2014-02-24
2014-02-24 725
725В основе алгоритма RLE лежит идея выявления повторяющихся последовательностей данных и замены их более простой структурой, в которой указывается код данных и коэффициент повторения. Например, пусть задана такая последовательность данных, что подлежит сжатию:
1 1 1 1 2 2 3 4 4 4
В алгоритме RLE предлагается заменить ее следующей структурой: 1 4 2 2 3 1 4 3, где первое число каждой пары чисел - это код данных, а второе - коэффициент повторения. Если для хранения каждого элемента данных входной последовательности отводится 1 байт, то вся последовательность будет занимать 10 байт памяти, тогда как выходная последовательность (сжатый вариант) будет занимать 8 байт памяти. Коэффициент сжатия, характеризующий степень сжатия, можно вычислить по формуле:
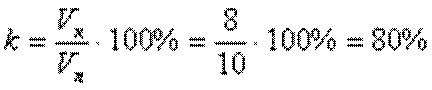
где Vx- объем памяти, необходимый для хранения выходной (результирующей) последовательности данных, Vn- входной последовательности данных.
Чем меньше значение коэффициента сжатия, тем эффективней метод сжатия. Понятно, что алгоритм RLE будет давать лучший эффект сжатия при большей длине повторяющейся последовательности данных. В случае рассмотренного выше примера, если входная последовательность будет иметь такой вид: 1 1 1 1 1 1 3 4 4 4, то коэффициент сжатия будет равен 60%. В связи с этим большая эффективность алгоритма RLE достигается при сжатии графических данных (в особенности для однотонных изображений).