 2018-02-14
2018-02-14 1858
1858Для построения таблицы описательных статистик следует при активном окне с модельными данными запустить процедуру Descriptive statistics. Сделать это можно из блока процедур Basic Statistics and Tables по меню кнопки Analysis. В результате раскроется диалоговое окно. Сначала в этом окне следует определиться с именами переменных, для которых будут вычисляться описательные статистики. Для этого нужно кликнуть слева вверху окна по клавише Variables: и среди появившегося списка переменных выбрать требуемые. Результат выбора можно отследить справа от клавиши Variables:.
Кнопка More Statistics отвечает за подсчет тех величин, которые вы хотите найти. Программа предлагает вычисление следующих статистик:
Valid N – число элементов выборки;
Mean – среднее значение;
Sum – сумма;
Median – оценка медианы;
Standard Deviation – стандартное отклонение (среднее квадратическое отклонение);
Variance – несмещенная оценка дисперсии;
Standard error of me an – стандартная ошибка среднего;
95% confidence limits of mean – 95%-е доверительные интервалы для среднего (математического ожидания генеральной совокупности);
Minimum & maximum – максимальное и минимальное значение выборки;
Lower & upper quartiles – верхний и нижний квартили;
Range – размах (разность между максимумом и минимумом);
Quartiles range – разность между верхним и нижним квартилем;
Skewness – выборочный коэффициент асимметрии;
Kurtosis – выборочный коэффициент эксцесса;
Standard error of skewness – стандартная ошибка коэффициента асимметрии;
Standard error of kurtosis – стандартная ошибка коэффициента эксцесса.
Построить корреляционную матрицу можно из блока процедур Basic Statistics and Tables по меню кнопки Analysis, запустив процедуру Correlation Matrics.
При использовании тестов на нормальных данных нужно обратиться к списку процедур блока Basic Statistics and Tables. Если такого списка в текущий момент не видно, достаточно войти в меню кнопки Analysis. Затем из списка следует запустить процедуру t-test. В результате откроется диалоговое окно. Далее нужно не забыть определиться с переменными (кликнуть по клавише Variables). Наконец отправляется процедура на исполнение кликом по клавише T-tests (или OK). В итоге выдаются результаты теста Стьюдента (выборочное значение статистики) и его достигнутый уровень значимости – в процедуре это величины t-value и p, а также приводятся результаты теста Фишера (выборочное значение статистики и его достигнутый уровень значимости – в процедуре это величины F-ratio variancs и p variancs).
В пакете STATISTICA существует функция Graphs Gallery (Графическая Галерея), на рабочем столе она расположена в середине левого вертикального ряда инструментальных кнопок. Щелкнув по этой кнопке, попадаем в окно, в левой части которого выбирается пространство, где будет осуществляться построение графика, в правой выбирается тип графика. В этом диалоговом окне представлены различные виды графиков, которые можно построить.
Для оценки параметров парной регрессии можно воспользоваться модулем «Множественная регрессия». В качестве независимой переменной указать Х, а в качестве зависимой – Y (рис. 5). В поле MD deletion указывается способ исключения из обработки недостающих данных: casewise – игнорируется вся строка, в которой есть хотя бы одно пропущенное значение; mean Substitution - взамен пропущенных данных подставляются средние значения переменных; pairwise – попарное исключение данных с пропусками из тех переменных, корреляция которых вычисляется. Также может быть задано ограничение на использование наблюдений при оценке параметров регрессии с помощью кнопки  .
.
После нажатия кнопки «ОК» в окне модуля множественной регрессии появится окно результатов, в котором отображаются основные характеристики построенной зависимости (рис. 6).
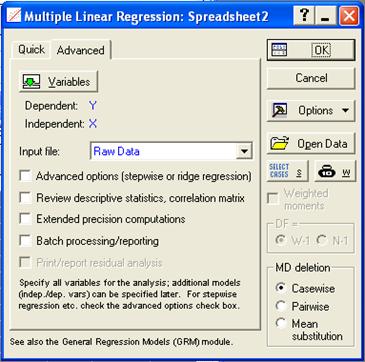
Рис. 5. Модуль множественной регрессии: выбор переменных
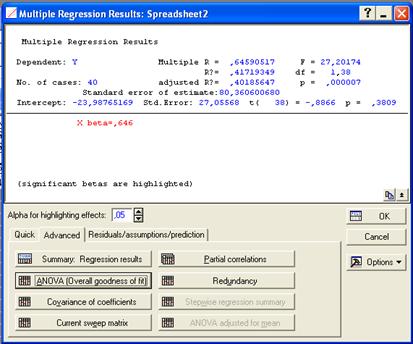
Рис. 6. Окно результатов для множественной регрессии
В верхней части окна приводятся наиболее важные параметры полученной регрессионной модели:
Multiple R – коэффициент множественной корреляции (характеризует тесноту линейной связи между зависимой и всеми независимыми переменными, может принимать значения от 0 до 1.);
R2 или RI – коэффициент детерминации; численно выражает долю вариации зависимой переменной, объясненную с помощью регрессионного уравнения (чем больше R2, тем большую долю вариации объясняют переменные, включенные в модель);
adjusted R – скорректированный коэффициент множественной корреляции (этот коэффициент лишен недостатков коэффициента множественной корреляции. Включение новой переменной в регрессионное уравнение увеличивает RI не всегда, а только в том случае, когда частный F-критерий при проверке гипотезы о значимости включаемой переменной больше или равен 1. В противном случае включение новой переменной уменьшает значение RI и adjusted R2 );.
adjusted R2 или adjusted RI – скорректированный коэффициент детерминации (скорректированный R2 можно с большим успехом (по сравнению с R2) применять для выбора наилучшего подмножества независимых переменных в регрессионном уравнении);
F – критерий Фишера;
df – число степеней свободы для F -критерия;
p – вероятность нулевой гипотезы для F -критерия;
Standard error of estimate – стандартная ошибка оценки (уравнения);
Intercept – свободный член уравнения;
Std.Error – стандартная ошибка свободного члена уравнения;
t – критерий Стьюдента для свободного члена уравнения;
p – вероятность нулевой гипотезы для свободного члена уравнения;
Beta -коэффициент уравнения.
Это стандартизированные регрессионные коэффициенты, рассчитанные по стандартизированным значениям переменных. По их величине можно сравнить и оценить значимость зависимых переменных, так как β-коэффициент показывает на сколько единиц стандартного отклонения изменится зависимая переменная при изменении на одно стандартное отклонение независимой переменной при условии постоянства остальных независимых переменных. Свободный член в таком уравнении равен 0.
Нажимая на кнопки вкладки «Advanced», можно получить подробную информацию о коэффициентах оцениваемой модели
Кнопка Regression summary – позволяет просмотреть основные результаты регрессионного анализа:
BETA –коэффициенты уравнения;
St. Err. of BETA – стандартные ошибки коэффициентов;
В – коэффициенты уравнения регрессии;
St. Err. of B – стандартные ошибки коэффициентов уравнения регрессии;
t(95) – критерии Стьюдента для коэффициентов уравнения регрессии;
р-level – вероятность нулевой гипотезы для коэффициентов уравнения регрессии.
Также можно получить информацию о взаимосвязи между независимыми переменными и коэффициентами при данных переменных, однако эти сведения будут более информативными в случае множественной регрессии.
Кнопка Partial correlations – позволяет просмотреть частные коэффициенты корреляции (Partial Cor.) между переменными. Частная корреляция – это корреляция между двумя переменными, когда одна или больше из оставшихся переменных удерживаются на постоянном уровне (т.е. имеют постоянное значение).
На вкладке «Residuals» можно провести анализ остатков, изучить описательные статистики, характеризующие рассматриваемые переменные, а также построить точечный и интервальный прогнозы для среднего и одиночного наблюдений.
«Анализ остатков» позволяет получить значения остатков и регрессионных значений эндогенной переменной. На данной вкладке можно также узнать значение статистики Дарбина-Уотсона и коэффициента автокорреляции остатков первого порядка. Кроме того, существует возможность построения гистограмм остатков и предсказанных значений, а также построения диаграмм рассеяния остатков в зависимости от регрессоров, фактических и расчетных значений эндогенной переменной (вкладка «Scatterplots»). Эти диаграммы могут быть использованы для визуального выявления проблем автокорреляции и гетероскедастичности.
При анализе остатков в полученной модели можно провести их проверку на выбросы (вкладка «Outliers» на рис. 7).
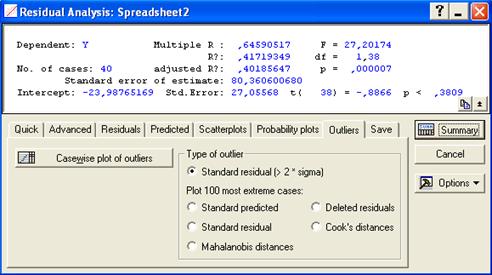
Рис. 7. Анализ остатков: проверка на выбросы
Выбросы – это остатки, которые значительно превосходят по абсолютной величине остальные. Выбросы показывают опытные данные, которые являются не типичными по отношению к остальным данным, и требуется выяснение причин их возникновения. Выбросы должны исключаться из обработки, если они вызваны ошибками регистрации, измерения. Для выделения имеющихся в регрессионных остатках выбросов предложен ряд показателей:
Показатель Кука (Cook's distances) – принимает только положительное значение и показывает расстояние между коэффициентами уравнения регрессии после исключения из обработки i -й точки данных. Большое значение показателя Кука указывает на сильно влияющий случай.
Расстояние Махаланобиса (Mahalanobis. distances) – показывает, насколько каждый случай или точка в k -мерном пространстве независимых переменных отклоняется от центра статистической совокупности.
Внимательный анализ остатков позволяет оценить адекватность модели. Остатки должны быть нормально распределены, со средним значением равным нулю и постоянной, независимо от величин зависимой и независимой переменных, дисперсией. Модель должна быть адекватна на всех отрезках интервала изменения зависимой переменной.
Для проведения Q -теста Льюинга-Бокса следует:
1) скопировать остатки в таблицу исходных данных (Copy with Headers) на место необходимой переменной. Далее вызвать модуль анализа временных рядов (Time Series) и выбрать в качестве анализируемой переменной Residual (рис. 8);
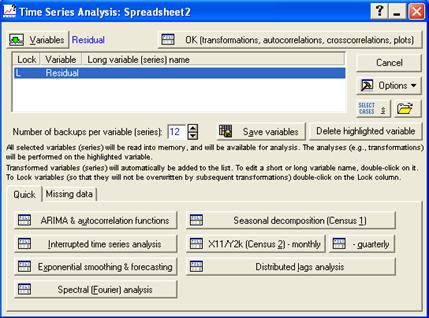
Рис. 8. Модуль анализа временных рядов: выбор переменной
2) нажать кнопку «OK (transformations…)», далее выбрать вкладку «Autocorrs» и установить число лагов равным 25 (рис. 9).
После нажатия на кнопку Autocorrelations появится коррелограмма и таблица, содержащая значения автокорреляционной функции и статистики Льюинга-Бокса.
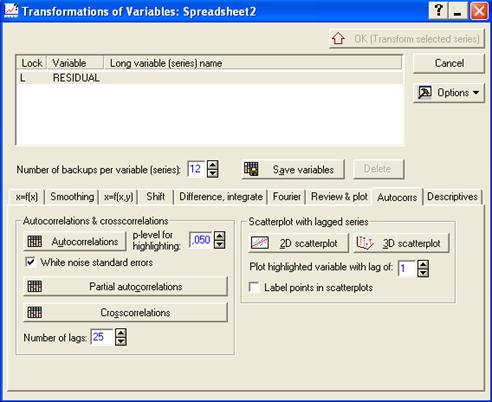
Рис. 9. Установление числа лагов
Поиск наилучшей регрессионной модели представляет собой довольно громоздкий процесс. При помощи опции Method пользователь может отказаться от стандартного проведения регрессионного анализа (Standard) и воспользоваться методами пошагового включения переменных в регрессионную модель (Forward stepwise) или пошагового исключения переменных (Backward stepwise) из регрессионной модели.
Опция Displaying results позволяет просматривать или же только итоговые результаты регрессионного анализа (Summary only) или после каждого шага включения или исключения переменных (At each step). Если необходимо получить регрессионную модель без свободного члена уравнения, тогда в списке поля Intercept нужно выбрать – Set to zero. Для пошаговых методов регрессионного анализа важно установить величину Tolerance (толерантность) и величины частного F - критерия для включения в модель (F to enter) и исключения из нее (F to remove). Установив величину толерантности создается барьер для включения в модель переменных, толерантность которых меньше установленной. Если величина толерантности переменной мала, то переменная несет малую дополнительную информацию и включение ее в модель не целесообразно. Какая либо новая независимая переменная, включаемая в модель, может сильно влиять на зависимую переменную, но если она включается в модель после других переменных, она может уже мало влиять на переменную отклика (например, из-за сильной коррелированности с переменными, уже включенными в модель). По умолчанию в пакете Statistica переменная включается в модель, если частный F -критерий больше или равен 1. Численное значение F -критерия для включения никогда не выбирается меньшим, чем численное значение F - критерия для исключения.

