 2015-04-30
2015-04-30 3628
36281. Создайте новый проект и сохраните его под именем L1_2.ded.
2. Создайте и сохраните под именем prim.txt в любом текстовом редакторе следующий файл:
a,1,4.5,b,c,26/04/2013,d,12:35 a1,0,5,b1,c1,d1
3. Импортируйте его в Deductor, корректно настроив параметры импорта:
а) Запустите Мастер импорта и выберите Файл данных ► Text и нажмите кнопку Далее.
б) На шаге Указание имени файла, нажав кнопку  , необходимо выбрать имя текстового файла (расширения *.txt, *.csv), из которого следует выполнить импорт данных (файл prim.txt).
, необходимо выбрать имя текстового файла (расширения *.txt, *.csv), из которого следует выполнить импорт данных (файл prim.txt).
Имеется возможность использовать как абсолютные, так и относительные пути для файлов.
Они указываются относительно текущей директории Deductor. При открытии Deductor текущей директорией является директория файла проекта. Поэтому, если файл проекта и текстовые файлы располагаются в одной папке, то использование относительных путей в Мастере импорта позволит не перенастраивать узлы импорта при изменении расположения папки на жестком диске.
Здесь также доступны настройки:
– Начать импорт со строки – номер строки, начиная с которой будет делаться импорт данных из файла (укажите 1).
– флажок Первая строка является заголовком – установка флажка означает, что узел будет импортировать данные с учетом того, что все записи первой строки являются заголовками столбцов (убрать флажок).
– Кодировка – ANSI (Windows) или ANCII (MS DOS).
в) На шаге Настройка форматов импорта нужно настроить параметры импорта данных из текстового файла, так как существует несколько форматов структурированных текстовых файлов. Доступные опции:
– переключатель Формат исходных данных, который определяет символ-разделитель в файле (например: символ табуляции, пробел, запятая).
Разделитель чаще всего присутствует. Если же нет, то нужно выбрать переключатель Фиксированной ширины (поля имеют заданную ширину), а далее – установить ширину каждого поля (выбрать С разделителями);
– Ограничитель строк – при задании данного параметра необходимо указать, какой именно ограничитель строкового значения нужно использовать при импорте данных из текстового файла. Обычно таким ограничителем является символ двойной кавычки ".
– Разделитель дробной и целой части числа – при задании данного параметра необходимо указать символ, разделяющий дробную и целую части в числовых значениях, содержащихся в файле (поставьте символ.).
– Разделитель компонентов даты – указывается символ, разделяющий компоненты даты в соответствующих значениях, содержащихся в файле (поставьте символ «/»).
– Разделитель компонентов времени – указывается символ, разделяющий компоненты времени в соответствующих значениях, содержащихся в файле (поставьте символ «:»).
– Форматы Даты/Времени – указываются форматы даты/времени, используемые в импортируемом файле (дата – dd/mm/yyyy, время – h:mm).
– Представление значений – опция для полей логического типа, которое может принимать одно из трех значений – Истина (True), Ложь (False) и пустое значение (null); оопределяет регламент записи в эти значения. Так, при настройках по умолчанию для любого логического поля, значение Да будет восприниматься как истина, Нет – как ложь.
г) Следующее окно Мастера зависит от установленного переключателя в флажке Формат исходных данных. Если был выбран формат С разделителями, то появится вкладка, на которой нужно явно указать символ-разделитель (указать – запятая). Здесь же находится флажок Считать последовательные разделители одним (флажок снять – в случае последовательно идущих символов-разделителей они будут восприниматься за один. Такое бывает, например, когда символом-разделителем выступают несколько пробелов (рис. 1.6).
Если был выбран флажок Формат фиксированной ширины, то появится вкладка, на которой нужно задать границы каждого поля. Создание, как и удаление маркера границы, производится одним щелчком мыши. Двигая маркеры границ столбцов, можно изменять их, если они расставлены неправильно. Данные, распределенные по столбцам,
показываются в области предварительного просмотра (Вернуться на шаг назад, установить флажок Фиксированной ширины, посмотреть результат и вернуть все назад).
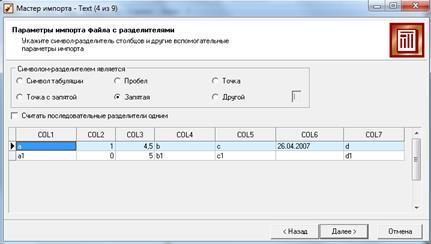
Рисунок 1.6 – Окно Мастера импорта
(параметры импорта файла с разделителями)
д) На шаге Настройка параметров столбцов нужно настроить следующие параметры столбцов импортируемых данных, указав соответствующие значения в полях (изменить названия столбцов соответственно типу данных).
– Имя столбца – указывается имя, которое будет служить идентификатором столбца в последующих узлах. По умолчанию предлагается заголовок столбца из текстового файла, если на предыдущем шаге был установлен флажок Первая строка является заголовком.
Иначе будут предложены имена типа COL1, COL2 и т.д. Можно ввести любые имена, которые семантически отражают содержимое столбца, однако допускаются только латинские символы, и имя столбца должно быть уникальным в пределах всех столбцов импортируемого файла.
– Метка столбца – название, под которым данный столбец будет виден в визуализаторах. Допускаются любые символы, уникальность имен не обязательна.
– Тип данных – указывается тип данных, содержащихся в столбце. Тип выбирается из списка, открываемого щелчком по кнопке в правой части поля:
§ логический – данные в поле могут принимать только два значения – 0 или 1;
§ дата/время – поле содержит данные типа дата/время;
§ вещественный – числа с плавающей точкой;
§ целый – целые числа;
§ строковый – строки символов;
– Вид данных – характер данных, содержащихся в столбце:
§ непрерывный – цифры в столбце могут принимать любое значение в рамках своего типа (только числовые данные);
§ дискретный – данные в столбце могут принимать ограниченное число значений (строковые);
– Назначение – определяет порядок использования поля набора данных, полученного в результате импорта:
е) На шаге Запуск процесса импорта стартует сам процесс импорта данных с ранее настроенными параметрами. Ход процесса импорта отображается с помощью индикатора. Если процесс импорта остановился, это сигнализирует о возможных ошибках при чтении данных. В этом случае появляется окно с сообщением об ошибке (нажать Пуск).
ж) На следующем шаге выбрать визуализатор набора данных (выбрать
Таблица).
з) На последнем шаге можно задать сведения о проекте (используйте относительный путь для файла; метку узла переименуйте в Пример импорта файла; в комментарии к узлу впишите: Текстовый файл с разделителями- запятыми) (рис. 1.7).
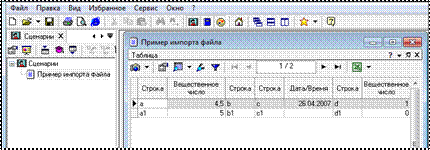
Рисунок 1.7 – Пример импорта файла
4. Добавьте в сценарий узел Настройка набора данных (тот же файл prim.txt) и задайте следующие метки к столбцам: Поле1, Поле2, Поле3 и т.д. (рис. 1.8).
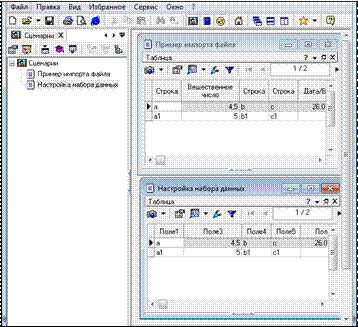
Рисунок 1.8 – Настройка набора данных
5. Экспортируйте (используйте Мастер экспорта) набор данных в текстовый файл с настройками, предлагаемыми по умолчанию (появится файл export.txt).
6. Импортируйте только что экспортированный файл в Deductor (узел –
Пример импорта файла 2) (рис. 1.9).
7. Для изменения параметров используется узел Настройка набора данных (Мастер обработки ► Трансформация данных ► Настройка набора данных).
Обработчик Настройка набора данных позволяет:
– изменить имя, метку, тип, вид и назначение полей текущего набора данных;
– изменить порядок следования столбцов в наборе данных;
– скрыть столбцы набора данных;
– задать опцию кэширования выходного набора.
8. Перед узлом Экспорт Text (export.txt) в ветви Настройка набора данных вставьте еще один узел настройки (Настройка набора данных (Поле2)), в котором измените тип столбца Поле2 на логический (рис. 1.10).
9. Удалите только что вставленный узел.
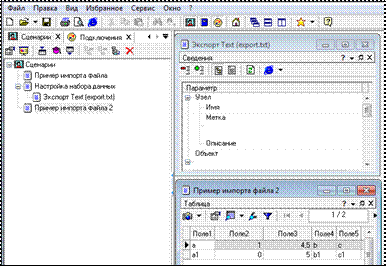
Рисунок 1.9 – Экспорт/импорт набора данных
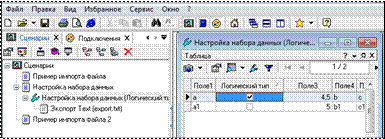
Рисунок 1.10 – Настройка набора данных
10. Сохраните проект в файле L1_2.ded.

