 2015-05-14
2015-05-14 491
491Построение и оценка модели множественной регрессии средствами Microsoft Excel.
Цель работы: Изучение возможностей электронной таблицы Excel построения модели множественной регрессии.
ОСНОВНЫЕ ПОЛОЖЕНИЯ.
Набор отобранных для корреляционного анализа факторов может быть различным в зависимости от цели анализа, предполагаемого периода прогнозирования и характера экономического показателя. С учетом этого для построения экономико-математической модели, отражающей форму зависимости отдельных переменных, на торговом предприятии могут быть рассмотрены нижеприведенные факторы при анализе и прогнозировании спроса:
денежные доходы или покупательские фонды населения;
индекс цен на потребительские товары;
численность населения;
объем товарного предложения;
уровень соотношения индексов цен и тарифов;
степень удовлетворения покупательского спроса;
уровень достижения рациональных или рекомендуемых норм потребления.
Наиболее приемлемым способом отбора факторных признаков для построения модели является шаговая регрессия.
В экономической жизни каждый отдельно взятый фактор, как правило, не определяет изучаемое явление во всей полноте. Только комплекс факторов вих взаимосвязи может дать более или менее полное представление о характере поведения изучаемого явления.
На состояние любого экономического объекта постоянно воздействует большое количество других, менее важных или трудно идентифицируемых факторов. Это приводит к отклонению значений объясняемой (зависимой) переменной от конкретной формулы ее связи с объясняющими переменными.
Процесс создания многофакторной модели на практике может оказаться достаточно длительным и сложным. Редко первое оцененное уравнение зависимости экономических переменных является удовлетворительным во всех отношениях. Обычно исследователю приходится постепенно подбирать состав объясняющих переменных и формулу связи, анализируя на каждом этапе качество оцененной зависимости.
Формально решить задачу построения модели множественной регрессии можно лишь в том случае, когда количество наблюдений п превышает число независимых факторов k и, по крайней мере, выполняется неравенство п>=k+ 1. Если разность n-k - 1 (число степеней свободы) мало, то статистическая надежность оцениваемой формулы не будет высокой. Поэтому обычно при оценке множественной регрессии требуется, чтобы число наблюдений не менее, чем в 3 раза превосходило количество объясняющих переменных х.
Одним из основных препятствий на пути эффективного построения модели множественной регрессии является наличие коллинеарности, т.е. линейной или близкой к ней связи между факторными признаками. При построении многофакторной модели наличие коллинеарности может привести к негативным последствиям: искажение значений параметров модели (они имеют тенденцию к завышению), невозможность экономической интерпретации параметров модели, ошибка в определении наиболее существенных факторных признаков; низкий уровень прогнозных качеств модели.
Чтобы избавиться от коллинеарности, в модель включают лишь один из линейно связанных между собой факторов. Вопрос о том, какой из них следует отбросить, решается на основании качественного и логического анализов изучаемого явления.
Наиболее приемлемым способом отбора факторных признаков для построения модели является шаговая регрессия. Сущность метода шаговой регрессии заключается в последовательном включении факторов в уравнение: сначала в расчет принимается один фактор, с которым у исследуемого показателя наиболее тесная линейная связь, затем второй, третий и т.д. И на каждом шаге рассчитываются уравнение связи и набор статистических характеристик, которые позволяют судить о качестве полученного уравнения. Если введение каждого последующего фактора не ухудшает общего качества модели, то данный фактор признается существенным и его включение в уравнение регрессии необходимо. Если же при введении в уравнение факторного признака статистические характеристики его качества ухудшаются, то данный признак не включают в модель связи.
Расчет формулы связи переменных еще не означает, что создана модель регрессии. До тех пор, пока не дана оценка ее качества, полученное уравнение остается лишь гипотезой.
Для статистической оценки общего качества уравнения линейной регрессии обычно используют коэффициент детерминации R2. Как правило, с добавлением еще одной переменной R2 увеличивается, но если объясняющие переменные Xi и Х2 сильно коррелируют между собой, то они объясняют одну и ту же часть разброса переменной у, и в этом случае ухудшаются показатели оценки статистической значимости параметров уравнения.
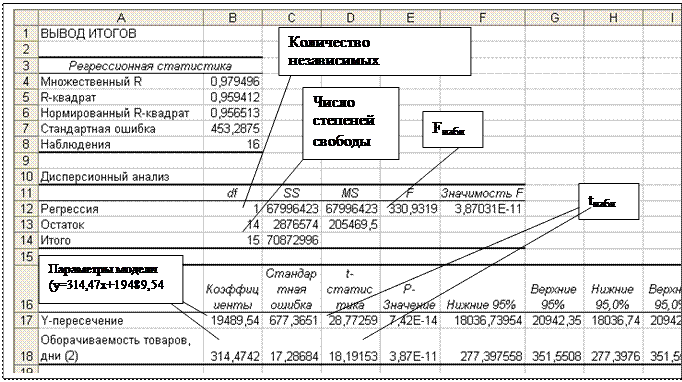
Чтобы убедиться в статистической надежности модели (или статистической значимости коэффициента детерминации R2) используютF-критерий (Фишера), расчетное значение которого сравнивают с табличным: при заданном уровне значимости модель считается надежной, если Fнабл>Fкрит.
При проверке адекватности уравнения множественной регрессии исследуемому процессу возможны следующие варианты:
1) построенная модель на основе ее проверки по F-критерию в целом адекватна и все параметры уравнения регрессии значимы. Такая модель может быть использована для прогнозирования исследуемого показателя;
2) модель по F-критерию адекватна, но часть параметров регрессии не значима. В этом случае модель может быть пригодна для принятия отдельных решении, но не подходит для расчета прогнозов;
3)
 |
модель по F-критерию адекватна, но все параметры уравнения не значимы. Такая модель полностью считается неадекватной. На ее основе нельзя принимать решения и составлять прогнозы.
Электронная таблица Microsoft Excel предлагает вычислять параметры линейной регрессии с помощью Пакета анализа – Регрессии (Сервис-Анализ данных - Регрессия). В результате на листе Excel будет отображены параметры линейной модели, а также статистическая информация, которая позволяет проверить надежность модели (по F-критерию) и ее параметров (по t-критерию).
Примечание: можно упростить процесс построения модели множественной регрессии, если предварительно рассчитать коэффициенты парной корреляции для всех факторов (Сервис→Анализ данных→ Корреляция).
Таблица 1
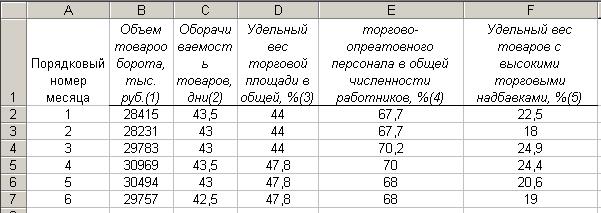
Таблица 2
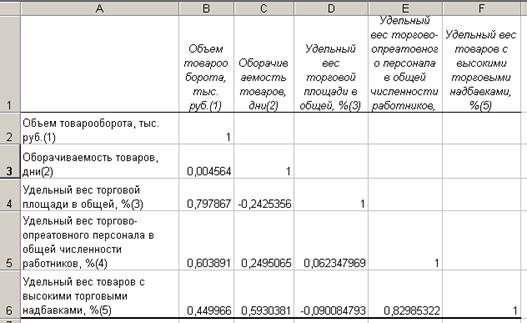
Проведение всех обозначенных действий с данными табл. 1 позволяет получить матрицу значений парных коэффициентов корреляции, рассчитанных для всех возможных пар переменных без учета влияния других факторов (табл. 2). Поскольку коэффициент корреляции двух наборов данных не зависит от последовательности их обработки, то выходная область занимает только половину предназначенного для нее места. Ячейки выходного диапазона, имеющие совпадающие координаты строк и столбцов, содержат значение 1, так как каждая строка или столбец во входном диапазоне полностью коррелирует с самим собой.
На основе приведенной матрицы можно содержательней оценить связь значений объема товарооборота с каждым из отобранных факторов и выбрать наиболее значимые из них для включения в модель. Так, полученные коэффициент корреляции, характеризующие тесноту связи объема товарооборота (1) с отобранными факторами (см. столбец В табл. 2), составляют соответственно: - 0,005 для фактора «оборачиваемость товаров 2»; 0,797 для фактора «удельный вес торговой площади в общей 3»; 0,604 для фактора «удельный вес товаров с высокими торговыми надбавками 4»; 0,449 для фактора «удельный вес торгово-оперативного персонала в общей численности работников 5». Согласно приведенной выше шкале Чеддока, для данного торгового предприятия: Высокая связь показателей: (1) с (3), (4) с (5); Заметная связь: (1) с (4), (3) с (4), (2) с (6).
Учитывая эти оценки, можно попытаться построить линейные однофакторные модели. характеризующие связь объема товарооборота с каждым из названных факторов.
2. Практическая часть
Задание. В приведенной ниже таблице приведены данные за последний год работы некоторого торгового предприятия.
Таблица 3
| Номер месяца | Спрос, млн. руб. | степень удовлетворения покупательского спроса, %. | денежные доходы или покупательские фонды населения, млн.руб. | численность населения, млн. чел. | объем товарного предложения |
| Действие | -N | +N | -N | +N | |
| 227,87 | |||||
| 226,3861 | 10,1 | ||||
| 238,9023 | 10,2 | ||||
| 240,4689 | 10,4 | ||||
| 244,6361 | 10,3 | ||||
| 238,6926 | 1,5 | ||||
| 249,2154 | 10,5 | ||||
| 251,3377 | 10,6 | ||||
| 251,6119 | 10,3 | ||||
| 250,1547 | 10,5 | ||||
| 259,7329 | 10,4 | ||||
| 265,3214 | 10,6 |
где N – номер варианта, который необходимо добавить или отнять в зависимости от указанного во второй строке действия к данным значениям.
Найти модель зависимости спроса от существенных факторов. Для каждой полученной модели необходимо:
- проверить ее прогнозные качества;
- проверить надежность модели;
- проверить адекватность параметров модели.
Последовательность действий:
1. На листе Исходные данные получить данные для исследования следующим образом: к каждому значению Таблицы 3 добавить или вычесть номер варианта, указанного преподавателем.
2. На каждом новом листе получить параметры регрессии (анализ модели и ее параметров записать в отчет).
3. Содержание отчета:
1. Название работы.
2. Цель работы.
3. Проверить надежность параметров и моделей, созданных в п.1








