, порядковий номер), то за допомогою двійкової коди можна кодувати і текстову інформацію. Вісім двійкових розрядів досить для кодування 256 різних символів. Це вистачить, щоб виразити різними комбінаціями восьми бітів всі символи англійської і російської мов, як рядкові, так і прописні, а також розділові знаки, символи основних арифметичних дій і деякі общепринятые спеціальні символи, наприклад символ «§».
Технічно це виглядає дуже просто, проте завжди існували достатньо вагомі організаційні складнощі. У перші роки розвитку обчислювальної техники вони були пов'язані з відсутністю необхідних стандартів, а в даний час викликані, навпаки, достатком тих, що одночасно діють і суперечливих стандартов. Для того, щоб весь світ однаково кодував текстові дані, потрібні єдині таблиці кодування, а це поки неможливо із-за суперечностей між символами національних алфавітів, а також суперечностей корпоративного характеру.
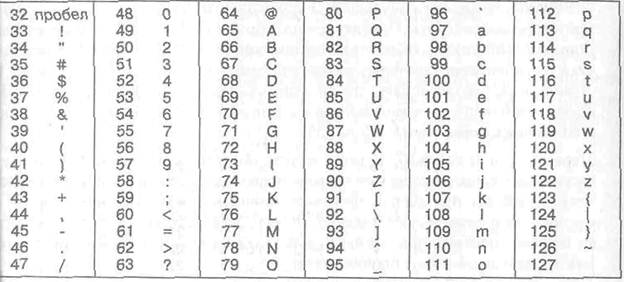
Для англійської мови, що захопила де-факто нішу міжнародного засобу спілкування, суперечності вже зняті. Інститут стандартизації США (ANSI—American National Standard Institute) ввів в дію систему кодування ASCII (American Standard Code for Information Interchange — стандартний код інформаційного обміну США). У системі ASCII закріплено дві таблиці кодування — базова і розширена. Базова таблиця закріплює значення код від 0 до 127, а розширена відноситься до символів з номерами від 128 до 255.
Перші 32 коди базової таблиці, починаючи з нульового, віддано виробникам апаратних засобів (насамперед виробникам комп'ютерів і печатающих пристроїв). У цій області розміщуються так звані коди, що управляють, яким не відповідають ніякі символи мов, і, відповідно, ці коди не виводяться ні на екран, ні на пристрої друку, але ними можна управляти тим, як проводиться виведення інших даних.
Починаючи з коди 32 по код 127 розміщені коди символів англійського алфавіту, розділового, цифр, арифметичних дій і деяких допоміжних символів знаків. Базова таблиця кодування ASCII приведена в таблиці 1.1.
Аналогічні системи кодування текстових даних були розроблені і в інших країнах. Так, наприклад, в СРСР в цій області діяла система кодування ЯКІ-7 (код обміну інформацією, семизначний). Проте підтримка виробників устаткування і програм вивела американський код ASCII на рівень международного стандарту, і національним системам кодування довелося «відступити» в другу, розширену частину системи кодування, що визначає значення код з 128 по 255. Відсутність єдиного стандарту в цій області привела до множественности кодувань, що одночасно діяли. Тільки у Росії можна вказати три стандарти кодування, що діють, і ще два застарілих.
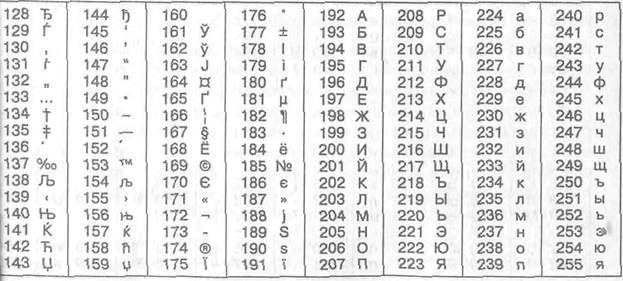
Так, наприклад, кодування символів російської мови, відоме як кодування Windows-1251, було введене «ззовні» — компанією Microsoft.
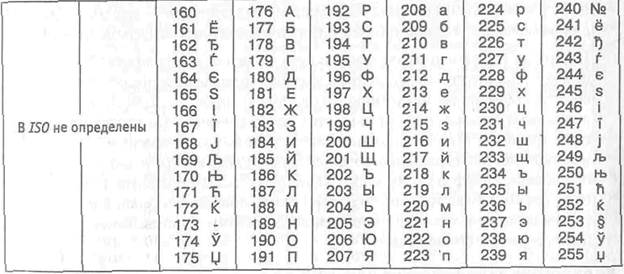
Інше поширене кодування носить назву ЯКІ-8 (код обміну інформацією, восьмизначний) — її походження відноситься до часів дії Советг Економічної Взаємодопомоги держав Східної Европи (таблица1.3). Сьогодні юдировка ЯКІ-8 має широке розповсюдження в комп'ютерних мережах на території Росії і в російському секторі Інтернету.
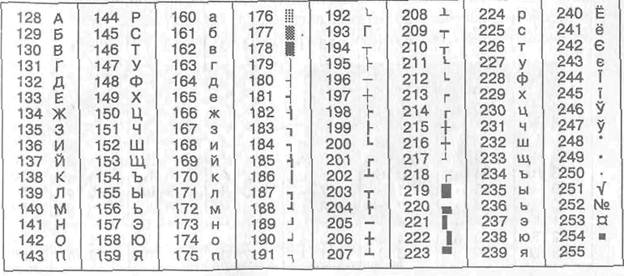
Міжнародний стандарт, в якому передбачено кодування символів російського алфавіту, носить назву кодування 750 (International Standard Organization — Міжнародний інститут стандартизації). На практиці дане кодування использутся рідко (таблиця 1.4).
Базова таблиця кодування ASCII
Кодування Windows 1251
Кодування ЯКІ-8

Кодування ISO
ГОСТ-АЛЬТЕРНАТИВНЕ кодування
Універсальна система кодування текстових даних їли проаналізувати організаційні труднощі, пов'язані із створенням єдиною истемы кодування текстових даних, то можна прийти до висновку, що вони викликані обмеженим набором код (256). В той же час очевидний, що якщо, наприклад, кодувати символи не восьмирозрядними двійковими числами, а числами з великою кількістю розрядів, то і діапазон можливих значень код стане набагато більший. Така система, заснована на 16-розрядному кодуванні символів, отримала назву універсальною — UNICODE. Шістнадцять розрядів дозволяють забезпечити унікальні коди для 65 536 різних символів — це поле досить для розміщення в одній таблиці символів більшості мов планети. Не дивлячись на тривіальну очевидність такого підходу, простий механічний перехід на дану систему довгий час стримувався із-за недостатніх ресурсів засобів обчислювальної техніки (у системі кодування UNICODE все текстові дакументы автоматично стають удвічі довшими). У другій половині 90-х років технічні засоби досягли необхідного рівня забезпеченості ресурсами, і сьогодні ми спостерігаємо поступовий переклад документів і програмних засобів на універсальну систему кодування. Для індивідуальних користувачів це ще більше додало турбот за погодженням документів, виконаних в різних системах кодування, різними програмними засобами, але це треба розуміти як трудности перехідного періоду.

