 2014-02-09
2014-02-09 1590
1590Примеры задач
Пример 1: Пусть у нас имеется 3 метода обучения арифметики и группа студентов. Группа разбивается случайным образом на 3 подгруппы для обучения одним из методов. В конце курса обучения студенты проходят общий тест, по результатам которого выставляются оценки. Также для каждого студента имеется одна или несколько характеристик (количественных) их общей образованности.
Требуется проверить гипотезу об одинаковой эффективности методик обучения.
Пример 2: Для сравнения качества нескольких видов крахмала (пшеничного, картофельного …) был проведён эксперимент, в котором измерялась прочность крахмальных плёнок. Также для каждого испытания измерена толщина использовавшейся крахмальной плёнки.
Требуется проверить гипотезу об одинаковом качестве различного крахмала.
Пример 3: Пусть для нескольких различных школ были собраны отметки их учеников, полученные на общем для всех экзамене. Также для каждого из учеников известны отметки, полученные ими по другим экзаменам (например, вступительным в школу).
Требуется проверить гипотезу об одинаковом качестве образования в школах.
Основные теоретические и прикладные проблемы ковариационного анализа относятся к линейным моделям. В частности, если анализируются n наблюдений  с p сопутствующими переменными
с p сопутствующими переменными 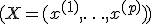 , k возможными типами условий эксперимента
, k возможными типами условий эксперимента 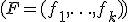 , то линейная модель соответствующего ковариационного анализа задается уравнением:
, то линейная модель соответствующего ковариационного анализа задается уравнением:
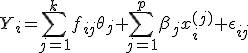
где 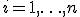 , индикаторные переменные
, индикаторные переменные 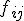 равны 1, если
равны 1, если 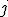 -е условие эксперимента имело место при наблюдении
-е условие эксперимента имело место при наблюдении 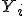 , и равны 0 в противном случае. Коэффициенты
, и равны 0 в противном случае. Коэффициенты 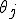 определяют эффект влияния -го условия,
определяют эффект влияния -го условия, 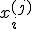 — значение сопутствующей переменной
— значение сопутствующей переменной 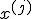 , при котором получено наблюдение ,
, при котором получено наблюдение , 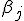 — значения соответствующих коэффициентов регрессии
— значения соответствующих коэффициентов регрессии 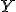 по ,
по , 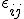 — независимые случайные ошибки с нулевым математическим ожиданием.
— независимые случайные ошибки с нулевым математическим ожиданием.
Приведённая формула задаёт линейную модель однофакторного ковариационного анализа с 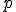 независимыми переменными и
независимыми переменными и 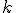 уровнями фактора. При включении в модель дополнительных факторов в правой части уравнения появятся слагаемые, отвечающие за эффекты уровней вновь введённых в модель факторов.
уровнями фактора. При включении в модель дополнительных факторов в правой части уравнения появятся слагаемые, отвечающие за эффекты уровней вновь введённых в модель факторов.
Замечание: коэффициенты регрессии в приведённой формуле не зависят от качественных факторов. Это включает предположение, что линейная зависимость имеет одинаковые коэффициенты для каждого значения качественного фактора.
Основное назначение ковариационного анализа — использование в построении статистических оценок 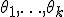 ;
; 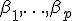 и статистических критериев для проверки различных гипотез относительно значений этих параметров. Если в модели постулировать априори
и статистических критериев для проверки различных гипотез относительно значений этих параметров. Если в модели постулировать априори 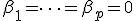 , то получится модель дисперсионного анализа, если же исключить влияние неколичественных факторов (положить
, то получится модель дисперсионного анализа, если же исключить влияние неколичественных факторов (положить 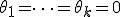 ), то получится модель регрессионного анализа.
), то получится модель регрессионного анализа.
Корреляционный и регрессивный анализ. Матрица данных. Многие объекты исследования характеризуются множеством параметров, и по результатам наблюдения за их функционированием формируются многомерные совокупности (матрицы) ЭД.

(4.1)
Строки такой матрицы соответствуют результатам регистрации всех наблюдаемых параметров объекта в одном эксперименте, а столбцы содержат результаты наблюдений за одним параметром (фактором, вариантой) во всех экспериментах. Обозначим количество параметров через m (m>1), а количество наблюдений – через n.
В матрице элемент хij соответствует значению j-й варианты в i-м наблюдении. Матрица, вообще говоря, может содержать пустые значения некоторых элементов, например, из-за пропусков в регистрации значений параметров. В многомерном анализе желательно устранить пропущенные значения. Для этого существуют специальные приемы, в частности, вычеркивание соответствующих строк матрицы или занесение средних значений вместо отсутствующих. В дальнейшем будем считать, что матрица не содержит пустых элементов, а параметры объекта характеризуются непрерывными случайными величинами.
Методы обработки матрицы ЭД основаны на следующем предположении: если объект подвергнуть новому обследованию и получить, вообще говоря, другую матрицу данных, то после ее обработки с помощью тех же методов будут получены результаты, близкие к результатам обработки первой матрицы. Данное предположение основано на статистической гипотезе формирования матрицы ЭД. Матрица порождается случайным образом в соответствии с определенной вероятностной закономерностью, а именно: в m-мерном пространстве параметров существует некоторое (пусть и неизвестное) распределение вероятностей, и каждая строка матрицы появляется в соответствии с этим распределением независимо от появления других строк.
Каждый столбец матрицы представляет собой случайную выборку значений одного параметра объекта. Указанное предположение означает, во-первых, что оценки моментов и параметров распределения, вычисленные по выборке, будут близки к истинным значениям, во-вторых, значения непрерывных функций, построенных по этим оценкам, будут близки к значениям функций, построенным по истинным значениям параметров.
Таким образом, объектом исследования в многомерном анализе является многомерная случайная величина, представленная выборкой конечного объема. К такой выборке применимы все методы и оценки, рассмотренные при обработке одномерных ЭД. Конечно, приведенные суждения не являются доказательством допустимости применения рассматриваемых методов, но вполне подтверждаются практикой.
Параметры, характеризующие объект исследования, имеют разный физический смысл, и матрица данных существенно изменяется, если изменяются шкалы, в которых измеряются те или иные параметры. Матрицу данных еще до проведения анализа целесообразно привести к стандартному виду, т.е. стандартизовать значения вариант (напомним, что среднее значение стандартизованной варианты равно нулю, дисперсия – единице). В тех случаях, когда все варианты измеряются в одной шкале, это преобразование все-таки желательно, ибо оно упрощает последующие преобразования. Стандартизованную матрицу будем обозначать через U. Переход от исходной к стандартизованной матрице осуществляется следующим образом:
вычисляются оценки математического ожидания 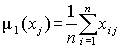 и дисперсии
и дисперсии 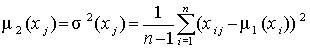 каждой варианты
каждой варианты 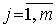 ;
;
вычисляются элементы стандартизованной матрицы
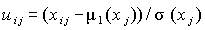
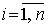 , .
, .
Элементы матрицы U являются безразмерными величинами. Именно матрица U будет являться объектом последующей обработки.
Корреляционный анализ. Величины, характеризующие различные свойства объектов, могут быть независимыми или взаимосвязанными. Различают два вида зависимостей между величинами (факторами): функциональную и статистическую.
При функциональной зависимости двух величин значению одной из них обязательно соответствует одно или несколько точно определенных значений другой величины. Функциональная связь двух факторов возможна лишь при условии, что вторая величина зависит только от первой и не зависит ни от каких других величин. Функциональная связь одной величины с множеством других возможна, если эта величина зависит только от этого множества факторов. В реальных ситуациях существует бесконечно большое количество свойств самого объекта и внешней среды, влияющих друг на друга, поэтому такого рода связи не существуют, иначе говоря, функциональные связи являются математическими абстракциями. Их применение допустимо тогда, когда соответствующая величина в основном зависит от соответствующих факторов.
При исследовании АСОИУ многие параметры следует считать случайными, что исключает проявление однозначного соответствия значений. Воздействие общих факторов, наличие объективных закономерностей в поведении объектов приводят лишь к проявлению статистической зависимости. Статистической называют зависимость, при которой изменение одной из величин влечет изменение распределения других (другой), и эти другие величины принимают некоторые значения с определенными вероятностями. Функциональную зависимость в таком случае следует считать частным случаем статистической: значению одного фактора соответствуют значения других факторов с вероятностью, равной единице. Однако на практике такое рассмотрение функциональной связи применения не нашло.
Более важным частным случаем статистической зависимости является корреляционная зависимость, характеризующая взаимосвязь значений одних случайных величин со средним значением других, хотя в каждом отдельном случае любая взаимосвязанная величина может принимать различные значения.
Если же у взаимосвязанных величин вариацию имеет только одна переменная, а другая является детерминированной, то такую связь называют не корреляционной, а регрессионной. Например, при анализе скорости обмена с жесткими дисками можно оценивать регрессию этой характеристики на определенные модели, но не следует говорить о корреляции между моделью и скоростью.
При исследовании зависимости между одной величиной и такими характеристиками другой, как, например, моменты старших порядков (а не среднее значение), то эта связь будет называться статистической, а не корреляционной.
Корреляционная связь описывает следующие виды зависимостей:
- причинную зависимость между значениями параметров. Примером такой зависимости является взаимосвязь пропускной способности канала передачи данных и соотношения сигнал/шум (на пропускную способность влияют и другие факторы – характер помех, амплитудно-частотные характеристики канала, способ кодирования сообщений и др.). Установить однозначную связь между конкретными значениями указанных параметров не удается. Но очевидно, что пропускная способность зависит от соотношения уровней сигнала и помех в канале. Иногда при этом причину и следствие особо не выделяют. В некоторых случаях такая корреляция является бессмысленной, например: если в качестве исходного фактора взять доходы разработчиков антивирусных программ, а за результат – количество вновь появляющихся вирусов, то можно сделать вывод, что разработчики антивирусов "стимулируют" создание вирусов;
- "зависимость" между следствиями общей причины. Подобная зависимость характерна, в частности, для скорости и безошибочности набора текста оператором (указанные факторы зависят от квалификации оператора).
Корреляционная зависимость определяется различными параметрами, среди которых наибольшее распространение получили показатели, характеризующие взаимосвязь двух случайных величин (парные показатели): корреляционный момент, коэффициент корреляции.
Оценка корреляционного момента (коэффициента ковариации) двух вариант xj и xk вычисляется по исходной матрице Х
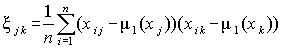
(4.2)
Этот показатель неудобен для практического применения, так как имеет размерность, равную произведению размерностей вариант, и по его величине трудно судить о зависимости параметров.
Коэффициент ковариации rjk нормированных случайных величин называют коэффициентом корреляции, его оценка
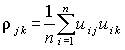 .
.
(4.3)
Значение коэффициента корреляции лежит в пределах от –1 до +1. Если случайные величины Uj и Uk независимы, то коэффициент rjk обязательно равен нулю, обратное утверждение неверно. Коэффициент rjk характеризует значимость линейной связи между параметрами:
- при r jk =1 значения uij и uik полностью совпадают, т.е. значения параметров принимают одинаковые значения. Иначе говоря, имеет место функциональная зависимость: зная значение одного параметра, можно однозначно указать значение другого параметра;
- при r jk = – 1 величины uij и uik принимают противоположные значения. И в этом случае имеет место функциональная зависимость;
- при r jk = 0 величины uij и uik практически не связаны друг с другом линейным соотношением. Это не означает отсутствия каких-то других (например, нелинейных) связей между параметрами;
- при | r jk | > 0 и | r jk | < 1 однозначной линейной связи величин uij и uik нет. И чем меньше абсолютная величина коэффициента корреляции, тем в меньшей степени по значениям одного параметра можно предсказать значение другого.
Используя понятие коэффициента корреляции, матрице ЭД можно поставить в соответствие квадратную матрицу оценок коэффициентов корреляции (корреляционную матрицу)
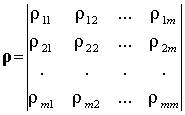
(4.4)
К числу характерных свойств корреляционной матрицы относят: симметричность относительно главной диагонали, r jk=r kj, 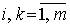 ; единичные значения элементов главной диагонали, r kk=1 (r kk соответствует дисперсии стандартизованного параметра uk),
; единичные значения элементов главной диагонали, r kk=1 (r kk соответствует дисперсии стандартизованного параметра uk), 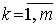 .
.
Оценка коэффициента корреляции, вычисленная по ограниченной выборке, практически всегда отличается от нуля. Но из этого еще не следует, что коэффициент корреляции генеральной совокупности также отличен от нуля. Требуется оценить значимость выборочной величины коэффициента или, в соответствии с постановкой задач проверки статистических гипотез, проверить гипотезу о равенстве нулю коэффициента корреляции. Если гипотеза Н0 о равенстве нулю коэффициента корреляции будет отвергнута, то выборочный коэффициент значим, а соответствующие величины связаны линейным соотношением. Если гипотеза Н0 будет принята, то оценка коэффициента не значима, и величины линейно не связаны друг с другом (если по физическим соображениям факторы могут быть связаны, то лучше говорить о том, что по имеющимся ЭД эта взаимосвязь не установлена). Проверка гипотезы о значимости оценки коэффициента корреляции требует знания распределения этой случайной величины. Распределение величины r ik изучено только для частного случая, когда случайные величины Uj и Uk распределены по нормальному закону.
В качестве критерия проверки нулевой гипотезы Н0 применяют случайную величину 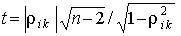 . Если модуль коэффициента корреляции относительно далек от единицы, то величина t при справедливости нулевой гипотезы распределена по закону Стьюдента с n – 2 степенями свободы. Конкурирующая гипотеза Н1 соответствует утверждению, что значение r ik не равно нулю (больше или меньше нуля). Поэтому критическая область двусторонняя.
. Если модуль коэффициента корреляции относительно далек от единицы, то величина t при справедливости нулевой гипотезы распределена по закону Стьюдента с n – 2 степенями свободы. Конкурирующая гипотеза Н1 соответствует утверждению, что значение r ik не равно нулю (больше или меньше нуля). Поэтому критическая область двусторонняя.
Проверка гипотезы Н0 о равенстве нулю генерального коэффициента парной корреляции двумерной нормально распределенной случайной величины осуществляется в следующей последовательности:
- вычисляется значение статистики t;
- при уровне значимости a для двусторонней области определяется критическая точка распределения Стьюдента tкр(n–2; a), табл. П.4;
- сравнивается значение статистики t с критическим значением tкр(n–2; a). Если t < tкр (п–2; a), то нет оснований отвергнуть нулевую гипотезу, иначе гипотеза Н0 отвергается (коэффициент корреляции значим).
Когда модуль величины r ik близок к единице, распределение r ik отличается от распределения Стьюдента, так как значение |r ik | ограничено справа единицей. В этом случае применяют преобразование yik=0,5ln[(1+|r ik |)/(1–|r ik |)]. Величина yik не имеет указанного ограничения, она при п > 10 распределена приблизительно нормально с центром m 1(r ik)=0,5ln[(1+|r ik|)/(1–|r ik|)]+0,5|r ik|/(n–1) и дисперсией m 2(r ik)=s 2(r ik)=1/(п–3). Если значение центрированной и нормированной величины (yik –m 1(r ik))/s (r ik) превышает значение квантили уровня 1–a /2 нормального распределения стандартизованной величины, то нулевая гипотеза отвергается.
Таким образом, постановка задачи линейного корреляционного анализа формулируется в следующем виде.
Имеется матрица наблюдений вида (4.1). Необходимо определить оценки коэффициентов корреляции для всех или только для заданных пар параметров и оценить их значимость. Незначимые оценки приравниваются к нулю. Допущения:
- выборка имеет достаточный объем. Понятие достаточного объема зависит от целей анализа, требуемой точности и надежности оценки коэффициентов корреляции, от количества факторов. Минимально допустимым считается объем, когда количество наблюдений не менее чем в 5–6 раз превосходит количество факторов;
- выборки по каждому фактору являются однородными. Это допущение обеспечивает несмещенную оценку средних величин;
- матрица наблюдений не содержит пропусков.
Если необходима проверка значимости оценки коэффициента корреляции, то требуется соблюдение дополнительного условия – распределение вариант должно подчиняться нормальному закону.
Задача анализа решается в несколько этапов:
- проводится стандартизация исходной матрицы;
- вычисляются парные оценки коэффициентов корреляции;
- проверяется значимость оценок коэффициентов корреляции, незначимые оценки приравниваются к нулю. По результатам проверки делается вывод о наличии связей между вариантами (факторами).
Пример 4.1. Результаты наблюдений за характеристиками канала представлены в табл. 4.1.
Таблица 4.1
| № пп | Пропускная способность канала, кбит/с | Соотношение сигнал/шум, | Остаточное затухание, на частоте, Гц дБ, | ||
| дБ | |||||
| Х1 | X2 | X3 | X4 | X5 | |
| 26,37 | 41,98 | 17,66 | 16,05 | 22,85 | |
| 28,00 | 43,83 | 17,15 | 15,47 | 23,25 | |
| 27,83 | 42,83 | 15,38 | 17,59 | 24,55 | |
| 31,67 | 47,28 | 18,39 | 16,92 | 26,59 | |
| 23,50 | 38,75 | 18,32 | 15,66 | 26,22 | |
| 21,04 | 35,12 | 17,81 | 17,00 | 27,52 | |
| 16,94 | 32,07 | 21,42 | 16,77 | 25,76 | |
| 37,56 | 54,25 | 26,42 | 15,68 | 23,10 | |
| 18,84 | 32,70 | 17,23 | 15,92 | 23,41 | |
| 25,77 | 40,51 | 30,43 | 15,29 | 25,17 | |
| 33,52 | 49,78 | 21,71 | 15,61 | 25,39 | |
| 28,21 | 43,84 | 28,33 | 15,70 | 24,56 | |
| 28,76 | 44,03 | 30,42 | 16,87 | 24,45 | |
| 24,60 | 39,46 | 21,66 | 15,25 | 23,81 | |
| 24,51 | 38,78 | 25,77 | 16,05 | 24,48 |
Необходимо определить наличие линейных корреляционных связей между пропускной способностью и остальными факторами. Предполагается, что выборки по всем вариантам подчиняются нормальному закону. Проверку гипотезы о значимости оценок коэффициентов корреляции произвести с уровнем значимости a, равным 0,1.
Решение. Стандартизация исходной матрицы начинается с вычисления выборочной средней m1, несмещенной оценки дисперсии m2 и среднеквадратического отклонения s по каждой варианте, табл.4.2.
Таблица 4.2
| Оценка параметра распределения | Варианта | ||||
| Х1 | X2 | X3 | X4 | X5 | |
| m 1 | 26,47 | 41,68 | 21,87 | 16,12 | 24,74 |
| m 2 | 29,10 | 36,47 | 26,37 | 0,52 | 1,88 |
| s | 5,39 | 6.04 | 5,13 | 0,72 | 1,37 |
В результате перехода к величинам 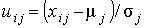 формируется стандартизованная матрица исходных данных, табл. 4.3.
формируется стандартизованная матрица исходных данных, табл. 4.3.
Таблица 4.3
| № пп | Пропускная способность | Соотношение сигнал/шум, | Остаточное затухание, на частоте, Гц | ||
| канала, кбит/с | дБ | ||||
| U1 | U2 | U3 | U4 | U5 | |
| –0,02 | 0,05 | –0,82 | –0,10 | –1,38 | |
| 0,28 | 0,36 | –0,92 | –0,90 | –1,09 | |
| 0,25 | 0,19 | –1,26 | 2,03 | –0,14 | |
| 0,96 | 0,93 | –0,68 | 1,10 | 1,35 | |
| –0,55 | –0,49 | –0,69 | –0,64 | 1,08 | |
| –1,01 | –1,09 | –0,79 | 1,21 | 2,03 | |
| –1,77 | –1,59 | –0,09 | 0,90 | 0,74 | |
| 2,06 | 2,08 | 0,89 | –0,61 | –1,20 | |
| –1,42 | –1,49 | –0,90 | –0,28 | –0,97 | |
| –0,13 | –0,19 | 1,67 | –1,15 | 0,31 | |
| 1,31 | 1,34 | –0,03 | –0,71 | 0,47 | |
| 0,32 | 0,36 | 1,26 | –0,58 | –0,13 | |
| 0,42 | 0,39 | 1,66 | 1,03 | –0,21 | |
| –0,35 | –0,37 | –0,04 | –1,21 | –0,68 | |
| –0,36 | –0,48 | 0,76 | –0,10 | –0,19 |
Оценки коэффициентов корреляции 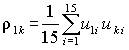 (k = 2, 3, 4) представлены в табл. 4.4. В этой же таблице приведены значения статистик критерия Стьюдента
(k = 2, 3, 4) представлены в табл. 4.4. В этой же таблице приведены значения статистик критерия Стьюдента 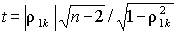 для вычисленных оценок коэффициентов корреляции при n = 15.
для вычисленных оценок коэффициентов корреляции при n = 15.
Таблица 4.4
| X2 | X3 | X4 | X5 | |
| r 1 j | 0,93 | 0,25 | – 0,13 | – 0,22 |
| t | 9,12 | 0,93 | 0,47 | 0,81 |
Критическое значение tкр (n–2; a) = tкр (13; 0,1) = 1,77. Статистика критерия больше критического значения только для r 12. Это означает, что только для указанного коэффициента оценка значима (коэффициент корреляции генеральной совокупности не равен нулю), а остальные коэффициенты следует признать равными нулю.
Корреляционная зависимость не обязательно устанавливается только для двух величин, с ее помощью можно анализировать связи между несколькими вариантами (множественная корреляция). А кроме линейной существуют и другие виды корреляции.
Регрессионный анализ. Постановка задачи. Одной из типовых задач обработки многомерных ЭД является определение количественной зависимости показателей качества объекта от значений его параметров и характеристик внешней среды. Примером такой постановки задачи является установление зависимости между временем обработки запросов к базе данных и интенсивностью входного потока. Время обработки зависит от многих факторов, в том числе от размещения искомой информации на внешних носителях, сложности запроса. Следовательно, время обработки конкретного запроса можно считать случайной величиной. Но вместе с тем, при увеличении интенсивности потока запросов следует ожидать возрастания его среднего значения, т.е. считать, что время обработки и интенсивность потока запросов связаны корреляционной зависимостью.
Постановка задачи регрессионного анализа формулируется следующим образом. Имеется совокупность результатов наблюдений вида (4.1). В этой совокупности один столбец соответствует показателю, для которого необходимо установить функциональную зависимость с параметрами объекта и среды, представленными остальными столбцами. Будем обозначать показатель через y* и считать, что ему соответствует первый столбец матрицы наблюдений. Остальные т–1 (m > 1) столбцов соответствуют параметрам (факторам) х2, х3, …, хт.
Требуется: установить количественную взаимосвязь между показателем и факторами. В таком случае задача регрессионного анализа понимается как задача выявления такой функциональной зависимости y* = f(x2, x3, …, xт), которая наилучшим образом описывает имеющиеся экспериментальные данные. Допущения:
- количество наблюдений достаточно для проявления статистических закономерностей относительно факторов и их взаимосвязей;
- обрабатываемые ЭД содержат некоторые ошибки (помехи), обусловленные погрешностями измерений, воздействием неучтенных случайных факторов;
- матрица результатов наблюдений является единственной информацией об изучаемом объекте, имеющейся в распоряжении перед началом исследования.
Функция f(x2, x3, …, xт), описывающая зависимость показателя от параметров, называется уравнением (функцией) регрессии. Термин "регрессия" (regression (лат.) – отступление, возврат к чему-либо) связан со спецификой одной из конкретных задач, решенных на стадии становления метода, и в настоящее время не отражает всей сущности метода, но продолжает применяться.
Решение задачи регрессионного анализа целесообразно разбить на несколько этапов:
- предварительная обработка ЭД;
- выбор вида уравнений регрессии;
- вычисление коэффициентов уравнения регрессии;
- проверка адекватности построенной функции результатам наблюдений.
Предварительная обработка включает стандартизацию матрицы ЭД, расчет коэффициентов корреляции, проверку их значимости и исключение из рассмотрения незначимых параметров (эти преобразования были рассмотрены в рамках корреляционного анализа). В результате преобразований будут получены стандартизованная матрица наблюдений U (через y будем обозначать стандартизованную величину y*) и корреляционная матрица r.
Стандартизованной матрице U можно сопоставить одну из следующих геометрических интерпретаций:
в m-мерном пространстве оси соответствуют отдельным параметрам и показателю. Каждая строка матрицы представляет вектор в этом пространстве, а вся матрица – совокупность n векторов в пространстве параметров;
в n-мерном пространстве оси соответствуют результатам отдельных наблюдений. Каждый столбец матрицы – вектор в пространстве наблюдений. Все вектора в этом пространстве имеют одинаковую длину, равную 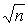 . Тогда угол между двумя векторами характеризует взаимосвязь соответствующих величин. И чем меньше угол, тем теснее связь (тем больше коэффициент корреляции).
. Тогда угол между двумя векторами характеризует взаимосвязь соответствующих величин. И чем меньше угол, тем теснее связь (тем больше коэффициент корреляции).
В корреляционной матрице особую роль играют элементы левого столбца – они характеризуют наличие или отсутствие линейной зависимости между соответствующим параметром ui (i =2, 3, …, т) и показателем объекта y. Проверка значимости позволяет выявить такие параметры, которые следует исключить из рассмотрения при формировании линейной функциональной зависимости, и тем самым упростить последующую обработку.
Выбор вида уравнения регрессии. Задача определения функциональной зависимости, наилучшим образом описывающей ЭД, связана с преодолением ряда принципиальных трудностей. В общем случае для стандартизованных данных функциональную зависимость показателя от параметров можно представить в виде
y = f(u1, u2,...up) + e
(4.5)
где f – заранее не известная функция, подлежащая определению;
e - ошибка аппроксимации ЭД.
Указанное уравнение принято называть выборочным уравнением регрессии y на u. Это уравнение характеризует зависимость между вариацией показателя и вариациями факторов. А мера корреляции измеряет долю вариации показателя, которая связана с вариацией факторов. Иначе говоря, корреляцию показателя и факторов нельзя трактовать как связь их уровней, а регрессионный анализ не объясняет роли факторов в создании показателя.
Еще одна особенность касается оценки степени влияния каждого фактора на показатель. Регрессионное уравнение не обеспечивает оценку раздельного влияния каждого фактора на показатель, такая оценка возможна лишь в случае, когда все другие факторы не связаны с изучаемым. Если изучаемый фактор связан с другими, влияющими на показатель, то будет получена смешанная характеристика влияния фактора. Эта характеристика содержит как непосредственное влияние фактора, так и опосредованное влияние, оказанное через связь с другими факторами и их влиянием на показатель.
В регрессионное уравнение не рекомендуется включать факторы, слабо связанные с показателем, но тесно связанные с другими факторами. Не включают в уравнение и факторы, функционально связанные друг с другом (для них коэффициент корреляции равен 1). Включение таких факторов приводит к вырождению системы уравнений для оценок коэффициентов регрессии и к неопределенности решения.
Функция f должна подбираться так, чтобы ошибка e в некотором смысле была минимальна. Существует бесконечное множество функций, описывающих ЭД абсолютно точно (e = 0), т.е. таких функций, которые для всех значений параметров uj,2, uj,3, …, uj,т принимают в точности соответствующие значения показателя yi, i =1, 2, …, п. Вместе с тем, для всех других значений параметров, отсутствующих в результатах наблюдений, значения показателя могут принимать любые значения. Понятно, что такие функции не соответствуют действительной связи между параметрами и показателем.
В целях выбора функциональной связи заранее выдвигают гипотезу о том, к какому классу может принадлежать функция f, а затем подбирают "лучшую" функцию в этом классе. Выбранный класс функций должен обладать некоторой "гладкостью", т.е. "небольшие" изменения значений аргументов должны вызывать "небольшие" изменения значений функции (ЭД содержат некоторые ошибки измерений, а само поведение объекта подвержено влиянию помех, маскирующих истинную связь между параметрами и показателем).
Простым, удобным для практического применения и отвечающим указанному условию является класс полиномиальных функций
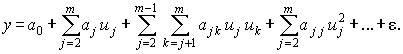
(4.6)
Для такого класса задача выбора функции сводится к задаче выбора значений коэффициентов a0, aj, ajk, …, ajj, …. Однако универсальность полиномиального представления обеспечивается только при возможности неограниченного увеличения степени полинома, что не всегда допустимо на практике, поэтому приходится применять и другие виды функций.
Частным случаем, широко применяемым на практике, является полином первой степени или уравнение линейной регрессии
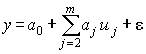
(4.7)
Это уравнение в регрессионном анализе следует трактовать как векторное, ибо речь идет о матрице данных,
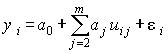 ,i =1, 2, …, n.
,i =1, 2, …, n.
(4.8)
Обычно стремятся обеспечить такое количество наблюдений, которое превышало бы количество оцениваемых коэффициентов модели. Для линейной регрессии при п > т количество уравнений превышает количество подлежащих определению коэффициентов полинома. Но и в этом случае нельзя подобрать коэффициенты таким образом, чтобы ошибка в каждом скалярном уравнении обращалась в ноль, так как к неизвестным относятся аj и e i, их количество n + т – 1, т.е. всегда больше количества уравнений п. Аналогичные рассуждения справедливы и для полиномов степени, выше первой.
Для выбора вида функциональной зависимости можно рекомендовать следующий подход:
в пространстве параметров графически отображают точки со значениями показателя. При большом количестве параметров можно строить точки применительно к каждому из них, получая двумерные распределения значений;
- по расположению точек и на основе анализа сущности взаимосвязи показателя и параметров объекта делают заключение о примерном виде регрессии или ее возможных вариантах;
- после расчета параметров оценивают качество аппроксимации, т.е. оценивают степень близости расчетных и фактических значений;
- если расчетные и фактические значения близки во всей области задания, то задачу регрессионного анализа можно считать решенной. В противном случае можно попытаться выбрать другой вид полинома или другую аналитическую функцию, например периодическую.
Вычисление коэффициентов уравнения регрессии. Систему уравнений (4.8) на основе имеющихся ЭД однозначно решить невозможно, так как количество неизвестных всегда больше количества уравнений. Для преодоления этой проблемы нужны дополнительные допущения. Здравый смысл подсказывает: желательно выбрать коэффициенты полинома так, чтобы обеспечить минимум ошибки аппроксимации ЭД. Могут применяться различные меры для оценки ошибок аппроксимации. В качестве такой меры нашла широкое применение среднеквадратическая ошибка. На ее основе разработан специальный метод оценки коэффициентов уравнений регрессии – метод наименьших квадратов (МНК). Этот метод позволяет получить оценки максимального правдоподобия неизвестных коэффициентов уравнения регрессии при нормальном распределения вариант, но его можно применять и при любом другом распределении факторов. В основе МНК лежат следующие положения:
- значения величин ошибок и факторов независимы, а значит, и некоррелированы, т.е. предполагается, что механизмы порождения помехи не связаны с механизмом формирования значений факторов;
- математическое ожидание ошибки e должно быть равно нулю (постоянная составляющая входит в коэффициент a0), иначе говоря, ошибка является центрированной величиной;
- выборочная оценка дисперсии ошибки 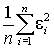 должна быть минимальна.
должна быть минимальна.
Рассмотрим применение МНК применительно к линейной регрессии стандартизованных величин. Для центрированных величин uj коэффициент a0 равен нулю, тогда уравнения линейной регрессии
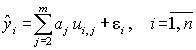 .
.
(4.9)
Здесь введен специальный знак "^", обозначающий значения показателя, рассчитанные по уравнению регрессии, в отличие от значений, полученных по результатам наблюдений.
По МНК определяются такие значения коэффициентов уравнения регрессии, которые обеспечивают безусловный минимум выражению
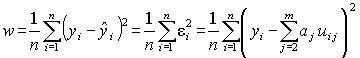 .
.
(4.10)
Минимум находится приравниванием нулю всех частных производных выражения (4.10), взятых по неизвестным коэффициентам, и решением системы уравнений
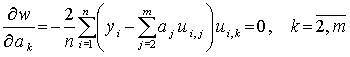
(4.11)
Последовательно проведя преобразования и используя введенные ранее оценки коэффициентов корреляции
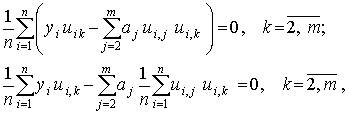
получим
. 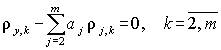
(4.12)
Итак, получено m–1 линейных уравнений, что позволяет однозначно вычислить значения a2, a3, …, am.
Если же линейная модель неточна или параметры измеряются неточно, то и в этом случае МНК позволяет найти такие значения коэффициентов, при которых линейная модель наилучшим образом описывает реальный объект в смысле выбранного критерия среднеквадратического отклонения.
Когда имеется только один параметр, уравнение линейной регрессии примет вид 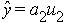 = a2 u2. Коэффициент a2 находится из уравнения r y,2 – a2 r 2,2 = 0. Тогда, учитывая, что r 2,2 = 1, искомый коэффициент
= a2 u2. Коэффициент a2 находится из уравнения r y,2 – a2 r 2,2 = 0. Тогда, учитывая, что r 2,2 = 1, искомый коэффициент
a2 = r y,2.
(4.13)
Соотношение (4.13) подтверждает ранее высказанное утверждение, что коэффициент корреляции является мерой линейной связи двух стандартизованных параметров.
Подставив найденное значение коэффициента a2 в выражение для w, с учетом свойств центрированных и нормированных величин, получим минимальное значение этой функции, равное 1– r 2y,2. Величину 1– r 2y,2 называют остаточной дисперсией случайной величины y относительно случайной величины u2. Она характеризует ошибку, которая получается при замене показателя функцией от параметра . Только при |r y,2 | = 1 остаточная дисперсия равна нулю, и, следовательно, не возникает ошибки при аппроксимации показателя линейной функцией.
Переходя от центрированных и нормированных значений показателя и параметра
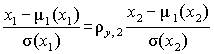 ,
,
можно получить для исходных величин
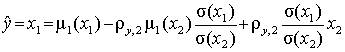 .
.
(4.14)
Это уравнение также линейно относительно коэффициента корреляции. Нетрудно заметить, что центрирование и нормирование для линейной регрессии позволяет понизить на единицу размерность системы уравнений, т.е. упростить решение задачи определения коэффициентов, а самим коэффициентам придать ясный смысл.
Применение МНК для нелинейных функций практически ничем не отличается от рассмотренной схемы (только коэффициент a0 в исходном уравнении не равен нулю).
Например, пусть необходимо определить коэффициенты параболической регрессии
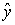 = a0 + a2 u2 + a22 u22.
= a0 + a2 u2 + a22 u22.
Выборочная дисперсия ошибки
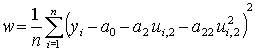 .
.
На ее основе можно получить следующую систему уравнений
После преобразований система уравнений примет вид
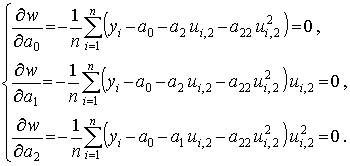
Учитывая свойства моментов стандартизованных величин, запишем
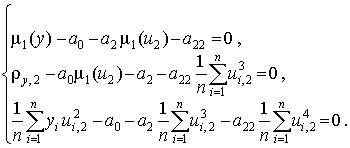
Определение коэффициентов нелинейной регрессии основано на решении системы линейных уравнений. Для этого можно применять универсальные пакеты численных методов или специализированные пакеты обработки статистических данных.
С ростом степени уравнения регрессии возрастает и степень моментов распределения параметров, используемых для определения коэффициентов. Так, для определения коэффициентов уравнения регрессии второй степени используются моменты распределения параметров до четвертой степени включительно. Известно, что точность и достоверность оценки моментов по ограниченной выборке ЭД резко снижается с ростом их порядка. Применение в уравнениях регрессии полиномов степени выше второй нецелесообразно.
Качество полученного уравнения регрессии оценивают по степени близости между результатами наблюдений за показателем и предсказанными по уравнению регрессии значениями в заданных точках пространства параметров. Если результаты близки, то задачу регрессионного анализа можно считать решенной. В противном случае следует изменить уравнение регрессии (выбрать другую степень полинома или вообще другой тип уравнения) и повторить расчеты по оценке параметров.
При наличии нескольких показателей задача регрессионного анализа решается независимо для каждого из них.
Анализируя сущность уравнения регрессии, следует отметить следующие положения. Рассмотренный подход не обеспечивает раздельной (независимой) оценки коэффициентов – изменение значения одного коэффициента влечет изменение значений других. Полученные коэффициенты не следует рассматривать как вклад соответствующего параметра в значение показателя. Уравнение регрессии является всего лишь хорошим аналитическим описанием имеющихся ЭД, а не законом, описывающим взаимосвязи параметров и показателя. Это уравнение применяют для расчета значений показателя в заданном диапазоне изменения параметров. Оно ограниченно пригодно для расчета вне этого диапазона, т.е. его можно применять для решения задач интерполяции и в ограниченной степени для экстраполяции.
Главной причиной неточности прогноза является не столько неопределенность экстраполяции линии регрессии, сколько значительная вариация показателя за счет неучтенных в модели факторов. Ограничением возможности прогнозирования служит условие стабильности неучтенных в модели параметров и характера влияния учтенных факторов модели. Если резко меняется внешняя среда, то составленное уравнение регрессии потеряет свой смысл. Нельзя подставлять в уравнение регрессии такие значения факторов, которые значительно отличаются от представленных в ЭД. Рекомендуется не выходить за пределы одной трети размаха вариации параметра, как за максимальное, так и за минимальное значения фактора.
Прогноз, полученный подстановкой в уравнение регрессии ожидаемого значения параметра, является точечным. Вероятность реализации такого прогноза ничтожна мала. Целесообразно определить доверительный интервал прогноза. Для индивидуальных значений показателя интервал должен учитывать ошибки в положении линии регрессии и отклонения индивидуальных значений от этой линии. Средняя ошибка прогноза показателя y для фактора х составит
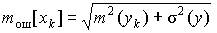 ,
,
где 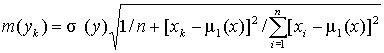 – средняя ошибка положения линии регрессии в генеральной совокупности при x = xk;
– средняя ошибка положения линии регрессии в генеральной совокупности при x = xk;
s 2(y)= 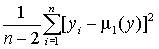 – оценка дисперсии отклонения показателя от линии регрессии в генеральной совокупности;
– оценка дисперсии отклонения показателя от линии регрессии в генеральной совокупности;
xk – ожидаемое значение фактора.
Доверительные границы прогноза, например, для уравнения регрессии (4.14), определяются выражением y[xk] ± mош[xk].
Отрицательная величина свободного члена а0 в уравнении регрессии для исходных переменных означает, что область существования показателя не включает нулевых значений параметров. Если же а0 > 0, то область существования показателя включает нулевые значения параметров, а сам коэффициент характеризует среднее значение показателя при отсутствии воздействий параметров.
Задача 4.2. Построить уравнение регрессии для пропускной способности канала по выборке, заданной в табл. 4.1.
Решение. Применительно к указанной выборке построение аналитической зависимости в основной своей части выполнено в рамках корреляционного анализа: пропускная способность зависит только от параметра "соотношение сигнал/шум". Остается подставить в выражение (4.14) вычисленные ранее значения параметров. Уравнение для пропускной способности примет вид
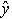 = 26,47– 0,93. 41,68. 5,39/6,04+0,93. 5,39/6,03. х = – 8,121+0,830х.
= 26,47– 0,93. 41,68. 5,39/6,04+0,93. 5,39/6,03. х = – 8,121+0,830х.
Результаты расчетов представлены в табл. 4.5.
Таблица 4.5
| № пп | Пропускная способность | Соотношение сигнал/шум | Значение функции, кбит/с | Погрешность, кбит/с |
| канала, кбит/с | дБ | |||
| Y | X | 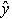 | e | |
| 26,37 | 41,98 | 26,72 | –0,35 | |
| 28,00 | 43,83 | 28,25 | –0,25 | |
| 27,83 | 42,83 | 27,42 | 0,41 | |
| 31,67 | 47,28 | 31,12 | 0,55 | |
| 23,50 | 38,75 | 24,04 | –0,54 | |
| 21,04 | 35,12 | 21,03 | 0,01 | |
| 16,94 | 32,07 | 18,49 | –1,55 | |
| 37,56 | 54,25 | 36,90 | 0,66 | |
| 18,84 | 32,70 | 19,02 | –0,18 | |
| 25,77 | 40,51 | 25,50 | 0,27 | |
| 33,52 | 49,78 | 33,19 | 0,33 | |
| 28,21 | 43,84 | 28,26 | –0,05 | |
| 28,76 | 44,03 | 28,42 | 0,34 | |
| 24,60 | 39,46 | 24,63 | –0,03 | |
| 24,51 | 38,78 | 24,06 | 0,45 |
Остаточная дисперсия стандартизованной величины Y относительно стандартизованной величины Х равна 1– 0,932 = 0,14, т.е. является малой величиной. Погрешность аппроксимации и величина остаточной дисперсии показывают высокую точность линейной модели, поэтому задачу регрессионного анализа можно считать решенной. Свободный член уравнения регрессии отрицательный, следовательно, область существования показателя не включает нулевое значение параметра "отношение сигнал/шум", что вытекает из сущности параметра (при нулевом уровне сигнала передача информации невозможна).
Дискриминантный анализ. Основная цель Дискриминантный анализ используется для принятия решения о том, какие переменные различают (дискриминируют) две или более возникающие совокупности (группы). Например, некий исследователь в области образования может захотеть исследовать, какие переменные относят выпускника средней школы к одной из трех категорий: (1) поступающий в колледж, (2) поступающий в профессиональную школу или (3) отказывающийся от дальнейшего образования или профессиональной подготовки. Для этой цели исследователь может собрать данные о различных переменных, связанных с учащимися школы. После выпуска большинство учащихся естественно должно попасть в одну из названных категорий. Затем можно использовать Дискриминантный анализ для определения того, какие переменные дают наилучшее предсказание выбора учащимися дальнейшего пути.
Вычислительный подход. С вычислительной точки зрения дискриминантный анализ очень похож на дисперсионный анализ (см. раздел Дисперсионный анализ). Рассмотрим следующий простой пример. Предположим, что вы измеряете рост в случайной выборке из 50 мужчин и 50 женщин. Женщины в среднем не так высоки, как мужчины, и эта разница должна найти отражение для каждой группы средних (для переменной Рост). Поэтому переменная Рост позволяет вам провести дискриминацию между мужчинами и женщинами лучше, чем, например, вероятность, выраженная следующими словами: "Если человек большой, то это, скорее всего, мужчина, а если маленький, то это вероятно женщина".
Вы можете обобщить все эти доводы на менее "тривиальные" группы и переменные. Например, предположим, что вы имеете две совокупности выпускников средней школы - тех, кто выбрал поступление в колледж, и тех, кто не собирается это делать. Вы можете собрать данные о намерениях учащихся продолжить образование в колледже за год до выпуска. Если средние для двух совокупностей (тех, кто в настоящее время собирается продолжить образование, и тех, кто отказывается) различны, то вы можете сказать, что намерение поступить в колледж, как это установлено за год до выпуска, позволяет разделить учащихся на тех, кто собирается и кто не собирается поступать в колледж (и эта информация может быть использована членами школьного совета для подходящего руководства соответствующими студентами).
В завершение заметим, что основная идея дискриминантного анализа заключается в том, чтобы определить, отличаются ли совокупности по среднему какой-либо переменной (или линейной комбинации переменных), и затем использовать эту переменную, чтобы предсказать для новых членов их принадлежность к той или иной группе.
Дисперсионный анализ. Поставленная таким образом задача о дискриминантной функции может быть перефразирована как задача одновходового дисперсионного анализа (ANOVA). Можно спросить, в частности, являются ли две или более совокупности значимо отличающимися одна от другой по среднему значению какой-либо конкретной переменной. Для изучения вопроса о том, как можно проверить статистическую значимость отличия в среднем между различными совокупностями, вы можете прочесть раздел Дисперсионный анализ. Однако должно быть ясно, что если среднее значение определенной переменной значимо различно для двух совокупностей, то вы можете сказать, что переменная разделяет данные совокупности.
В случае одной переменной окончательный критерий значимости того, разделяет переменная две совокупности или нет, дает F-критерий. Как описано в разделах Элементарные понятия статистики и Дисперсионный анализ, F статистика по существу вычисляется, как отношение межгрупповой дисперсии к объединенной внутригрупповой дисперсии. Если межгрупповая дисперсия оказывается существенно больше, тогда это должно означать различие между средними.
Многомерные переменные. При применении дискриминантного анализа обычно имеются несколько переменных, и задача состоит в том, чтобы установить, какие из переменных вносят свой вклад в дискриминацию между совокупностями. В этом случае вы имеете матрицу общих дисперсий и ковариаций, а также матрицы внутригрупповых дисперсий и ковариаций. Вы можете сравнить эти две матрицы с помощью многомерного F-критерия для того, чтобы определить, имеются ли значимые различия между группами (с точки зрения всех переменных). Эта процедура идентична процедуре Многомерного дисперсионного анализа (MANOVA). Так же как в MANOVA, вначале можно выполнить многомерный критерий, и затем, в случае статистической значимости, посмотреть, какие из переменных имеют значимо различные средние для каждой из совокупностей. Поэтому, несмотря на то, что вычисления для нескольких переменных более сложны, применимо основное правило, заключающееся в том, что если вы производите дискриминацию между совокупностями, то должно быть заметно различие между средними. В начало
Пошаговый дискриминантный анализ Вероятно, наиболее общим применением дискриминантного анализа является включение в исследование многих переменных с целью определения тех из них, которые наилучшим образом разделяют совокупности между собой. Например, исследователь в области образования, интересующийся предсказанием выбора, который сделают выпускники средней школы относительно своего дальнейшего образования, произведет с целью получения наиболее точных прогнозов регистрацию возможно большего количества параметров обучающихся, например, мотивацию, академическую успеваемость и т.д.
Модель. Другими словами, вы хотите построить "модель", позволяющую лучше всего предсказать, к какой совокупности будет принадлежать тот или иной образец. В следующем рассуждении термин "в модели" будет использоваться для того, чтобы обозначать переменные, используемые в предсказании принадлежности к совокупности; о неиспользуемых для этого переменных будем говорить, что они "вне модели".
Пошаговый анализ с включением. В пошаговом анализе дискриминантных функций модель дискриминации строится по шагам. Точнее, на каждом шаге просматриваются все переменные, и находится та из них, которая вносит наибольший вклад в различие между совокупностями. Эта переменная должна быть включена в модель на данном шаге, и происходит переход к следующему шагу.
Пошаговый анализ с исключением. Можно также двигаться в обратном направлении, в этом случае все переменные будут сначала включены в модель, а затем на каждом шаге будут устраняться переменные, вносящие малый вклад в предсказания. Тогда в качестве результата успешного анализа можно сохранить только "важные" переменные в модели, то есть те переменные, чей вклад в дискриминацию больше остальных.
F для включения, F для исключения. Эта пошаговая процедура "руководствуется" соответствующим значением F для включения и соответствующим значением F для исключения. Значение F статистики для переменной указывает на ее статистическую значимость при дискриминации между совокупностями, то есть, она является мерой вклада переменной в предсказание членства в совокупности. Если вы знакомы с пошаговой процедурой множественной регрессии, то вы можете интерпретировать значение F для включения/исключения в том же самом смысле, что и в пошаговой регрессии.
Расчет на случай. Пошаговый дискриминантный анализ основан на использовании статистического уровня значимости. Поэтому по своей природе пошаговые процедуры рассчитывают на случай, так как они "тщательно перебирают" переменные, которые должны быть включены в модель для получения максимальной дискриминации. При использовании пошагового метода исследователь должен осознавать, что используемый при этом уровень значимости не отражает истинного значения альфа, то есть, вероятности ошибочного отклонения гипотезы H0 (нулевой гипотезы, заключающейся в том, что между совокупностями нет различия). В начало
Интерпретация функции дискриминации для двух групп Для двух групп дискриминантный анализ может рассматриваться также как процедура множественной регрессии (и аналогичная ей) С вычислительной точки зрения все эти подходы аналогичны. Если вы кодируете две группы как 1 и 2, и затем используете эти переменные в качестве зависимых переменных в множественной регрессии, то получите результаты, аналогичные тем, которые получили бы с помощью Дискриминантного анализа. В общем, в случае двух совокупностей вы подгоняете линейное уравнение следующего типа:
Группа = a + b1*x1 + b2*x2 +... + bm*xm,
где a является константой, и b1...bm являются коэффициентами регрессии. Интерпретация результатов задачи с двумя совокупностями тесно следует логике применения множественной регрессии: переменные с наибольшими регрессионными коэффициентами вносят наибольший вклад в дискриминацию.
Дискриминантные функции для нескольких групп. Если имеется более двух групп, то можно оценить более чем одну дискриминантную функцию подобно тому, как это было сделано ранее. Например, когда имеются три совокупности, вы можете оценить: (1) - функцию для дискриминации между совокупностью 1 и совокупностями 2 и 3, взятыми вместе, и (2) - другую функцию для дискриминации между совокупностью 2 и совокупности 3. Например, вы можете иметь одну функцию, дискриминирующую между теми выпускниками средней школы, которые идут в колледж, против тех, кто этого не делает (но хочет получить работу или пойти в училище), и вторую функцию для дискриминации между теми выпускниками, которые хотят получить работу против тех, кто хочет пойти в училище. Коэффициенты b в этих дискриминирующих функциях могут быть проинтерпретированы тем же способом, что и ранее.
Канонический анализ. Когда проводится дискриминантный анализ нескольких групп, вы не должны указывать, каким образом следует комбинировать группы для формирования различных дискриминирующих функций. Вместо этого, вы можете автоматически определить некоторые оптимальные комбинации переменных, так что первая функция проведет наилучшую дискриминацию между всеми группами, вторая функция будет второй наилучшей и т.д. Более того, функции будут независимыми или ортогональными, то есть их вклады в разделение совокупностей не будут перекрываться. С вычислительной точки зрения система вы проводите анализ канонических корреляций (см. также раздел Каноническая корреляция), которые будут определять последовательные канонические корни и функции. Максимальное число функций будет равно числу совокупностей минус один или числу переменных в анализе в зависимости от того, какое из этих чисел меньше.
Интерпретация дискриминантных функций. Как было установлено ранее, вы получите коэффициенты b (и стандартизованные коэффициенты бета) для каждой переменной и для каждой дискриминантной (теперь называемой также и канонической) функции. Они могут быть также проинтерпретированы обычным образом: чем больше стандартизованный коэффициент, тем больше вклад соответствующей переменной в дискриминацию совокупностей. (Отметим также, что вы можете также проинтерпретировать структурные коэффициенты; см. ниже.) Однако эти коэффициенты не дают информации о том, между какими совокупностями дискриминируют соответствующие функции. Вы можете определить характер дискриминации для каждой дискриминантной (канонической) функции, взглянув на средние функций для всех совокупностей. Вы также можете посмотреть, как две функции дискриминируют между группами, построив значения, которые принимают обе дискриминантные функции (см., например, следующий график).
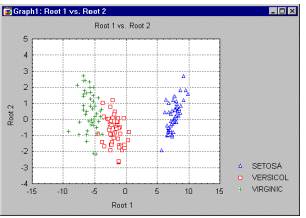
В этом примере Корень1 (root1), похоже, в основном дискриминирует между группой Setosa и объединением групп Virginic и Versicol. По вертикальной оси (Корень2) заметно небольшое смещение точек группы Versicol вниз относительно центральной линии (0).
Матрица факторной структуры. Другим способом определения того, какие переменные "маркируют" или определяют отдельную дискриминантную функцию, является использование факторной структуры. Коэффициенты факторной структуры являются корреляциями между переменными в модели и дискриминирующей функцией. Если вы знакомы с факторным анализом (см. раздел Факторный анализ), то можете рассматривать эти корреляции как факторные нагрузки переменных на каждую дискриминантную функцию.
Некоторые авторы согласны с тем, что структурные коэффициенты могут быть использованы при интерпретации реального "смысла" дискриминирующей функции. Объяснения, даваемые этими авторами, заключаются в том, что: (1) - вероятно структура коэффициентов более устойчива и (2) - они позволяют интерпретировать факторы (дискриминирующие функции) таким же образом, как и в факторном анализе. Однако последующие исследования с использованием метода Монте-Карло (Барсиковский и Стивенс (Barcikowski, Stevens, 1975); Хьюберти (Huberty, 1975)) показали, что коэффициенты дискриминантных функций и структурные коэффициенты почти одинаково нестабильны, пока значение размер выборки не станет достаточно большим (например, если число наблюдений в 20 раз больше, чем число переменных). Важно помнить, что коэффициенты дискриминантной функции отражают уникальный (частный) вклад каждой переменной в отдельную дискриминантную функцию, в то время как структурные коэффициенты отражают простую корреляцию между переменными и функциями. Если дискриминирующей функции хотят придать отдельные "осмысленные" значения (родственные интерпретации факторов в факторном анализе), то следует использовать (интерпретировать) структурные коэффициенты. Если же хотят определить вклад, который вносит каждая переменная в дискриминантную функцию, то используют коэффициенты (веса) дискриминантной функции.
Значимость дискриминантной функции. Можно проверить число корней, которое добавляется значимо к дискриминации между совокупностями. Для интерпретации могут быть использованы только те из них, которые будут признаны статистически значимыми. Остальные функции (корни) должны быть проигнорированы.
Итог. Итак, при интерпретации дискриминантной функции для нескольких совокупностей и нескольких переменных, вначале хотят проверить значимость различных функций и в дальнейшем использовать только значимые функции. Затем, для каждой значащей функции вы должны рассмотреть для каждой переменной стандартизованные коэффициенты бета. Чем больше стандартизованный коэффициент бета, тем большим является относительный собственный вклад переменной в дискриминацию, выполняемую соответствующей дискриминантной функцией. В порядке получения отдельных "осмысленных" значений дискриминирующих функций можно также исследовать матрицу факторной структуры с корреляциями между переменными и дискриминирующей функцией. В заключение, вы должны посмотреть на средние для значимых дискриминирующих функций для того, чтобы определить, какие функции и между какими совокупностями проводят дискриминацию.
Предположения Как говорилось ранее, дискриминантный анализ в вычислительном смысле очень похож на многом

