 2015-04-23
2015-04-23 1665
1665Среди причин, побуждающих компании к реализации прокетов по внедрению информационных систем на основе хранилищ данных:
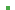
| Невозможность доступа к информации в разумное/требуемое условиями бизнес-процессов время. Аналитики и руководители не получают нужную информацию. |
|
| Недостоверность информации. Требуется много времени и усилий на проверку достоверности. |
|
| Неполнота информации. Не поступает информация по некоторым показателям или, в случае распределенных структур, только по ограниченному числу филиалов. |
Очевидно, что хранилища данных и системы бизнес-анализа позволяют повысить уровень конкурентоспособности компании за счет обеспечения менеджеров и аналитиков своевременным доступом к достоверной информации (возможно, знаниям). Однако это не дает оснований говорить о технологиях и решениях, как об инвестициях в бизнес.
Аналитические информационные системы на основе хранилищ данных, позволяют существенно сократить время, требуемое для получения необходимой информации/знаний. Происходит сжатие времени, открывающее возможности для:
|
| Создания новых бизнес-процессов; |
|
| Ускорения существующих бизнес-процессов. Здесь подразумевается сокращение интервалов времени, после которых принимаются управляющие воздействия. |
От степени сжатия времени и бизнес-процесса напрямую зависит размер выгоды, определяемый в денежном эквиваленте. В качестве кратких примеров можно привести:
|
| Центры обработки вызовов. Доступ к информации об абоненте позволяет операторам проводить различные сценарии в общении с абонентами, в зависимости от его принадлежности к той или иной группе. Как результат √ сокращение издержек на содержание службы, увеличение оборота от продажи дополнительных услуг. |
|
| Выявление брака на ранних стадиях за счет более частого анализа претензий покупателей продукции. В результате сокращение расходов по гарантийным обязательствам. |
|
| Коррекция закупок на основе достоверной и своевременной информации об объемах продаж. |
|
| Оптимизация логистики за счет быстрого доступа к информации, предоставляемой распределенной сетью сбыта. |
|
| Сокращение интервалов пересмотра страховых премий поможет страховым компаниям повысить привлекательность услуг и избежать чрезмерных расходов по выплатам; |
|
| и пр. |
Таким образом, хранилища данных и аналитические системы, реализуя потенциал уже совершенных инвестиций (существующие информационные системы), открывают для компаний ПРОГНОЗИРУЕМЫЕ возможности по совершенствованию бизнеса.
На самом деле, основными причинами, побуждающими организации внедрять хранилища данных, являются:
|
| Необходимость выполнения аналитических запросов и генерации отчетов на не задействованных основными информационными системами вычислительных ресурсах. |
|
| Необходимость использования моделей данных и технологий, ускоряющих процесс выполнения запросов и подготовки отчетности, но не предназначенных для обработки транзакций. |
|
| Создание среды, в которой даже относительно небольших знаний основ СУБД достаточно для создания запросов и подготовки отчетов. Это означает сокращение времени, требуемого от персонала ИТ-департамента для сопровождения системы. |
|
| Создание источника с предварительно очищенной информацией. |
|
| Упрощение процесса подготовки отчетов на основе информации из нескольких транзакционных систем и/или внешних источников данных и/или данных, используемых исключительно для генерации отчетов. |
|
| Создание выделенного источника в тех случаях, когда возможности транзакционной системы не соответствует требуемому бизнесом сроку хранения данных и/или необходимо иметь возможность подготовки отчетов на определенные моменты времени в прошлом ("as was" reporting). |
|
| Защита конечных пользователей от необходимости в какой бы то ни было степени вникать в структуру и логику работы БД регистрирующей системы |
Применение OLAP технологий при извлечении данных
OLAP (Online Analyzing Processing) - это один из способов добычи и анализа данных. Суть заключается в том, что информация представляется в виде многомерного куба с возможностью произвольного манипулирования ею. По сухому описанию довольно трудно понять, зачем OLAP нужен и как он работает.
Общий принцип работы любой OLAP системы прост. Давайте вначале представим себе отчет в виде куба.
| Город | Товар | Январь | Февраль | Март | Итого |
| Москва | Утюг | ||||
| Пылесос | |||||
| Чайник | |||||
| Итого | |||||
| Рязань | Холодильник | ||||
| Чайник | |||||
| Телефон | |||||
| Итого | |||||
| Владивосток | Утюг | ||||
| Телефон | |||||
| Пылесос | |||||
| Итого |
На рисунке изображен 3-х мерный куб, хотя количество измерений особого значения не имеет. Просто 3 измерения легче представить. Теперь, если мы сложим значения во всех ячейка по вертикали, то получим следующий отчет.
| Город | Январь | Февраль | Март | Итого |
| Москва | ||||
| Рязань | ||||
| Владивосток | ||||
| Итого |
Вся работа с кубом, собственно, и сводится к различным его поворотам, группировкам. Можно менять количество измерений, способы группировки, но это не важно. Принципы совершенно одинаковы. И эти самые принципы порождают определенные проблемы. Дело в том, что при таком представлении данных работать с информацией легко и удобно, но куб очень быстро увеличивается в размерах. И для того, чтобы получить хороший результат, необходимо, чтобы на экран выводился не весь куб, а только нужная его часть. Для этого необходимо: во-первых, иметь возможность выбирать только те измерения, которые нас интересуют. Если вам все равно, в какой город продавался товар, то нужно с самого начала убрать измерение ╚город╩. Во-вторых, иметь возможность выбрать/отсечь ненужные значения. Например, если из всей номенклатуры интересуют только утюги и холодильники, нужно строить куб только для них.
Положительные и отрицательные стороны OLAP-технологии.
У любой технологии есть свои минусы и плюсы, и OLAP тоже не без греха. Во-первых, OLAP рассчитан в первую очередь на анализ процессов. Отгрузка, поступления, оплата √ это эму дается легко. Если вы хотите анализировать объекты, то лучше использовать другой инструментарий. Во-вторых, при работе с OLAP исходят из предположения, что вы четко знаете, какую информацию вы хотите получить из базы данных. OLAP - это прежде всего инструмент добычи информации. Если вам нужно получить ответы на нечетко поставленные вопросы, например, - отобрать 10 лучших клиентов, тут будут проблемы. Вам нужно использовать другие методы анализа, т.к. нет простого определения понятия хороших клиентов, а следовательно невозможно сформировать SQL запрос к базе данных, а SQL - это фундамент на котором все это работает. В-третьих, к OLAP нужно относиться осторожно. Вещь очень мощная, но может мгновенно загрузить все ресурсы сервера. Так что отсекайте как можно больше информации, а лучше строить отдельные хранилища данных. Это оптимальный вариант. Соберите информацию из разных источников, систематизируйте, влейте в хранилище и анализируйте. Вот тут OLAP-у будет где разгуляться. Создание хранилища данных - очень серьезная работа, но чудесного способа решения всех проблем с информацией не существует. Если ваши данные разбросаны где попало и не систематизированы, вам ничто не поможет. В целом, OLAP очень красивая, полезная и интересная технология. Если грамотно подходить к ее применению, то она принесет огромную пользу в вашей ежедневной работе.
Ядро OLAP системы. Часть 1 -- принципы построения
Механизм OLAP является на сегодня одним из популярных методов анализа данных. Есть два основных подхода к решению этой задачи. Первый из них называется Multidimensional OLAP (MOLAP) - реализация механизма при помощи многомерной базы данных на стороне сервера, а второй Relational OLAP (ROLAP) - построение кубов 'на лету' на основе SQL запросов к реляционной СУБД. Каждый из этих подходов имеет свои плюсы и минусы. Их сравнительный анализ выходит за рамки этой статьи. Мы же опишем нашу реализацию ядра настольного ROLAP модуля.
Такая задача возникла после применения ROLAP системы, построенной на основе компонентов Decision Cube, входящих в состав Borland Delphi. К сожалению, использование этого набора компонент показало низкую производительность на больших объемах данных. Остроту этой проблемы можно снизить, стараясь отсечь как можно больше данных перед подачей их для построения кубов. Но этого не всегда бывает достаточно.
В Интернете и прессе можно найти много информации об OLAP системах, но практически нигде не сказано о том, как это устроено внутри. Поэтому решение большинства проблем нам давалось методом проб и ошибок.
Схема работы
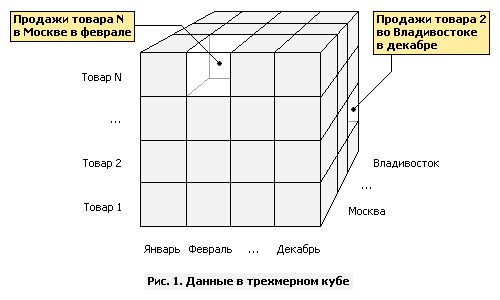
Общую схему работы настольной OLAP системы можно представить следующим образом:
Алгоритм работы следующий:
Получение данных в виде плоской таблицы или результата выполнения SQL запроса.
Кэширование данных и преобразование их к многомерному кубу.
Отображение построенного куба при помощи кросс-таблицы или диаграммы и т.п. В общем случае, к одному кубу может быть подключено произвольное количество отображений.
Теперь можно рассмотреть как подобная система может быть устроена внутри. Начнем это с той стороны, которую можно посмотреть и пощупать, то есть с отображений.
Отображения, используемые в OLAP системах, чаще всего бывают двух видов- кросс-таблицы и диаграммы. Рассмотрим кросс-таблицу, которая является основным и наиболее распространенным способом отображения куба.
Кросс-таблица
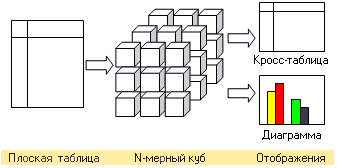
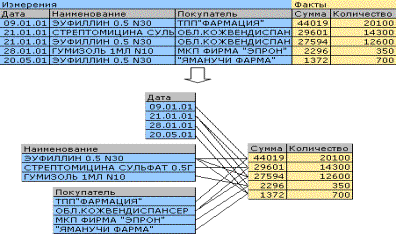
На приведенном ниже рисунке, желтым цветом отображены строки и столбцы, содержащие агрегированные результаты, светло-серым цветом отмечены ячейки, в которые попадают факты и темно-серым ячейки, содержащие данные размерностей.
Таким образом, таблицу можно разделить на следующие элементы, с которыми мы и будем работать в дальнейшем:
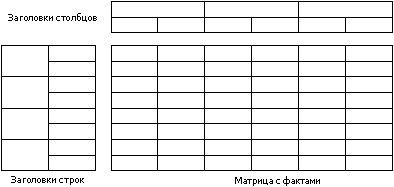
Заполняя матрицу с фактами, мы должны действовать следующим образом:
- На основании данных об измерениях определить координаты добавляемого элемента в матрице.
- Определить координаты столбцов и строк итогов, на которые влияет добавляемый элемент.
- Добавить элемент в матрицу и соответствующие столбцы и строки итогов.
При этом нужно отметить то, что полученная матрица будет сильно разреженной, почему ее организация в виде двумерного массива (вариант, лежащий на поверхности) не только нерациональна, но, скорее всего, и невозможна в связи с большой размерностью этой матрицы, для хранения которой не хватит никакого объема оперативной памяти. Например, если наш куб содержит информацию о продажах за один год, и если в нем будет всего 3 измерения √ Клиенты (250), Продукты (500) и Дата (365), то мы получим матрицу фактов следующих размеров:
Кол-во элементов = 250 х 500 х 365 = 45 625 000
И это при том, что заполненных элементов в матрице может быть всего несколько тысяч. Причем, чем больше количество измерений, тем более разреженной будет матрица.
Поэтому, для работы с этой матрицей нужно применить специальные механизмы работы с разреженными матрицами. Возможны различные варианты организации разреженной матрицы. Они довольно хорошо описаны в литературе по программированию, например, в первом томе классической книги "Искусство программирования" Дональда Кнута.
Рассмотрим, как можно определить координаты факта, зная соответствующие ему измерения. Для этого рассмотрим подробнее структуру заголовка:
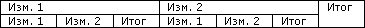
При этом можно легко найти способ определения номеров соответствующей ячейки и итогов, в которые она попадает. Здесь можно предложить несколько подходов. Один из них - это использование дерева для поиска соответствующих ячеек. Это дерево может быть построено при проходе по выборке. Кроме того, можно легко определить аналитическую рекуррентную формулу для вычисления требуемой координаты.
Подготовка данных
Данные, хранящиеся в таблице необходимо преобразовать для их использования. Так, в целях повышения производительности при построении гиперкуба, желательно находить уникальные элементы, хранящиеся в столбцах, являющихся измерениями куба. Кроме того, можно производить предварительное агрегирование фактов для записей, имеющих одинаковые значения размерностей. Как уже было сказано выше, для нас важны уникальные значения, имеющиеся в полях измерений. Тогда для их хранения можно предложить следующую структуру:
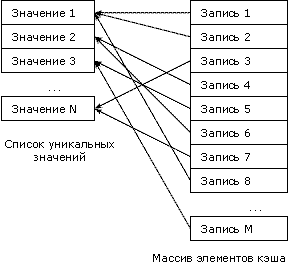
При использовании такой структуры мы значительно снижаем потребность в памяти. Что довольно актуально, т.к. для увеличения скорости работы желательно хранить данные в оперативной памяти. Кроме того, хранить можно только массив элементов, а их значения выгружать на диск, так как они будут нам требоваться только при выводе кросс-таблицы.
Библиотека компонентов CubeBase
Описанные выше идеи были положены в основу при создании библиотеки компонентов CubeBase.
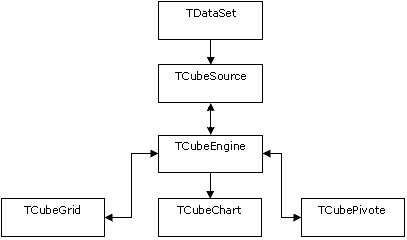
TСubeSource осуществляет кэширование и преобразование данных во внутренний формат, а также предварительное агрегирование данных. Компонент TСubeEngine осуществляет вычисление гиперкуба и операции с ним. Фактически, он является OLAP-машиной, осуществляющей преобразование плоской таблицы в многомерный набор данных. Компонент TCubeGrid выполняет вывод на экран кросс-таблицы и управление отображением гиперкуба. TСubeChart позволяет увидеть гиперкуб в виде графиков, а компонент TСubePivote управляет работой ядра куба.
Сравнение производительности
Данный набор компонент показал намного более высокое быстродействие, чем Decision Cube. Так на наборе из 45 тыс. записей компоненты Decision Cube потребовали 8 мин. на построение сводной таблицы. CubeBase осуществил загрузку данных за 7сек. и построение сводной таблицы за 4 сек. При тестировании на 700 тыс. записей Decision Cube мы не дождались отклика в течение 30 минут, после чего сняли задачу. CubeBase осуществил загрузку данных за 45 сек. и построение куба за 15 сек.
На объемах данных в тысячи записей CubeBase отрабатывал в десятки раз быстрее Decision Cube. На таблицах в сотни тысяч записей √ в сотни раз быстрее. А высокая производительность √ один из самых важных показателей OLAP систем.
Ядро OLAP системы. Часть 2 -- внутри гиперкуба
В предыдущей статье была рассмотрена архитектура и взаимодействие компонентов, которые могут быть использованы для построения OLAP машины. Теперь рассмотрим подробнее внутреннее устройство компонентов.
Загрузка данных в гиперкуб
Первым этапом работы системы будет загрузка данных и преобразование их во внутренний формат. Закономерным будет вопрос - а зачем это надо, ведь можно просто использовать данные из плоской таблицы, просматривая ее при построении среза куба. Для того чтобы ответить на этот вопрос, рассмотрим структуру таблицы с точки зрения OLAP машины.
Для OLAP системы колонки таблицы могут быть либо фактами, либо измерениями. При этом логика работы с этими колонками будет разная. В гиперкубе измерения фактически являются осями, а значения измерений √ координатами на этих осях. При этом куб будет заполнен сильно неравномерно √ будут сочетания координат, которым не будут соответствовать никакие записи и будут сочетания, которым соответствует несколько записей в исходной таблице, причем первая ситуация встречается чаще, то есть куб будет похож на вселенную - пустое пространство, в отдельных местах которого встречаются скопления точек (фактов). Таким образом, если мы при начальной загрузке данных произведем преагрегирование данных, то есть объединим записи, которые имеют одинаковые значения измерений, рассчитав при этом предварительные агрегированные значения фактов, то в дальнейшем нам придется работать с меньшим количеством записей, что повысит скорость работы и уменьшит требования к объему оперативной памяти.
Для построения срезов гиперкуба необходимы следующие возможности √ определение координат (фактически значения измерений) для записей таблицы, а также определение записей, имеющих конкретные координаты (значения измерений). Рассмотрим каким образом можно реализовать эти возможности.
Для хранения гиперкуба проще всего использовать базу данных своего внутреннего формата. Схематически преобразования можно представить следующим образом:
То есть вместо одной таблицы мы получили нормализованную базу данных. Вообще-то нормализация снижает скорость работы системы, - могут сказать специалисты по базам данных, и в этом они будут безусловно правы, в случае когда нам надо получить значения для элементов словарей (в нашем случае значения измерений). Но все дело в том, что нам эти значения на этапе построения среза вообще не нужны. Как уже было сказано выше, нас интересуют только координаты в нашем гиперкубе, поэтому определим координаты для значений измерений. Самым простым будет перенумеровать значения элементов. Для того, чтобы в пределах одного измерения нумерация была однозначной, предварительно отсортируем списки значений измерений (словари, выражаясь терминами БД) в алфавитном порядке. Кроме того, перенумеруем и факты, причем факты преагрегированные. Получим следующую схему:

Теперь осталось только связать элементы разных таблиц между собой. В теории реляционных баз данных это осуществляется при помощи специальных промежуточных таблиц. Нам достаточно каждой записи в таблицах измерений поставить в соответствие список, элементами которого будут номера фактов, при формировании которых использовались эти измерения (то есть определить все факты, имеющие одинаковое значение координаты, описываемой этим измерением). Для фактов соответственно каждой записи поставим в соответствие значения координат, по которым она расположена в гиперкубе. В дальнейшем везде под координатами записи в гиперкубе будут пониматься номера соответствующих записей в таблицах значений измерений. Тогда для нашего гипотетического примера получим следующий набор, определяющий внутреннее представление гиперкуба:
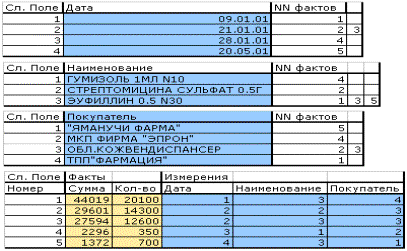
Такое будет у нас внутреннее представление гиперкуба. Так как мы делаем его не для реляционной базы данных, то в качестве полей связи значений измерений используются просто поля переменной длины (в РБД такое сделать мы бы не смогли, так как там количество колонок таблицы определено заранее).
Реализация гиперкуба
Можно было бы попытаться использовать для реализации гиперкуба набор временных таблиц, но этот метод обеспечит слишком низкое быстродействие (пример √ набор компонент Decision Cube), поэтому будем использовать свои структуры хранения данных.
Для реализации гиперкуба нам необходимо использовать структуры данных, которые обеспечат максимальное быстродействие и минимальные расходы оперативной памяти. Очевидно, что основными у нас будут структуры для хранения словарей и таблицы фактов. Рассмотрим задачи, которые должен выполнять словарь с максимальной скоростью:
проверка наличия элемента в словаре;
добавление элемента в словарь;
поиск номеров записей, имеющих конкретное значение координаты;
поиск координаты по значению измерения;
поиск значения измерения по его координате.
Для реализации этих требований можно использовать различные типы и структуры данных. Например, можно использовать массивы структур. В реальном случае к этим массивам необходимы дополнительные механизмы индексации, которые позволят повысить скорость загрузки данных и получения информации.
Для оптимизации работы гиперкуба необходимо определить то, какие задачи необходимо решать в первоочередном порядке, и по каким критериям нам надо добиваться повышения качества работы. Главным для нас является повышение скорости работы программы, при этом желательно, чтобы требовался не очень большой объем оперативной памяти. Повышение быстродействия возможно за счет введения дополнительных механизмов доступа к данным, например, введение индексирования. К сожалению, это повышает накладные расходы оперативной памяти. Поэтому определим, какие операции нам необходимо выполнять с наибольшей скоростью. Для этого рассмотрим отдельные компоненты, реализующие гиперкуб. Эти компоненты имеют два основных типа- измерение и таблица фактов. Для измерения типовой задачей будет:
- добавление нового значения;
- определение координаты по значению измерения;
- определение значения по координате.
При добавлении нового значения элемента нам необходимо проверить, есть ли у нас уже такое значение, и если есть, то не добавлять новое, а использовать имеющуюся координату, в противном случае необходимо добавить новый элемент и определить его координату. Для этого необходим способ быстрого поиска наличия нужного элемента (кроме того, такая задача возникает и при определении координаты по значению элемента). Для этого оптимальным будет использование хеширование. При этом оптимальной структурой будет использование хеш-деревьев, в которых будем хранить ссылки на элементы. При этом элементами будут строки словаря измерения. Тогда структуру значения измерения можно представить следующим образом:
PFactLink=^TFactLink;
TFactLink=record
FactNo:integer;//индекс факта в таблице
Next:PFactLink;// ссылка на следующий элемент
End;
TDimensionRecord=record
Value:string;//значение измерения
Index:integer;//значение координаты
FactLink:PFactLink;//указатель на начало списка элементов таблицы фактов
End;
И в хеш-дереве будем хранить ссылки на уникальные элементы. Кроме того, нам необходимо решить задачу обратного преобразования √ по координате определить значение измерения. Для обеспечения максимальной производительности надо использовать прямую адресацию. Поэтому можно использовать еще один массив, индекс в котором является координатой измерения, а значение - ссылка на соответствующую запись в словаре. Однако можно поступить проще (и сэкономить при этом на памяти), если соответствующим образом упорядочить массив элементов так, чтобы индекс элемента и был его координатой.
Организация же массива, реализующего список фактов, не представляет особых проблем ввиду его простой структуры. Единственное замечание будет такое, что желательно рассчитывать все способы агрегации, которые могут понадобиться, и которые можно рассчитывать инкрементно (например, сумма).
Ядро OLAP системы. Часть 3 -- построение срезов куба
Итак, в предыдущей статье был описан способ хранения данных в виде гиперкуба. Он позволяет сформировать набор точек в многомерном пространстве на основе информации, находящейся в хранилище данных. Для того, чтобы человек мог иметь возможность работы с этими данными, их необходимо представить в виде, удобном для обработки. При этом в качестве основных видов представления данных используются сводная таблица и графики. Причем оба этих способа фактически представляют собой проекции гиперкуба. Для того, чтобы обеспечить максимальную эффективность при построения представлений, будем отталкиваться от того, что представляют собой эти проекции. Начнем рассмотрение со сводной таблицы, как с наиболее важной для анализа данных. Структура сводной таблицы достаточно подробно была рассмотрена в первой статье, посвященной разработке OLAP системы.
Необходимо найти способы реализации такой структуры. Можно выделить три части, из которых состоит сводная таблица: это заголовки строк, заголовки столбцов и собственно таблица агрегированных значений фактов. Самым простым способом представления таблицы фактов будет использование двумерного массива, размерность которого можно определить, построив заголовки. К сожалению, самый простой способ будет самым неэффективным, потому что таблица будет сильно разреженной, и память будет расходоваться крайне неэффективно, в результате чего можно будет строить только очень малые кубы, так как иначе памяти может не хватить. Таким образом, необходимо подобрать для хранения информации такую структуру данных, которая обеспечит максимальную скорость поиска/добавления нового элемента и в то же время минимальный расход оперативной памяти. Этой структурой будут являться так называемые разреженные матрицы, про которые более подробно можно прочесть у Кнута. Возможны различные способы организации матрицы. Для того, чтобы выбрать подходящий нам вариант, рассмотрим изначально структуру заголовков таблицы.
Заголовки имеют четкую иерархическую структуру, поэтому естественно будет предположить для их хранения использовать дерево. При этом схематически структуру узла дерева можно изобразить следующим образом:
| Родительский узел | Значение измерения | N (Количество дочерних узлов) | Столбец (строка) со значением |
| Дочерний узел 1 | Дочерний узел 2 | ┘ | Дочерний узел N |
При этом в качестве значения измерения логично хранить ссылку на соответствующий элемент таблицы измерений многомерного куба (см. предыдущую статью). Это позволит сократить затраты памяти для хранения среза и ускорить работу. В качестве родительских и дочерних узлов также используются ссылки. Тогда описанную структуру можно реализовать следующим пседокодом:
PHeaderTreeNode=^THeaderTreeNode;
THeaderTreeNode=record
Parent:PHeaderTreeNode;//родительский узел
Value:PDimensionRecord;//значение измерения
ChildCount:integer;//кол-во детей узла
Childs:array of PHeaderTreeNode;//массив детей узла┘
End;
В этом коде пока не указан один элемент - столбец (строка) со значением. О том, чем является это поле, мы поговорим попозже. А теперь перейдем к добавлению элементов в дерево заголовков. Каждый уровень дерева будет соответствовать одному измерению в том порядке, в котором они используются для построения среза. При этом самый верхний узел дерева будет соответствовать полному итогу в сводной таблице.
Для добавления элемента в дерево необходимо иметь информацию о его местоположении в гиперкубе. В качестве такой информации надо использовать его координату, которая хранится в словаре значений измерения (см. предыдущую статью). Рассмотрим схему добавления элемента в дерево заголовков сводной таблицы. При этом в качестве исходной информации используем значения координат измерений. Порядок, в котором эти измерения перечислены, определяется требуемым способом агрегирования и совпадает с уровнями иерархии дерева заголовков. В результате работы необходимо получить список столбцов или строк сводной таблицы, в которые необходимо осуществить добавление элемента.
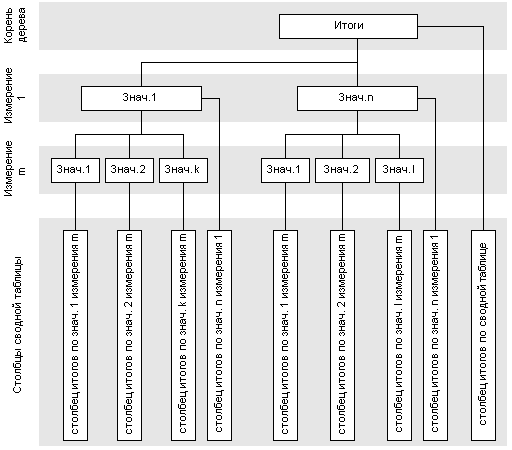
В качестве исходных данных для определения этой структуры используем координаты измерений. Кроме того, для определенности, будем считать, что мы определяем интересующий нас столбец в матрице (как будем определять строку рассмотрим чуть позже, так как там удобнее применять другие структуры данных, причина такого выбора также см. ниже). В качестве координат возьмем целые числа √ номера значений измерений, которые можно определить так, как описано в предыдущей статье. Тогда это можно реализовать процедурой, имеющей следующий вид:
Procedure GetMatrixCol(InpCoord: array of integer; var OutCols: array of PMatrixCol);
//InpCoord √ набор значений координат измерений
// OutCols √ набор столбцов, в формировании значений которых используется данный//факт
Var
xNode:PheaderTreeNode;//текущий узел дерева
I:integer;//Номер текущего уровня дерева
Begin
xNode:= RootNode; // присваиваем значение текущего узла в корневой узел
for I:=0 to DimensionsCols.Count √1 do
begin
OutCols[I]:=xNode.MatrixCol;//это ссылка на столбец матрицы
// проверяем, есть ли у нас соответствующий дочерний узел
if xNode.Childs[InpCoord[I]]= nil then
begin
inc(xNode).ChildCount;//увеличиваем счетчик потомков узла // теперь создаем новый узел √ потомок
xNode.Childs[InpCoord[I]]:=new(TColHeaderTreeNode);
SetLength(xNode.Childs[InpCoord[I]].Childs,DimensionsCols[I].Count);
xNode.Childs[InpCoord[I]].ChildCount:=0;
xNode.Childs[InpCoord[I]].Parent:=xNode;
xNode.Childs[InpCoord [I]].Value:=DimensionCols[I].Value[InpCoord [I]];
end;
// переходим к следующему узлу
xNode:=xNode.Childs[InpCoord[I]];
end;
End;
Итак, после выполнения этой процедуры получим массив ссылок на столбцы разреженной матрицы. Теперь необходимо выполнить все необходимые действия со строками. Для этого внутри каждого столбца необходимо найти нужный элемент и добавить туда соответствующее значение. Из того, что раньше не рассматривалось в процедуре встречается DimensionCols √ это коллекция измерений, которые отложены в столбцах сводной таблицы. Для каждого из измерений в коллекции необходимо знать количество уникальных значений и собственно набор этих значений.
Теперь рассмотрим, в каком виде необходимо представить значения внутри столбцов - то есть как определить требуемую строку. Для этого можно использовать несколько подходов. Самым простым было бы представить каждый столбец в виде вектора, но так как он будет сильно разреженным, то память будет расходоваться крайне неэффективно. Чтобы избежать этого, применим структуры данных, которые обеспечат большую эффективность представления разреженных одномерных массивов (векторов). Самой простой из них будет обычный список, одно- или двусвязный, однако он неэкономичен с точки зрения доступа к элементам. Поэтому будем использовать дерево, которое обеспечит более быстрый доступ к элементам. Например, можно использовать точно такое же дерево, как и для столбцов, но тогда пришлось бы для каждого столбца заводить свое собственное дерево, что приведет к значительным накладным расходам памяти и времени обработки. Поступим чуть хитрее √ заведем одно дерево для хранения всех используемых в строках комбинаций измерений, которое будет идентично вышеописанному, но его элементами будут не указатели на строки (которых нет как таковых), а их индексы, причем сами значения индексов нас не интересуют и используются только как уникальные ключи. Затем эти ключи будем использовать для поиска нужного элемента внутри столбца. Сами же столбцы проще всего представить в виде обычного двоичного дерева. Графически полученную структуру можно представить следующим образом:
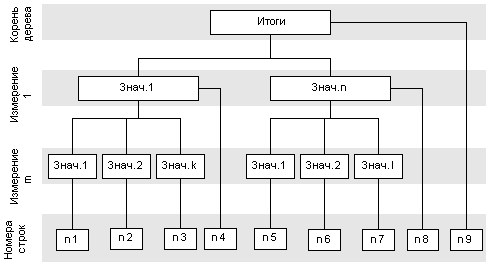
Для определения соответствующих номеров строк можно использовать такую же процедуру, что и описанная выше процедура определения столбцов сводной таблицы. При этом номера строк являются уникальными в пределах одной сводной таблицы и идентифицируют элементы в векторах, являющихся столбцами сводной таблицы. Наиболее простым вариантом генерации этих номеров будет ведение счетчика и инкремент его на единицу при добавлении нового элемента в дерево заголовков строк. Сами эти вектора столбцов проще всего хранить в виде двоичных деревьев, где в качестве ключа используется значение номера строки. Кроме того, возможно также и использование хеш-таблиц. Так как процедуры работы с этими деревьями детально рассмотрены в других источниках, то останавливаться на этом не будем и рассмотрим общую схему добавления элемента в столбец.
В обобщенном виде последовательность действий для добавления элемента в матрицу можно описать следующим образом:
- Определить номера строк, в которые добавляются элементы
- Определить набор столбцов, в которые добавляются элементы
Для всех столбцов найти элементы с нужными номерами строк и добавить к ним текущий элемент (добавление включает в себя подсоединение нужного количества значений фактов и вычисление агрегированных значений, которые можно определить инкрементально).
После выполнения этого алгоритма получим матрицу, представляющую собой сводную таблицу, которую было необходимо построить.
Теперь пара слов про фильтрацию при построении среза. Проще всего ее осуществить как раз на этапе построения матрицы, так как на этом этапе имеется доступ ко всем требуемым полям, и, кроме того, осуществляется агрегация значений. При этом, во время получения записи из кэша, проверяется ее соответствие условиям фильтрации, и в случае его несоблюдения запись отбрасывается.
Так как описанная выше структура полностью описывает сводную таблицу, то задача ее визуализации будет тривиальна. При этом можно использовать стандартные компоненты таблицы, которые имеются практически во всех средствах программирования под Windows.
Заключение
Опыт использования технологии OLAP (концерн "Пульсар")
Как эффективно использовать накопившуюся информацию в базах данных? Как заставить числа "заговорить"? Базы данных - это кладезь информации, но нужен гибкий инструмент для выборки и агрегирования данных. Нам хотелось бы поделиться опытом использования одной из аналитических технологий, а именно OLAP.
Справка: Концерн "Пульсар" объединяет 6 совместных узбекско-чешских производственных предприятий и 9 дилерских фирм и в настоящее время является одной из быстроразвивающихся и динамичных компаний на рынке Узбекистана. Компания каждый год осваивает 1-2 новых производства.
Аналитический отдел концерна "Пульсар" занимается исследованием и анализом деятельности предприятий, входящих в состав концерна, а также разработкой перспективных направлений бизнеса.
Управлять современным бизнесом без качественных и своевременных данных невозможно, и поэтому при создании отдела была поставлена задача наладить информационные потоки с предприятий в головной офис. Одним из условий являлось использование информации исключительно в электронной форме. С этой целью было решено внедрить в концерне новую систему управленческой отчетности.
Управленческий учет имеет свою специфику, и стандартные бухгалтерские отчеты не подходят для этих целей. Была создана собственная система управленческой отчетности (СУО) со своими стандартными сводками и отчетами. СУО является внутренней системой учета, отчеты используются только внутри компании, и это позволяет более объективно оценивать существующее положение вещей и принимать оперативные решения в управлении компанией.
Вновь созданная система управленческой отчетности охватывает всю деятельность предприятия и следит за такими ключевыми параметрами, как дебиторская задолженность, поддержка оптимального уровня складских запасов, производство продукции и т.д. Изучив действующую информационную систему, мы пришли к выводу, что получить необходимые сводки и отчеты, используя существующие программы, не представляется возможным, так как в основном эти программы автоматизировали бухгалтерский учет и торговую деятельность.
До объединения предприятий в концерн не существовало единой политики в области информационных технологий. Одни предприятия были автоматизированы комплексно, другие частично, на предприятиях использовались программы разных разработчиков, существовала проблема "островковой автоматизации", то есть не могло быть и речи о единых стандартах в структуре файлов баз данных. И, на первый взгляд, стояла непростая задача извлечения нужной информации из базы данных? Модернизировать программное обеспечение для каждого из предприятий было нецелесообразно и довольно накладно, приводить все данные к единому формату заняло бы достаточно много времени и не было уверенности в том, что это верное решение.
Был проведен анализ рынка аналитического программного обеспечения и, в результате мы остановили свой выбор на программе Cube российского разработчика ПО Basegroup.
Basegroup любезно предоставила нам версию try and buy. Несколько дней работы с пакетом показали, что именно такое ПО подходит для решения наших задач. Первое, что хочется выделить, так это возможность генерации практически любых агрегированных данных за считанные минуты. Полученный результат легко экспортируется MS Excel. Использование программы избавило нас от дополнительного документооборота, если раньше формы сводок составлялись в аналитическом отделе и после согласования с руководством рассылались по всем предприятиям, заполнив которые, нужно было отослать обратно, в настоящее время, пользуясь Cube, мы отказались от подобной практики.
Аналитический отдел имеет доступ к базам данных предприятий, и в нужное время выбирает необходимые данные прямо из них. Несомненным достоинством программы является и то, что ей может пользоваться рядовой пользователь компьютера, не обладающий специальными знаниями в области баз данных. Программа обладает понятным и дружественным интерфейсом и легка в освоении.
Приведем два частных случая использования программы.
Производственные предприятия концерна составляют планы на будущий год, для этого составляются бюджеты продаж, бюджеты расходов по реализации, бюджеты производства, бюджет финансовой деятельности и т.д. Рассмотрим бюджет продаж. Для составления этого бюджета мы использовали статистические данные за предшествующие годы. Для того, чтобы получить предполагаемые продажи за планируемый период, мы должны были учесть сезонность продукта, уровень продаж прошлых периодов, влияние отпускных цен на продажи и другие параметры. Очевидно, что получить эту информацию, используя бухгалтерскую отчетность не так уж просто. И здесь нам на помощь пришла программа Cube, мы не только существенно сэкономили время, отведенное на подготовку плановых данных, но подготовили более качественные данные. Сверка плановых показателей с фактическими выявила небольшие отклонения, что в очередной раз подтвердило оправданность использования Cube.
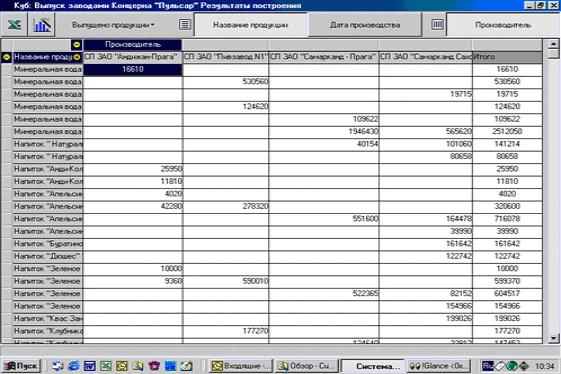
Вся продукция, производимая предприятиями, реализуется через дилерскую сеть.
Тщательный анализ клиентской базы помог выявить крупных покупателей, и соответственно дилерам были порекомендованы особые условия поведения по отношению к таким клиентам. Результаты анализа также показали, когда и какую продукцию клиенты заказывают.
Теперь мы смело можем утверждать, что мы знаем, чего хотят наши клиенты, и мы способны вовремя поставить нужную им продукцию.
В настоящее время организовано 4 рабочих места, использующие ПО Cube.
Приведем основные достоинства программы:
- Генерация практически любого отчета.
- Экспорт данных в MS Excel.
Нет рутинной работы по составлению отчетов.
Нет необходимости в привлечении квалифицированных программистов.
Нет необходимости изменять существующую информационную систему только для того, чтобы получить новые виды отчетов.
Цена программного продукта и профессионализм службы поддержки.
Теперь мы уверены в том, что все данные обрабатываются и отражаются в отчетах.
Я. Янски - генеральный директор Концерна "Пульсар", кандидат технических наук (jajan@pulsar.uz)

