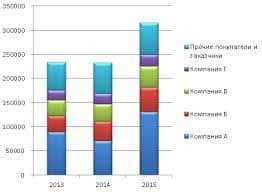
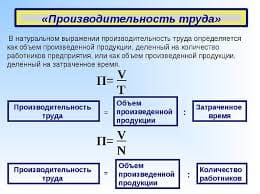
2015-02-24
2015-02-24 677
677Алгоритм Р. Бойера и Дж. Мура по сравнению с линейным поиском требует значительно меньших временных затрат.
Основная идея
Поиск ведется от начала строки s, но с конца искомой подстроки x, для которой формируется таблица, размерность которой равна 256 - количеству всех символов в машинном алфавите. В таблице записываются расстояния от последнего символа искомой подстроки x до каждого ее символа. (Если в x встречаются одинаковые символы, то в таблицу заносится расстояние до ближайшего из них.) Если символ не входит в x, то в соответствующую ячейку таблицы заносится m - длина подстроки x. Когда очередной символ подстроки не совпадает с очередным символом строки s, для последнего из таблицы определяется расстояние, после чего x
сдвигается вправо на соответствующее число позиций. Тем самым ряд позиций пропускается, время поиска сокращается.
Пример
Пусть s = ’Мила мало мылась мылом’, x =’ мыло’.
Длина x равна 4. Составим таблицу расстояний.


 М Ы Л О
М Ы Л О
 1
1
 2
2
 3
3
Расстояние до символа равно m-j, где j - индекс этого символа, а m - длина строки x.
Таблица расстояний (sd) выглядит так:
| Символ | Расстояние |
| ... А ... К Л М Н О П ... Ъ Ы Ь ... | ... ... 1 3 ... 2 ... |
Для всех символов, кроме выделенных, расстояние равно 4.
Будем выделять из строки s фрагменты длиной m и сравнивать их последовательно, начиная с конца, с соответствующими символами строки x. Пусть j - номер обрабатываемого символа строки x. Чтобы определить номер соответствующего символа s, нужно знать, с какой позиции начинается рассматриваемый фрагмент строки s. Обозначим через i номер символа, предшествующего первому символу обрабатываемого фрагмента. Тогда номер символа во фрагменте строки s, соответствующего j-му символу x, определяется как i+j.
1-й шаг
i = 0, m = 4. Рассмотрим первые 4 символа s и строку x. Начнем сравнивать их с конца. Для j = 4 s [ i+j ] ¹ x [ j ] (s[4] ¹ x[4]). Следовательно, далее можно не сравнивать, поскольку можно уже сказать, что этот фрагмент строки s не может являться искомой подстрокой (имеется по крайней мере одно несовпадение). Поэтому перейдем к следующему фрагменту.
2-й шаг
Теперь надо определить номер первого символа нового фрагмента. Для этого заметим, что так как последнего символа фрагмента s (‘A’) в x нет, то фрагменты со 2-го, 3-го, 4-го символов s можно не рассматривать, а нужно сразу перейти к фрагменту с позиции 5. В этом случае новое значение i получится прибавлением к старому значению sd [ ‘A’ ].
Таким образом, новый фрагмент строки s - ‘ мал’. Начинаем новые сравнения с конца. Так как ‘Л’ ¹ ‘О’, этот фрагмент снова можно далее не рассматривать.
3-й шаг
Поскольку символ ‘Л’ в искомой строке есть, то он может являться предпоследним. Следовательно, новое значение i = 5 (определяется как 4+sd [‘Л’] = 4+1). Рассматриваем ‘МАЛО’ и ‘МЫЛО’: s [ 9 ] = x [ 4 ], s [ 8 ] = x [ 3 ], s [ 7 ] ¹ x [ 2 ] (‘А’¹’Ы’), значит, и этот фрагмент строки s не является искомым.
4-й шаг
Четвертый фрагмент (i = 9) ‘МЫЛ’ (см. 2-й шаг) снова не совпадает с x.
5-й шаг
Для следующего фрагмента значение i = 9+sd [‘Л’] =10. После первого сравнения можно сказать, что этот фрагмент тоже не подходит.
6-й шаг
i =14. Фрагмент ‘СЬ М’ пропускаем после первого сравнения.
7-й шаг
i =17 (14+sd [‘М’] =14+3). Сравниваем ‘МЫЛО’ и ‘МЫЛО’:
Искомая подстрока найдена с позиции 18.
Задача решена.
Программа, реализующая этот алгоритм, выглядит так:
Program n11;var s,x: string; sd: array[0..255] of integer;Procedure search(s,x: string);var i,j,n,m: integer; f: boolean; h: char;begin n:=length(s); { Определение длин строки и подстроки } m:=length(x); { Начальное заполнение массива расстояний }
for i:=0 to 255 do sd[i]:=m;
for i:=1 To m-1 do { Заполнение массива расстояний }
begin
h:=x[i];
sd[ord(h)]:=m-i;
end;
i:=1; f:=False; { Признак того, что подстрока найдена}
while (i<n-m+1) and (not f) do
begin
j:=m;
while (j>0) and (s[i+j]=x[j]) do j:=j-1;
if j=0 then f:=true { Полное совпадение! }
else i:=i+sd[ord(s[i+j])];
end;
if f then writeln(x,' - является подстрокой ',s,' с позиции ',i+1)
else writeln('нет вхождения');
end;
begin { Основная программа }
writeln('Введите строку s:');
readln(s);
writeln('Введите подстроку x:');
readln(x);
search(s,x);
readln
end.