 2015-09-06
2015-09-06 330
330Пример
Сжать методом LZW цепочку символов
a b b a a b b a a b a b b a a a a b a a b b a
Инициализируем словарь символами а и b, так как другие символы в цепочке не встречаются. Берём первый символ из входного потока – а. Есть ли это слово (пока односимвольное) в словаре? Есть, тогда берём следующий символ из потока – b и присоединяем его к текущему слову, т.е. к а. Есть ли получившееся слово ab в словаре? Нет, тогда добавляем его в словарь, а в выходной поток записываем номер слова а. Теперь набор новой комбинации начинается с символа b. Берём следующий (третий) символ из входного потока – b и добавляем его к текущему слову – b. Есть ли слово bb в словаре? Нет - добавляем его в словарь, а в выходной поток записываем номер слова b, и т. д. В результате получаем следующий словарь:
a | b| b | a | a b | b a | a b | a b b | a a | a a | b a a | b b | a
0 1 1 0 2 4 2 6 5 5 7 3 0
| номер слова | слово | номер слова | слово |
| a | baa | ||
| b | aba | ||
| ab | abba | ||
| bb | aaa | ||
| ba | aab | ||
| aa | baab | ||
| abb | bba |
и сжатый выходной поток, состоящий только из ссылок (номеров слов):
0 1 1 0 2 4 2 6 5 5 7 3 0
Если предположить, что входной поток был байтовым, и на каждую ссылку отводится тоже один байт, то получаем коэффициент сжатия k =23/13»1.7
Примечание: при расчёте коэффициента сжатия для алгоритма LZW не учитывается размер самого словаря, поскольку при распаковке сжатых данных словарь составляется динамически по аналогичной схеме.
В реальных программах сжатия алгоритм LZW редко применяется в чистом виде. Это связано с преодолением некоторых практических трудностей при реализации. Одна из них связана с тем, что словарь имеет ограниченный размер, так как под код ссылки отводиться некое фиксированное количество бит. Например, если ссылка кодируется одним байтом, то словарь может вместить максимум 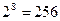 различных слов. Следовательно, существует риск переполнения, поэтому фиксированный размер словаря снижает эффективность сжатия. Для решения этой проблемы на практике применяют различные стратегии ведения словаря. В целях повышения скорости работы алгоритма применяют также оптимизацию поиска слов с использованием древовидной структуры словаря или хеш-таблиц. Кроме этого, для достижения максимального сжатия, выходной поток алгоритма LZW кодируется одним из статистических методов, например кодом Хаффмана. Такая схема сжатия используется в широко известных архиваторах RAR и ZIP.
различных слов. Следовательно, существует риск переполнения, поэтому фиксированный размер словаря снижает эффективность сжатия. Для решения этой проблемы на практике применяют различные стратегии ведения словаря. В целях повышения скорости работы алгоритма применяют также оптимизацию поиска слов с использованием древовидной структуры словаря или хеш-таблиц. Кроме этого, для достижения максимального сжатия, выходной поток алгоритма LZW кодируется одним из статистических методов, например кодом Хаффмана. Такая схема сжатия используется в широко известных архиваторах RAR и ZIP.








