2015-05-18
2015-05-18 413
413| Ответы | Результаты классификации | Распределение ответов в % |
| Класс «А» | ||
| Класс «В» | ||
| Ответ неопределенный | ||
| Всего |
Соответствие ошибок классификации тем, которые были назначены, указывает на то, что в нашем случае статистическая зависимость между признаками мала. И действительно, вычисление интеркорреляций между признаками показало, что в подавляющем числе случаев они оказались статистически независимыми.
Имеются основания считать, что несколько худшие различения класса «В» (см. табл. 17) связаны с наличием большей зависимости между признаками в этом случае.
Таким образом, предлагаемый алгоритм можно рассматривать как реальную основу для решения конкретных задач определения профессиональной пригодности. При использовании простых вычислительных средств оказывается возможным определение наиболее прогностических методик, а после построения таблиц (подобных табл. 14), отнесение данного субъекта с заданной вероятностью ошибки к классу «А» или «В».
Пользоваться такой таблицей удобно – действие сводится к сложению трехзначных чисел. Необходимо подчеркнуть, что последовательный характер вынесения решения позволяет также последовательно получить и психологические характеристики личности, что в большинстве случаев делает излишним проведение полного набора психологических исследований. Кроме того, это также существенно экономит время проведения психологической экспертизы.
Предлагаемый алгоритм имеет определенные преимущества перед другими способами определения профессиональной пригодности не только своей вычислительной простотой и удобством, но и своей эффективностью. Дело в том, что известные математические способы, используемые для целей определения профессиональной пригодности, как правило, предполагают нормальное распределение признаков, что в действительности не имеет места. Эффективность же предлагаемого алгоритма не зависит от вида распределений, а в случае независимости признаков, по-видимому, является и оптимальным методом разделения на два класса.
Уязвимым местом многих статистических алгоритмов является их большая чувствительность к сдвигу центра распределения признаков. Такой сдвиг естественно возникает как результат различных условий проведения тестирующих исследований. Ведь совершенно ясно, что условия получения признаков в обучающих группах и в реальной ситуации могут быть весьма различны. Отношение же вероятностей мало чувствительно к однонаправленному сдвигу центра распределений, и поэтому эффективность неоднородной последовательной статистической процедуры существенно при этом изменяться не будет. Она в какой-то степени инвариантна по отношению к однонаправленному сдвигу центров:
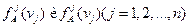
В то же время необходимость обучающих групп «А» и «В» является существенным и неустранимым недостатком настоящего алгоритма и может вызвать трудности при решении некоторых задач. Другой недостаток заключается в том, что алгоритм не учитывает зависимость признаков, но этот недостаток может быть устранен при введении сложных признаков – синдромов.
Есть основания считать, что предлагаемый алгоритм будет полезным при решении и ряда других задач, возникающих в прикладной и теоретической психологии Отметим возможность его применения для тонкой дифференциации психологических состояний на основании наблюдений большого числа признаков, каждый из которых содержит мало информации для различения