 2015-08-13
2015-08-13 1186
1186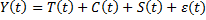
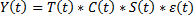
Мультипликативная – размах постепенно увеличивается. Аддитивная – размах колебаний постоянный.
Кривые роста. Группы (это у нас второй этап):
1. Полиномы
a. Линейные модели: yt=a+bt+et – это простейший полином 1ой степени. У этой прямой если взять производную – то скорость постоянная и равна “b”. Аналитическое обоснование для полинома первой степени – постоянство средних абсолютных приростов, т.е. для обоснования полинома первой степени нужно рассчитать абсолютные приросты. Такое поведение характерно для экстенсивного развития “y”.
b. Нелинейные модели:
i. yt=a+b1t+b2t2+et – полином 2ой степени. Скорость будет изменяться относительно времени. Вторая производная – ускорение. Характеризуется равноускоренным ростом либо снижение, все зависит от того больше или меньше b2, т.е. ветви параболы вверх или вниз. Изменение абсолютного прироста. Аналитическое обоснование – абсолютные приросты линейно изменяются со временем.
ii. Полином 3ей степени – может быть гипербола. Но такого экономического смысла нет. Поэтому кубическую функцию используют крайне редко, потому что у неё слабое экономическое и аналитическое обоснование.
2. Экспоненты (быстрее растут, чем полиномы)
a. Простая экспоненциальная кривая (показательная функция): yt=abt.
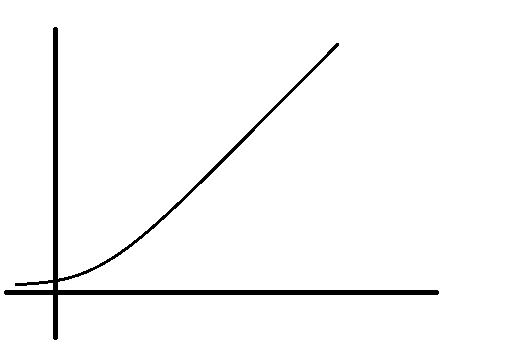
Аналитическое обоснование: постоянство темпов роста и прироста.
yt/yt-1=abt/abt-1=e
используется для интенсивного развития (низкий старт и ускоренное развитие).
b. Логарифмическая парабола.
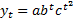

Аналитическое обоснование – линейное изменение во времени темпов прироста.
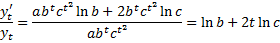
Темпы прироста линейно изменяются:
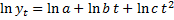
c. Модифицированные экспоненты: yt=k+bt
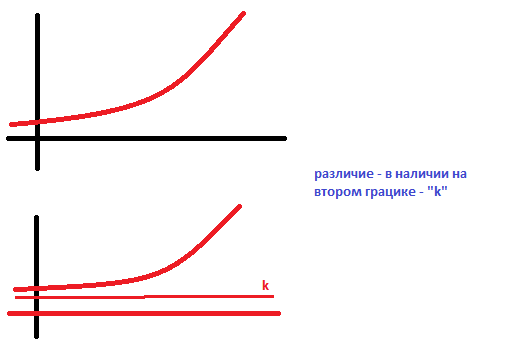
Аналитическое обоснование: логарифмы линейных приростов линейно изменяются
3. Логарифмические кривые – кривая Гомперца:
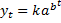
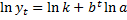
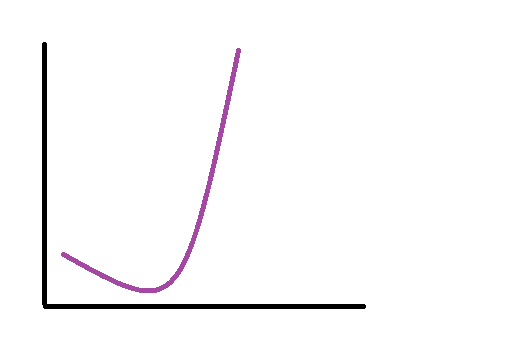
Аналитическое обоснование: логарифмы темпов прироста линейно изменяются.
Используется при прогнозировании в страховом бизнесе в демографических прогнозах (после увеличения дохода населения в определенный момент, рождаемость увеличится).
a. Этап параметризации – Тренд
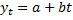
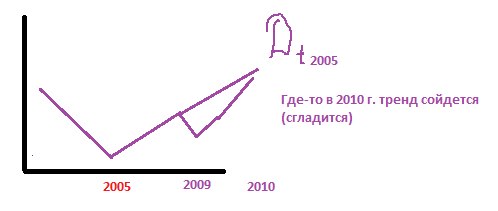
Какие могут быть ситуации с трендом: зависит от внешних проявлений, как например, в РБ в 2009 году резко упал экспорт
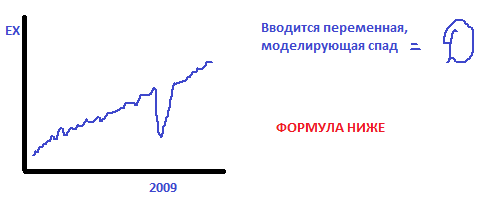

Фиктивная переменная моделирует изменение уровня тренда:

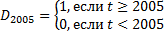

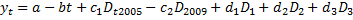
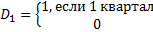
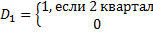
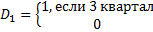
Сезонность присутствует, если все D (все три) значимы.
У d1, d2, d3 экономическая значимость – сравнение производится с 4ым кварталом.
b. Цикличность
Цикл можно выделить при исследовании 10 и более лет. С помощью рядов Фурье.
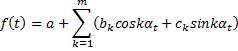
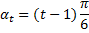
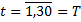
Добавляем цикличность в функцию:
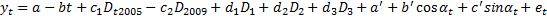
Проверяется значимость коэффициента, R2, свойства случайной ошибки (МНК), чтобы все оценки были состоятельными иэффективными
c. Этап верификации
Прогнозирование качества
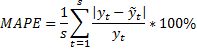
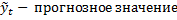
Если рассчитываем на год, то s=4, т.к. прогнозируем на 1 год поквартально.
Если MAPE:
· <10% - можно использовать модель дальше
· 10-20% - удовлетворительно
Больше чем на год по квартальным данным лучше не прогнозировать.
Ошибка аппроксимации – MAAE
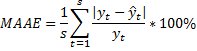
s=44, т.к. рассчитываем с 2000 г. по 2010 г. поквартально. Лучше, чтобы был меньше 10%
2. Исследование свойства стационарности
Строго-стационарный ряд (в узком смысле) – это ряд, у которого вероятностное распределение не зависит от t.
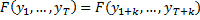
Характеристики случайных величин – мат.ожидание, дисперсия, ковариация.
Стационарный ряд (в широком смысле) – это временной ряд, или слабостационарный, если характеристики временного ряда не зависят от времени, т.е.
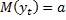
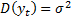
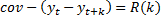
Вместо ковариации используют коэффициент корреляции:
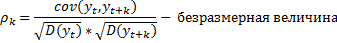
Автокорреляционная функция – это ACF= 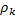 (соседняя).
(соседняя).
Частная автокорреляционная функция – это PACF= 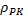 (без учета влияния промежуточных y)
(без учета влияния промежуточных y)
Для подтверждения необходимо применять тесты, про которые будет рассказано далее.
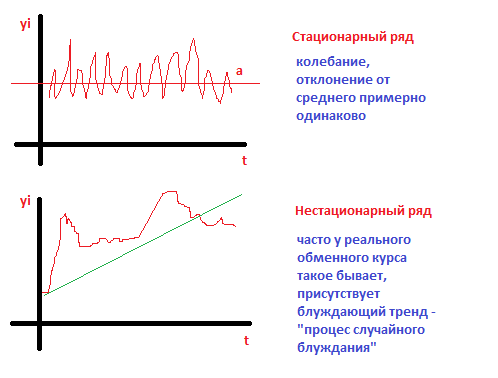
Если смотреть в Gretl, то графи стационарного ряда не будут выходить за пунктирные линии, т.е. аналогично линии: колебания примерно равны и присутствует убывание по экспоненте. У нестационарного – выходит за доверительную границу, убывание по экспоненте. Частная автокорреляционная функция – один выступающий лаг.
Инструмент проверки не стационарности ряда – процесс единичного корня.
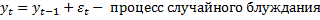
M(yt) = a
D(yt) = tb2
Процесс простейший первого порядка: AR(1)
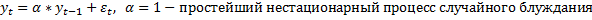
Тестирование нестационарности сводится к проверке того, что α=1. Поэтому это и называется тестированием процесса единичного корня (проверка α=1).
Теперь вычтем из обеех частей yt-1
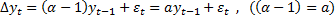
H0: a=0
H1: a<0
t=a/sa=a/корень(D(a))
если|tнабл|< tкр => Ho, ряд нестационарныйй, альфа=1
| tнабл|> tкр => H1 =>стационарный ряд, а-значим
a. Тест Дики-Фулера (ADF – расширенный тест Дики-Фулера)
H0: a=0
H1: a<0
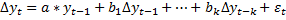
Количество запаздываний приростов (к) определяется по графикам автокорреляционной функции. Автокорреляционную функцию смотреть (ADF) для дельта yt.
Далее рассчитывается t и сравнивается с критическим, т.к. было в предыдущем случае.
Важно: в бел. программах.
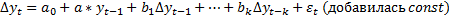
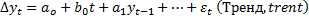
Последние 2 модели необходимо учитывать, т.к. необходимо учитывать тренд и сезонность. В лабораторных уже все очищено от тренда и сезонности. В крайнем случае может быть модель 2 со спецификацией.
Есть 2 класса:
1. TS (I(0) – интергрированные 0-ого порядка, т.е. можно сразу использовать для моджелирования)– тренд-стационарные:
a. стационарные по всем характеристикам (мат.ожидание, дисперсия и ковариация).
b. нестационарные по математическому ожиданию, т.е. он стационарный по тренду.
2. DS (I(1) – интегрированность первого порядка, что означает, что нестационарный ряд необходимо свести к стационарному: 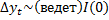 ):
):
a. Нестационарные по всем характеристикам.
b. Нестационарные по математическому ожиданию, содержащие стохастический тренд, т.к. тренд может быть недетерминирован. К такому тренду нельзя подобрать ни одной стохастическую кривую роста.
c. Нестационарны по дисперсии
b. Статистика Льюнга-Бокса
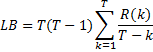
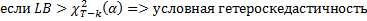
α=0,05
P<0,005 => H1, есть условная гетероскедастичность
P>0,005 => H0, нет условной гетероскедастичности
Присутствует в финансовых рядах (обменные курсы и т.д.), тогда говорят о волантильности, есть гетероскедастичность, временами дисперсия, то возрастает, то уменьшается периодами.
Для развитых стран – стационарные ряды, для неразвитых – нестационарные.
К TS рядам относят и ARCH модели. А DS – нестационарно по модели.
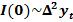 ,
, 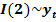
3. Модели ARMA и ARIMA. Адаптивная модель Брауна
ARMA – это модели для стационарных рядов.
ARIMA – это модели для нестационарных рядов. Расшифровывается как модели проинтегрированного. Если I(1), то дельта в первой степени, елси I(2), то дельта берутся в квадрате (см. выше жирным выделена).
Простейший стационарный – «белый шум», математическое ожидание и ковариация равны нулю, дисперсия = сигма квадрат. Тогда мы говорим, что наш ряд распределен нормально: 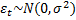 , ARMA (p,q).
, ARMA (p,q).
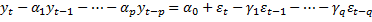
Определяем по корреляционным и автокорреляционным функциям p и q
p(AR) по PACF
MA по ACF
Если p и q > 4, то вызывает сомнения.
AR – это 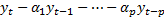 . AR стационарна, если корни характеристического уравнения (
. AR стационарна, если корни характеристического уравнения (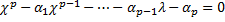 ) лежат внутри круга.
) лежат внутри круга.
|λi|<1 i=от 1 до p.
MA – это (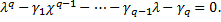 Она обратима, если корни характеристического уравнения лежат внутри единичного круга.
Она обратима, если корни характеристического уравнения лежат внутри единичного круга.
ARIMA:
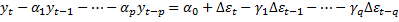
Последовательность построения ARMA и ARIMA по методологии Бокса-Дженкинса. Этапы:
1. Идентификация – это построение ACF и PCF функций, исследование стационарности (Дики-Фулер, к примеру), определение порядка модели при помощи частных автокорреляционных функций.
2. Параметризация по МНК (в EViews есть встроенные AR(1), MA(1), c=const).
3. Анализ адекватности – верификация моделей: проверяем наличие условной гетероскедастичности (Лагранжа??), автокорреляция (если неправильно определили порядки – изменить порядки), мультиколлениарность. Качественная модель не должна содержать пропущенных переменных и желательно была экономной, т.е. должна иметь наименьший критерий AIC (Акайки) и SC (Шварца) и меньшее MAPE (если ниже 10%, то отличная модель).
a. Адаптивная модель Брауна
Адаптивное сглаживание и вообще модели базируются на схеме скользящего среднего. В простейшем случае схема скользящего среднего (трехчленное сглаживание), то абсолютные значения заменяются средними арифметическими или среднем арифметическим скольжением.
Y’1
Y’1=(y1+y2+y3)/3
Y’k=(yk-1+yk+yk+1)/3
Y’T
Степени свободы: (T-1-m). При потере наблюдений теряются степени свободы.
Адаптивное сглаживание считает более ценную информацию, которая находится в конце исследуемого периода, ближе к началу прогнозного периода.
0<α<0 (коэффициент дисконтивраония)
β=1-α (бета – коэффиционт сглаживания)
α=2/(m+1)
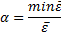
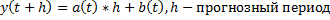
Чтобы определить параметры, используется:
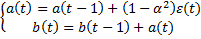
a(0) и b(0) определяется по МНК по первым значениям кривой роста полинома первого порядка. Объем выборки, предположим, V=12, m=10, альфа=2/(10+1)=2/11
f(t)=-0,0009t+1,15, т.е. получили кривую роста.
Определяем a(0) по первому значению: a(0)=-0,0009. b(0)=1,15, 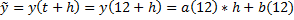 . A(12) и b(12) определяются из выражения с фигурной скобкой. Ответ:
. A(12) и b(12) определяются из выражения с фигурной скобкой. Ответ:
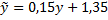
8. Методы анализа панельных данных
1. Структура панельных данных. Характеристики эффектов
Преимущества использования панельных данных:
· Увеличение объема выборки.
· Позволяет анализировать множество экономических вопросов, которые невозможно рассматривать только по временной или только по пространственной выборке.
· Панельные данные позволяют предотвратить смещение агрегированности (индивидуальные характеристики не учитывают динамики).
· Можно проследить эволюцию индивидуального объекта во времени.
· Позволяет бороться с нарушением предпосылок МНК (в частности, когда случайные отклонения коррелируют с иксами).
· Дают возможность избежать ошибок спецификации из-за не включения в модель важных параметров. В противном случае может возникнуть гетероскедастичность.
Общий вид панельной регрессии:
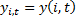
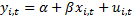
* 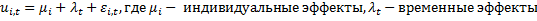
1) 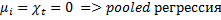
2) 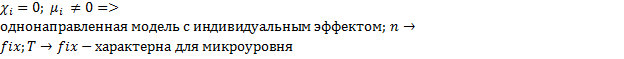
3) 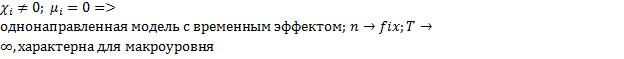
4) 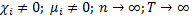
Гетерогенный – свойства объектов изменяются в пространстве и времени
Гомогенный - 
Рассмотрим ситуация, когда бета постоянный угловой коэффициент: 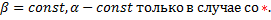
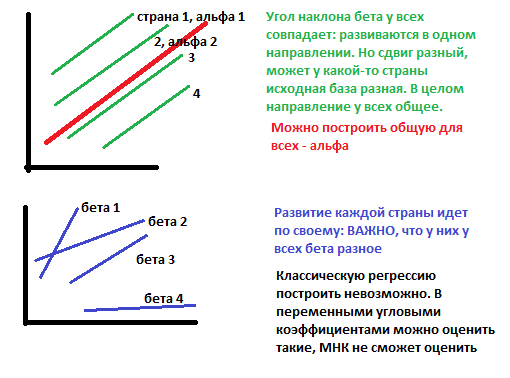
Эти эффекты разделяются на случайные (абсолютно не важно какие данные вибырать) и фиксированные (когда выбираем определенную страну и показатели): мю и лямбда.
Фиксированные эффекты:
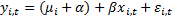
Случайные эффекты:
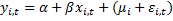
В лабораторной брать 10 лет, потому что если брать больше то может возникнуть нестационарность.
Тесты:
1) Проверка на возможность объединение временных рядов в панель – Poolability test, F-ability.
Гипотеза о постоянстве углового коэффициента:
H0: 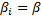
H1: 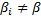
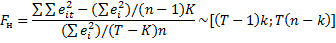
n – объем пространственного ряда
K – количество объясняющих переменных
е – дисперсия
Т – объем временного промежутка
2) Наличие фиксированных эффектов проверяется F-тестом.
H0: 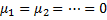
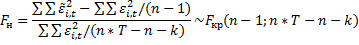
Если наблюдаемое больше критического, то (или р значение мало) вероятность принятия нулевой гипотезы мала и равна этому числу.
3) Тестирование случайных эффектов – на основе множителей Лагранжа, та же проверка гетероскедастичности, т.е. тест Бреуша-Паккона
H0: 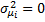
H1: 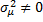
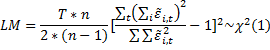
Имеет хи-распределение
4) Тест Хаусмана – говорит какие эффекты(случайные или фиксированные), потому что если брать только один тест, то можно не достигнуть точности. Т.е. могут быть одновременно и фиксированы и случайные эффекты. Бывают погнаничные также ситуации.
H0: 
H1: 

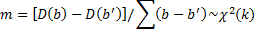
b. Классификация моделей анализа панельных данных
Классификация моделей анализа панельных данных:
1. Коэффициент наклона (гомогенный). Свободный член гетерогенный:
a. Однонаправленная модель: 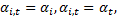
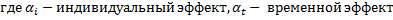
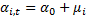
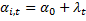
i. 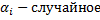
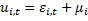
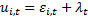
Обобщенный МНК (feasible FGLS)
ii. 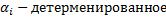
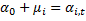
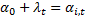
1. LSDV
2. between
3. within
b. Двунаправленная модель с индивидуальными временными остатками, может быть эффект гетероскедастичности иавтокорреляции: 
i. 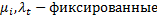
ii. 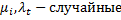
2. Коэффициент наклона (гомогенный) – свободный член гомогенен
3. Коэффициент наклона гетерогенный
a. 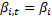 (только по i)
(только по i)
Деляться на 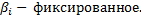 Т.е. модель с мульпликативными данными;
Т.е. модель с мульпликативными данными;
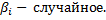 Модель Суами LSMDV
Модель Суами LSMDV
b. 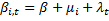 (по i и t)
(по i и t)
2. Способы оценки параметров панельной регрессии
a. Метод оценки моделей с фиксированными эффектами. Метод МНК с фиктивными переменными
Фиктивных переменных меньше чем самих переменных на 1.
i –фиктивная переменная
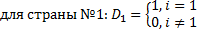
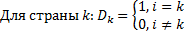

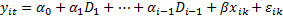
b. Within преобразование
Рассматриваем вместо Х и У отклонения от средних значений для каждого пространственного объекта:
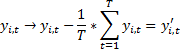
Аналогично Х.
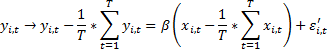
c. Between
Вместо Х и У рассматриваются средние:
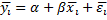
d. FGLS – Обобщенный единый МНК – Метод для моделей со случайными эффектами
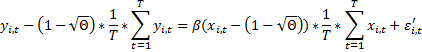
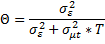
e. Сравнительный анализ методов
| Признак | LSDV | Within | Between | FGLS |
| Функциональная форма | 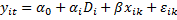 | |||
| Dummy (фиктивные переменные) | Есть: 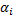 | Нет(можно рассчитать): 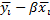 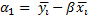 | Нет | Нет |
| Const | Есть | Нет | Есть | Нет |
| R2 | Верный | Неверный | Верный | Верный |
| Степени свободы | nT-n-k | nT-k (больше всего степеней свободы) | n-k | nT-k (больше всего степеней свободы) |
| Количество наблюдений | nT | nT | n | nT |
| BLUE | Состоятельные, эффективные, несмещенные | Состоятельные, эффективные и несмещенные | Несостоятельные, неэффективные и несмещенные | Состоятельные, эффективные и несмещенные |
3. Динамические модели на основе панельных данных
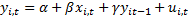
GMM – обобщенный метод оценки применяется для оценки альфа, бета, гамма. В методе моментов необходимо выбирать инструменты. Оценки Аррелана и Бонда применялись на микроуровне. На макроуровне – Кивиетом. В Eviews можно подбирать эти инструменты.
1. 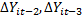
2. 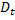
3. 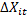 ,
, 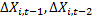
Главное чтобы коррелировались инструменты с У, и не коррелировались со случайными отклонениями.
Тест Саржан – на идентифицированность моментных тождеств.
9. Гравитационные модели
1. Модели планирования территориального развития
Гравитационные модели применяются для анализа и прогноза различных социально-экономических процессов между районами города, населенными пунктами, регионами страны, странами, регионами в рамках мировой экономики.
Сила взаимодействия между i и j регионами. Прямо пропорционально численности населения и обратно – расстоянию между городами (пунктами):
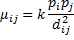
Теория гравитационной модели была разработана американцем Стюартом. Он предложил формулу для демографического потенциала V, создаваемого в точке Х:
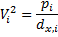
Суммарный: 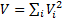
Применяются гравитационные модели для процессов миграционного взаимодействия, используются для построения «модели Города» (модели расселения в городе), широкого используются в логистике.
РСУНОК
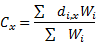
Аналогично и для y.
C – затраты на перевозку; d- расстояние, W – объем перевозимых товаров.
Развитие простейшей гравитационной модели.
Дополнительные факторы:
· Отношение приростов инвестиций в районах;
· Число вакантных рабочих мест;
· Доля безработных в численности населения.
Второе направление в Г.М.: когда показателем численности населения придаются некоторые весовые коэффициенты.
Гравитационные модели широко включаются в разнообразные модельные конкурсы для анализа, прогнозирования территориального развития.
Существует определенная зависимость между населением городов, структурой и масштабами производства. Отрасли имеющие большие масштабы, сложные специализированные производства развиваются преимущественно в регионах с большим количеством городов. Отрасли сферы услуг, потребления, ремонтных мастерские, производство строительных материалов – характеризуются небольшими масштабами производства и их желательно размещать в небольших по численности населения пунктах. По мере увеличения размеров города, растет значение обрабатывающей промышленности. Доля населения занятого в обрабатывающей промышленности выше в средних городах, в крупных – услуг (образование, банковская сфера, коммуникации и т.д.), в столицах с выгодным географическим расположением – предприятия обрабатывающего направления.
2. Внешнеторговые гравитационные модели
Они базируются на предположении, что объем двусторонних торговых потоков во внешнеторговых моделях – это, как правило, пропорционален размеру экономик (измеряется по разному: численность, ВВП и т.д.)
Прямо пропорционален размеру экономик и обратно пропорционален расстоянию между ними. Д. Андерсон и Э. ван Винкуп – систематизировали и добавили переменную многостороннего сопротивления (барьеры и т.д.). чем больше барьер, тем сильнее регионы будут стремиться торговать между друг другом.
Роуз: модель без барьеров – вхождение в ВТО не значимо.
Размер экономик определяет размер смещения торговли. Это означает, что торговые барьеры снижают в относительном выражении торговлю между большими странами больше, чем торговлю между маленькими странами.
Торговые барьеры увеличивают в относительном выражении торговлю между регионами внутри маленькой страны больше, чем межрегиональную торговлю внутри большой страны. Маленькие страны торгуют больше в относительном выражении внутри границ, по сравнению с объемом общей торговли.
Пример:
А – 100 регионов
Б – 2 региона
Все регионы имеют одинаковый ВВП и в каждый регион продают по одной единице товара, т.е. 102 ед.товара. страна А экспортирует 100 товаров, Б – 2. Допустим, что между А и Б существует граница, снижающая их торговлю на 20%, т.е. на 20,4 ед.товара. производство товара не снижается, а то, что раньше производилось продаётся внутри своей страны. Согласно Г.М., каждый регион страны Б экспортирует на 20 товаров меньше, а у А – на 0,4 товара меньше. Каждый регион Б продает внутри 11 товаров (20/2+1). У страны А = 1+0,4/100 = 1,004. Вывод: при снижении торговли на 20%, в маленькой стране внутренняя торговля вырастет в 11 раз, а в большой только в 0,4 раза.
Модель, построенная для экспорта Исландии:
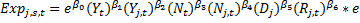
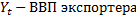 .
.
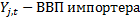 .
.
D – расстояние.
Можно добавлять обменный курс R:
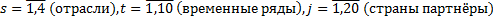
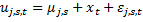
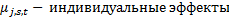 .
.
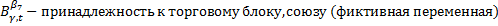 .
.
Оценивается LSDV. Таких моделей для РБ не было: разбивается экспорт по товарных группам.
j – экспорт в j-ую страну, сектора s, t – время
10. Матрично-балансовые модели
Собственный вектор, собственное значение, определитель и т.д.
1. Разработка и развитие балансового метода
Баланс – это таблица состоящая из двух колонок: 1ая: отражает ресурсы (доходы), 2ая: отражает распределение ресурсов. Актив = Пассиву
Баланс трудовых ресурсов необходим для политики занятости:
· Можно определить уровень безработицы
· Видеть структуру (пример, какая доля потребления продовольственных товаров, по уровню квалификации)
| Наличие трудовых ресурсов | Распределение трудовых ресурсов |
| Трудоспособное население в трудоспособном возрасте | По видам деятельности (учащиеся старше 16 лет, занятые в домашнем хозяйстве, занятые в производстве) |
| Работающие подростки и пенсионеры | По отраслям (32 отрасли). Можно короче: промышленность, С/х, строительство, услуги. Можно агрегировать: производственные и непроизводственные |
| По формам собственности | |
| По уровню квалификации | |
| По уровню образование | |
| По специальностям | |
| И т.д. | |
| Безработные – это разница суммы 1 и всех занятых | |
| СУММА 1 | СУММА 2 |
Экономически активное население = занятое население + безработные.
Безработица = численность безработных/экономически активное население*100%
Безработица = численность безработных/трудоспособное население*100%
Трудоспособное население = численность населения*коэффициент трудоспособного населения

