2015-05-12
2015-05-12 332
332Лекция 5. Деревья
}
Организация простейшего списка
#include <stdio.h>
struct TChain{
int val;
TChain* Next; };
int main ()
{
FILE *pFile;
int ik;
TChain *Head, *NewChain, *OldChain;
Head=new TChain; Head->Next=NULL; OldChain=Head;
pFile = fopen ("myfile.txt","rt");
while(!feof(pFile))
{ NewChain=new TChain;
fscanf(pFile,"%d \n",&ik); NewChain->val=ik;
NewChain->Next=NULL;
OldChain->Next=NewChain;
OldChain=NewChain;
}
fclose (pFile);
pFile = fopen ("myfile1.txt","w");
OldChain=Head;
do
{
NewChain=OldChain->Next;
ik=NewChain->val;
fprintf(pFile,"%d \n",ik);
delete OldChain;
OldChain=NewChain;
} while (NewChain->Next!=NULL);
fclose (pFile);
return 0;
}
ДЕРЕВЬЯ

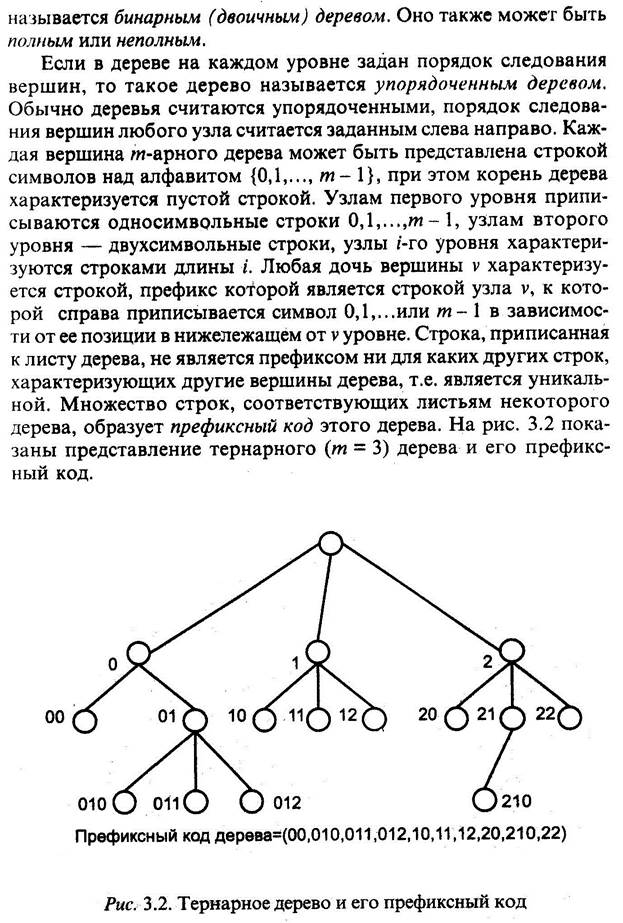
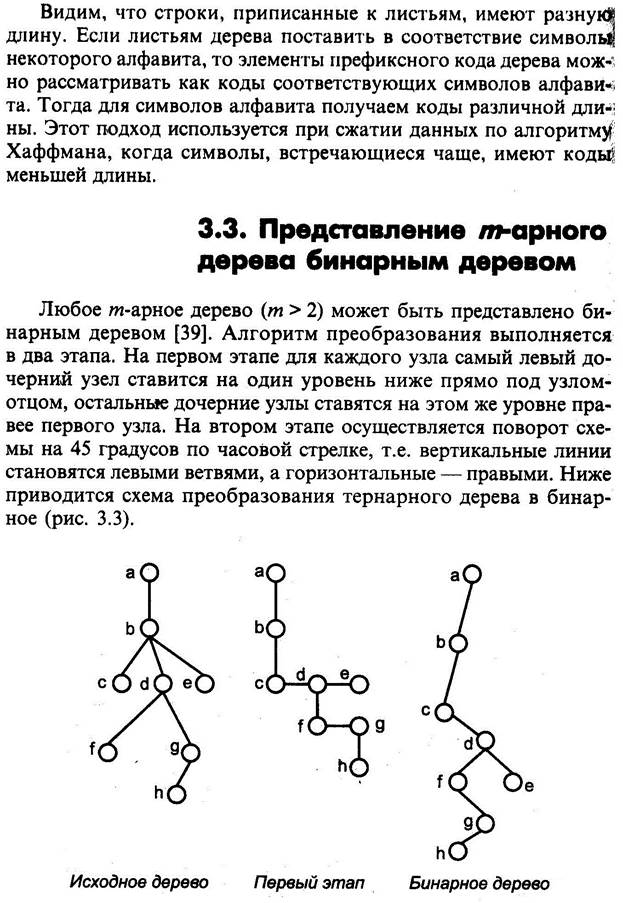


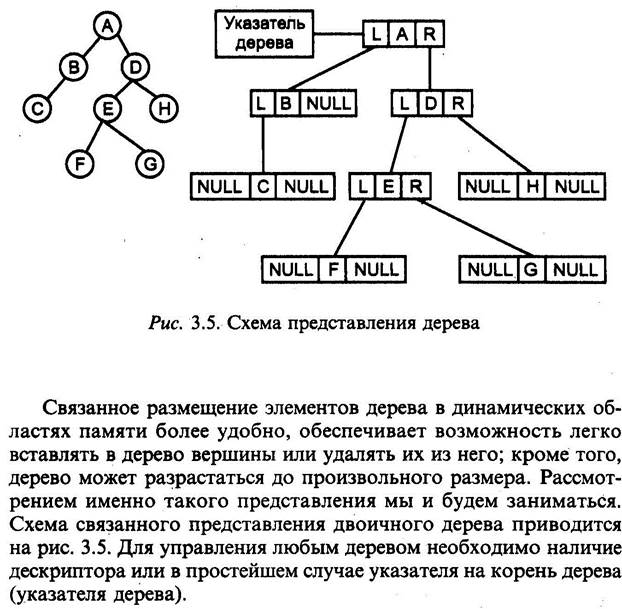







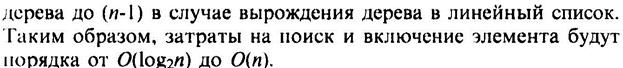



При построении рандомизированного дерева основное исходное положение заключается в том, что любой элемент может с одинаковой вероятностью быть корнем дерева. Причем это справедливо и для поддеревьев рандомизированного дерева. Поэтому при включении нового элемента в дерево, случайным образом выбирается включение элемента в качестве листа, или в качестве корня. Вероятность появления нового узла в корне дерева или поддерева определяется, как 1/(n+1), где n – число узлов в дереве или поддереве. (n — размер дерева до вставки)