 2015-08-21
2015-08-21 1083
1083Алгоритм GDM, или алгоритм градиентного спуска с возмущением [18], предназначен для настройки и обучения сетей прямой передачи. Этот алгоритм позволяет преодолевать локальные неровности поверхности ошибки и не останавливаться в локальных минимумах. С учетом возмущения метод обратного распространения ошибки реализует следующее соотношение для приращения вектора настраиваемых параметров:
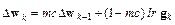 , (3.21)
, (3.21)
где 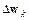 – приращение вектора весов; mc – параметр возмущения; lr – параметр скорости обучения;
– приращение вектора весов; mc – параметр возмущения; lr – параметр скорости обучения; 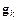 – вектор градиента функционала ошибки на k -й итерации.
– вектор градиента функционала ошибки на k -й итерации.
Если параметр возмущения равен 0, то изменение вектора настраиваемых параметров определяется только градиентом, если параметр равен 1, то текущее приращение равно предшествующему как по величине, так и по направлению.
Вновь рассмотрим двухслойную нейронную сеть прямой передачи сигнала с сигмоидальным и линейным слоями (см. рис. 2.6)
net = newff([–1 2; 0 5],[3,1],{'tansig','purelin'},'traingdm');
Последовательная адаптация. Чтобы подготовить модель сети к процедуре последовательной адаптации на основе алгоритма GDM, необходимо указать ряд параметров.
В первую очередь это имя функции настройки learnFcn, соответствующее алгоритму градиентного спуска с возмущением, в данном случае это М-функция learngdm:
net.biases{1,1}.learnFcn = 'learngdm';
net.biases{2,1}.learnFcn = 'learngdm';
net.layerWeights{2,1}.learnFcn = 'learngdm';
net.inputWeights{1,1}.learnFcn = 'learngdm';
С этой функцией связано 2 параметра – параметр скорости настройки lr и параметр возмущения mc.
При выборе функции learngdm по умолчанию устанавливаются следующие значения этих параметров:
net.layerWeights{2,1}.learnParam
ans =
lr: 0.01
mc: 0.9
Увеличим значение параметра скорости обучения до 0.2:
net.layerWeights{2,1}.learnParam.lr = 0.2;
Мы теперь почти готовы к обучению сети. Осталось задать обучающее множество
и количество проходов, равное 50:
p = [–1 –1 2 2;0 5 0 5];
t = [–1 –1 1 1];
p = num2cell(p,1);
t = num2cell(t,1);
net.adaptParam.passes = 50;
tic, [net,a,e] = adapt(net,p,t); toc
elapsed_time = 4.78
a, mse(e)
ans = [–1.0124] [–0.98648] [1.0127] [0.9911]
ans = 1.4410e–004
Эти результаты сравнимы с результатами работы алгоритма GD, рассмотренного ранее.
Групповое обучение. Альтернативой последовательной адаптации является групповое обучение, которое основано на применении функции train. В этом режиме параметры сети модифицируются только после того, как реализовано все обучающее множество, и градиенты, рассчитанные для каждого элемента множества, суммируются, чтобы определить приращения настраиваемых параметров.
Для обучения сети на основе алгоритма GDM необходимо использовать М-функцию traingdm взамен функции настройки learngdm. Различие этих двух функций состоит
в следующем. Алгоритм функции traingdm суммирует градиенты, рассчитанные на каждом цикле обучения, а параметры модифицируются только после того, как все обучающие данные будут представлены. Если проведено N циклов обучения и для функционала ошибки оказалось выполненным условие 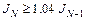 , то параметр возмущения mc следует установить в 0.
, то параметр возмущения mc следует установить в 0.
Вновь обратимся к той же сети
net = newff([–1 2; 0 5],[3,1],{'tansig','purelin'},'traingdm');
Функция traingdm характеризуется следующими параметрами, заданными по умолчанию:
net.trainParam
ans =
epochs: 100
goal: 0
lr: 0.0100
max_fail: 5
mc: 0.9000
min_grad: 1.0000e–010
show: 25
time: Inf
По сравнению с функцией traingd здесь добавляется только 1 параметр возмущения mc.
Установим следующие значения параметров обучения:
net.trainParam.epochs = 300;
net.trainParam.goal = 1e–5;
net.trainParam.lr = 0.05;
net.trainParam.mc = 0.9;
net.trainParam.show = 50;
p = [–1 –1 2 2;0 5 0 5];
t = [–1 –1 1 1];
net = train(net,p,t); % Рис. 3.9
На рис. 3.9 приведен график изменения ошибки обучения в зависимости от числа
выполненных циклов.
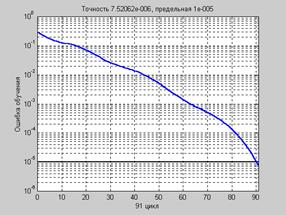 Рис. 3.9
Рис. 3.9
a = sim(net,p)
a = –0.9956 –0.9998 0.9969 1.0009
Поскольку начальные веса и смещения инициализируются случайным образом, графики ошибок на рис. 3.8 и 3.9 будут отличаться от одной реализации к другой.
Более тщательно ознакомиться с методом градиентного спуска с возмущением можно с помощью демонстрационной программы nnd12mo, которая иллюстрирует работу алгоритма GDM.
Практика применения описанных выше алгоритмов градиентного спуска показывает, что эти алгоритмы слишком медленны для решения реальных задач. Ниже обсуждаются алгоритмы группового обучения, которые сходятся в десятки и сотни раз быстрее. Ниже представлены 2 разновидности таких алгоритмов: один основан на стратегии выбора параметра скорости настройки и реализован в виде алгоритма GDA, другой – на стратегии выбора шага с помощью порогового алгоритма обратного распространения ошибки и реализован в виде алгоритма Rprop.

