 2015-04-01
2015-04-01 861
861По результатам анализа применения различных методик взвешивания различными исследователями, в нашей работе была предложена модель взвешивания, которая включает в себя несколько альтернативных схем. Можно выделить условия, которым должна удовлетворять данная модель:
1) Необходимо использовать модель взвешивания, учитывающую последующее преобразование матрицы в блоке определения семантической близости (см. архитектуру системы)
2) Модель взвешивания должна удовлетворять выбранному методу блока кластеризации (см. архитектуру системы)
3) Должны быть предусмотрены несколько схем взвешивания, для работы в различных скоростных режимах, то есть с разной вычислительной сложностью
4) Модель взвешивания должна базироваться на эффективных апробированных схемах, для обеспечения качества результатов
5) Модель должна иметь универсальность, в смысле тем, размеров и характера обрабатываемых текстов
Как видно из условий, некоторые ограничения, накладываемые на модель, определяются методами других блоков системы. Например, некоторые способы повышения эффективности взвешивания (порядка 2-5%), описанные в работе шанкара и кариписа, были сочтены неприемлемыми для блока определения семантической близости.
Поскольку в нашей работе используется латентная семантическая индексация, то итеративный метод корректировки весов может повлечь дополнительную потерю информации и излишние временные затраты.
С другой стороны схемы взвешивания, предложенные салтоном, бакли и алланом, используют схему нормализации. Этот подход удовлетворяет выбранной в блоке кластеризации мере косинуса в качестве меры взаимного сходства и, таким образом, уменьшает вычислительные затраты на последующих этапах работы.
Для обеспечения различной скорости обработки документов в зависимости от характера задачи, решено остановится на модели, состоящей из трех схем взвешивания:
1) Нормализованное по частоте. Данная схема является простейшей, не учитывающей взаимосвязи между документами. Она необходима для оценки результатов работы других схем и обеспечения общности модели:
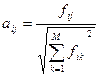
По таксономии предложенной Кольдой Т., схема обозначается txn.txn.
2) TFC взвешивание. Это модификация tf×idf взвешивания, учитывающая то обстоятельство, что документы могут иметь различную длину. Взвешивание tfc дополнительно включает нормализацию длин документов:
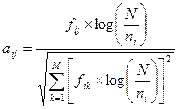 ,
,
с обозначением tfn.tfn.
3) Энтропийное взвешивание. Как было сказано выше, это взвешивание основывается на предпосылках теории информации и является довольно сложной схемой взвешивания. В экспериментальных работах [34,35] показано, что данный подход является наиболее эффективным, применительно ко многим задачам. Его достоинство еще в том, что он показал высокую эффективность в задачах с использованием латентной семантической индексации:
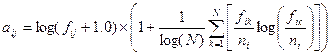
с обозначением len.len.
Критика последней схемы взвешивания приведенная в работе [54], на наш взгляд недостаточно убедительна, так как эксперименты проведены на нестандартной выборке документов, относительно малого размера.
Следует отметить, что любой выбор модели будет иметь характер исследовательской задачи, так как нет стандартизированных корпусов русскоязычных текстов, для объективной оценки результатов. Все схемы сравнивались на англоязычных текстах, что не гарантирует аналогичных результатов применительно к русскому языку.
Требование универсальности модели ограничивает применение модифицированных моделей, разработанных для конкретных систем. Тем не менее, есть особенность модели, которая характерна именно для нашей задачи. Все схемы нормализованы, что приводит к оптимизации вычисления семантической близости. Используя, полученные в результате латентного семантического анализа вектора документов, мы вычисляем их близость, при помощи меры косинуса. Для векторов документов x и y скалярное произведение равно:
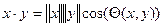 .
.
Если вектора нормализованы, т.е. 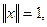
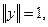 тогда
тогда
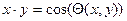 .
.
Нормализация в модели взвешивания избавляет нас от необходимости каждый раз вычислять длины векторов, при определении семантической близости документов.
На основе данной модели базируется создание и тестирование прототипа модуля взвешивания. В дальнейшем планируется экспериментальная проверка гипотез об эффективности модели для нашей задачи.
Разработка методики экспериментов является отдельной сложной задачей, поскольку нет информации о наличии стандартного корпуса документов, размеченного для анализа эффективности информационного поиска.








