 2015-04-08
2015-04-08 7490
7490Стратегии борьбы с ошибками:
— использование корректирующих кодов или кодами с исправлением ошибок (error-correcting codes), прямое исправление ошибок FEC.
— коды с обнаружением ошибок (error-detecting codes).
Для того чтобы определить, какой метод лучше подойдет в конкретной ситуации, нужно понять, какой тип ошибок более вероятен. Ни код с исправлением ошибок, ни код с обнаружением ошибок не позволят справиться со всеми возможными ошибками, поскольку лишние биты, передаваемые для повышения надежности, также могут быть повреждены в пути.
Коды с исправлением ошибок добавляют к пересылаемой информации избыточные данные. Кадр состоит из m бит данных (то есть информационных бит) и r избыточных или контрольных бит.
Набор из n бит, содержащий информационные и контрольные биты, часто называют n-битовым кодовым словом. Кодовая норма — это часть кодового слова, несущая неизбыточную информацию, или m/n. Количество бит, которыми отличаются два кодовых слова, называется кодовым расстоянием или расстоянием между кодовыми комбинациями в смысле Хэмминга. Смысл этого числа состоит в том, что если два кодовых слова находятся на кодовом расстоянии d, то для преобразования одного кодового слова в другое понадобится d ошибок в одиночных битах.
1. Коды Хэмминга биты кодового слова нумеруются последовательно слева направо, начиная с 1. Биты с номерами, равными степеням 2 (1, 2, 4, 8, 16 и т. д.), являются контрольными. Остальные биты (3, 5, 6, 7, 9, 10 и т. д.) заполняются m битами данных. 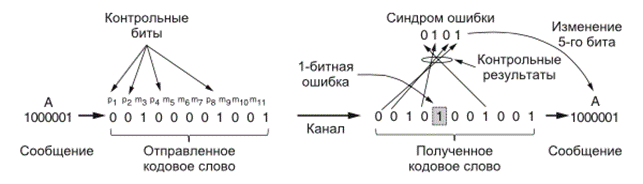
Каждый контрольный бит обеспечивает сумму по модулю 2 или четность некоторой группы бит, включая себя самого. Один бит может входить в несколько вычислений контрольных бит. Чтобы определить, в какие группы контрольных сумм будет входить бит данных в k-й позиции, следует разложить k по степеням числа 2. Например, 11 = 8 + 2 + 1, а 29 = 16 + 8 + 4 + 1. Каждый бит проверяется только теми контрольными битами, номера которых входят в этот ряд разложения (например, 11-й бит проверяется битами 1, 2 и 8). В нашем примере контрольные биты вычисляются для проверки на четность в сообщении, представляющем букву «A» в кодах ASCII.
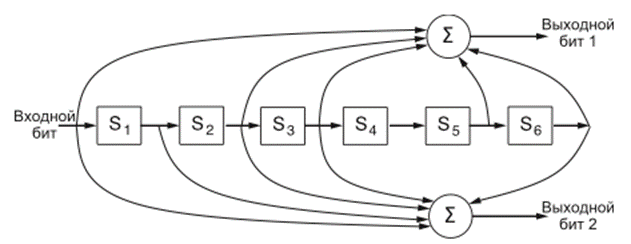
2. Двоичные сверточные коды не относятся к блочному типу и применяется в развернутых сетях (GSM, 802.11). Кодировщик обрабатывает последовательность входных бит и генерирует последовательность выходных бит. В отличие от блочного кода, ни- какие ограничения на размер сообщения не накладываются, также не существует грани кодирования. начение выходного бита зависит от значения текущего и предыдущих входных бит — если у кодировщика есть возможность использовать память. Число предыдущих бит, от которого зависит выход, называется длиной кодового ограничения для данного кода. Сверточные коды были очень популярны для практического применения, так как в декодировании очень легко учесть неопределенность значения бита (0 или 1). Например, предположим, что –1 В соответствует логическому уровню 0, а +1 В соот- ветствует логическому уровню 1. Мы получили для двух бит значения 0,9 В и –0,1 В. Вместо того чтобы сразу определять соответствие — 1 для первого бита и 0 для вто- рого, — можно принять 0,9 В за «очень вероятную единицу», а –0,1 В за «возможный нуль» и скорректировать всю последовательность. Для более надежного исправления ошибок к неопределенностям можно применять различные расширения алгоритма Витерби. Такой подход к обработке неопределенности значения бит называется деко- дированием с мягким принятием решений (soft-decision decoding). И наоборот, если мы решаем, какой бит равен нулю, а какой единице, до последующего исправления ошибок, то такой метод называется декодированием с жестким принятием решений (hard-decision decoding).
3. Коды Рида—Соломона (используются в сетях DSL, для исправления ошибок н DVD и Blu-ray дисках) основываются на том, что каждый многочлен n-й степени уникальным образом определяется n + 1 точкой. Например, если линия задается формулой ax + b, то восстановить ее можно по двум точкам. Коды Рида—Соломона определяются как многочлены на конечных полях. Для m-битовых символов длина кодового слова составляет 2m – 1 символов. Очень часто выбирают значение m = 8, то есть одному символу соответствует один байт. Тогда длина кодового слова — 255 байт. Широко используется код (255,233), он добавляет 32 дополнительных символа к 233 символам данных. Декодирование с исправлением ошибок выполняется при помощи алгоритма Берлекэмпа—Мэсси, который осуществляет подгонку для кодов средней длины. При добавлении 2t избыточных символов код Рида—Соломона способен исправить до t ошибок в любом из переданных символов. Это означает, например, что код (255,233) с 32 избыточными символами исправляет до 16 ошибок. Так как символы могут быть последовательными, а размер их обычно составляет 8 бит, то возможно исправление последовательных ошибок в 128 битах. Коды Рида—Соломона часто используют в сочетании с другими кодами, например сверточными. Сверточные коды эффективно обрабатывают изолированные однобитные ошибки, но с последовательностью ошибок они не справятся, особенно если ошибок в полученном потоке бит слишком много. Добавив внутрь сверточного кода код Рида—Соломона, вы сможете очистить поток бит от последовательностей ошибок.
4. Коды с малой плотностью проверок на четность (LDPC) — это линейные блочные коды, изобретенные Робертом Галлагером. В коде LDPC каждый выходной бит формируется из некоторого подмножества входных бит. Это приводит нас к матричному представлению кода с низкой плотностью единиц. Полученные кодовые слова декодируются алгоритмом аппроксимации, который последовательно улучшает наилучшее приближение, составленное из полученных данных, пока не получает допустимое кодовое слово. Так осуществляется устранение ошибок. Коды LDPC удобно применять для блоков большого размера. По этой причине коды LDPC быстро добавляются в новые протоколы. Они являются частью стандарта цифрового телевидения, сетей Ethernet 10 Гбит/с, сетей, работающих по линиям электропитания, а также последней версии 802.11.
Коды с обнаружением ошибок:
1. Код с проверкой на четность.
К отправляемым данным присоединяется бит четности (parity bit), который выбирается так, чтобы число единичных битов в кодовом слове было четным (или нечетным). Для повышения защиты от последовательностей ошибок — биты четности вычисляют не в порядке отправки данных — чередование.

