 2014-02-02
2014-02-02 1084
1084OLAP-системы и Хранилища данных
Технологии интеллектуального анализа данных. Программные средства СППР
Лекция 2 часа
Во всем мире организации накопили и продолжают накапливать в процессе своей деятельности большие объемы данных. Эти коллекции данных представляют большие возможности по извлечению аналитической информации для принятия стратегических решений.
Попытки строить СППР, которые обращались бы непосредственно к базам данных систем оперативной обработки транзакций (OLTP-систем — On Line Transaction Processing), оказываются в большинстве случаев неудачными. Причинами чего являются:
1) аналитические запросы «конкурируют» с оперативными транзакциями, блокируя данные и вызывая нехватку ресурсов;
2) структура оперативных данных предназначена для эффективной поддержки коротких и частых транзакций, и в силу этого не обеспечивает необходимой скорости выполнения аналитических запросов;
3) в системе, как правило, функционирует несколько оперативных систем, использующие свои базы данных с различными структурами данных, единицами измерения, способами кодирования и т.д. Для конечного пользователя (аналитика) задача построения какого-либо сводного запроса по нескольким подобным базам данных практически неразрешима.
Для того чтобы обеспечить возможность анализа накопленных данных, создаваются хранилища данных (ХД), которые представляют собой интегрированные коллекции данных, которые собраны из различных систем оперативного доступа к данным. Хранилища данных становятся основой для построения СППР.
OLAP-системы и хранилища данных неразрывно связаны между собой, обусловливают друг друга и образуют единое целое. В основе концепции OLAP лежит принцип многомерного представления данных.
Хранилища данных могут быть разбиты на два типа: корпоративные хранилища данных и киоски (витрины) данных.
Корпоративные хранилища данных содержат информацию, относящуюся к корпорации (либо очень крупному объекту) и собранную из множества оперативных источников для консолидированного анализа. Корпоративное хранилище содержит детальную и обобщающую информацию; его объем может достигать составлять от десятков Гбайт до одного или нескольких терабайт.
Киоски (витрины) данных содержат подмножество корпоративных данных и строятся для более мелких объектов, входящих в состав более крупных. Киоски данных часто охватывают конкретный аспект. Киоск данных может получать данные из корпоративного хранилища (зависимый киоск), или, что более распространено, данные могут поступать непосредственно из оперативных источников (независимый киоск). Структурно хранилища данных могут состоять из киосков данных, последние включают в себя сенсоры, помогающие собирать информацию.
Идея Витрины Данных (Data Mart) возникла несколько лет назад, когда стало очевидно, что разработка корпоративного хранилища — долгий и дорогостоящий процесс. Это обусловлено как организационными, так и техническими причинами:
— информационная структура реальной системы, как правило, очень сложна, и руководство зачастую плохо понимает суть происходящих в системе процессов;
— технология принятия решений ориентирована на существующие технические возможности и с трудом поддается изменениям;
— может возникнуть необходимость в частичном изменении организационной структуры компании;
— требуются значительные инвестиции до того, как проект начнет окупаться;
— как правило, требуется значительная модификация существующей технической базы;
— освоение новых технологий и программных продуктов специалистами компании может потребовать много времени;
— на этапе разработки бывает трудно наладить взаимодействие между разработчиками и будущими пользователями хранилища.
Сейчас под Витриной Данных понимается специализированное независимое Хранилище. Попытки внедрения витрин данных оказались успешными, однако с ростом числа витрин данных растет сложность их взаимодействия, сделать их полностью независимыми не удается, поэтому разработка корпоративного Хранилища должна идти параллельно с разработкой и внедрением Витрин Данных.
Для хранения OLAP-данных могут использоваться различные структуры данных:
• Специальные многомерные СУБД (OLAP-серверы). В этом случае говорят о MOLAP (Multidimensional OLAP). При выполнении сложных запросов, анализирующих данные в различных измерениях, многомерные СУБД обеспечивают большую производительность, чем реляционные. При этом скорость выполнения запроса не зависит от того, по какому измерению производится «срез» многомерного куба, то есть поиск.
• Традиционные реляционные СУБД — ROLAP (Relational OLAP). Применение специальных структур данных — схемы «звезды» и «снежинки», а также хранение вычисленных агрегатов делает возможным многомерный анализ реляционных данных. Реляционные СУБД исторически более привычны и поэтому пока ROLAP-системы более распространены. Однако, с развитием других технологий (не только OLAP), скорее всего, произойдет отказ от реляционных структур данных.
• Комбинированный вариант — HOLAP (Hybrid OLAP), совмещающий и тот, и другой вид СУБД. Одним из вариантов совмещения двух типов СУБД является хранение агрегатов в многомерной СУБД, а детальных данных (имеющих наибольший объем) — в реляционной.
Несмотря на различия в подходах и реализациях, всем хранилищам данных свойственны следующие общие черты:
— Предметная ориентированность. Информация в хранилище данных организована в соответствии с основными аспектами деятельности объекта.
— Интегрированностъ. Исходные данные извлекаются из оперативных БД, проверяются, очищаются, приводятся к единому виду, агрегируются.
— Привязка ко времени. Данные в хранилище всегда напрямую связаны с определенным периодом времени.
— Неизменяемость. Данные попадают в определенный «исторический слой» хранилища и уже никогда не будут изменены. Стабильность данных также облегчает их анализ.
Стоит подчеркнуть, что технология OLAP сама по себе не подразумевает поддержку этапов принятия решений. Данная технология обеспечивает лишь анализ данных (предоставление интеллектуальных развернутых отчетов, анализ закономерностей, детализацию искомых показателей и т.д.), а не классическую схему принятия решений. В настоящее время схема принятия решений с использованием OLAP реализуется либо самим человеком, либо программными средствами-надстройками над OLAP системами. Известно, что такие средства поддержки принятия решений развиты на сегодняшний день весьма слабо.
OLAP-системы построены на двух базовых принципах:
— все данные, необходимые для принятия решений, предварительно агрегированы на всех соответствующих уровнях и организованы так, чтобы обеспечить максимально быстрый доступ к ним;
— язык манипулирования данными основан на использовании понятий, применяемых в системе (предметной области).
Как уже было отмечено, в основе OLAP лежит понятие гиперкуба, или многомерного куба данных, в ячейках которого хранятся анализируемые (числовые) данные, например объемы продаж. Измерения представляют собой совокупности значений других данных. В простейшем случае двумерного куба (квадрата) получается таблица, показывающая значения двух показателей. Дальнейшее усложнение модели данных может идти по нескольким направлениям:
— увеличение числа измерений;
— усложнение содержимого ячейки – в ячейке может быть несколько значений;
— введение иерархии в пределах одного измерения – общее понятие ВРЕМЯ естественным образом связано с иерархией значений: год состоит из кварталов, квартал из месяцев и т. д.
При описании технологии заполнения Хранилища различают три взаимосвязанные задачи: Сбор Данных, Очистка Данных и Агрегирование Данных.
Под Сбором Данных понимают процесс, который состоит в организации передачи данных из внешних источников в Хранилище. Лишь некоторые аспекты этого процесса полностью или частично автоматизированы в имеющихся продуктах. Прежде всего, это относится к интерфейсам с существующими БД. Как правило, здесь имеется несколько возможностей. Во-первых, поддерживаются интерфейсы всех крупных производителей серверов баз данных (Oracle, Informix, ADABAS и т.д.). Во-вторых, практически всегда имеется ODBC-интерфейс, и, в-третьих, можно извлекать данные из текстовых файлов в формате CSV (comma separated values) и из некоторых структурированных файлов, например файлов dBase. Набор имеющихся интерфейсов - важнейшая характеристика, которая часто позволяет оценить, для каких задач проектировался продукт.
Под Очисткой Данных обычно понимается процесс модификации данных по ходу заполнения Хранилища: исключение нежелательных дубликатов, восстановление пропущенных данных, приведение данных к единому формату, унификация типов данных, проверка на целостность.
Под Агрегированием Данных понимаются процессы объединения, «слияния» семантически связанных данных, поиск и анализ скрытых закономерностей в данных, т.е. выявление связей (в том числе и причинно-следственных) между различными показателями, не заданных в явном виде, расчет агрегированных показателей таких как средние, суммы, аппроксимации..
Таким образом, можно заключить, что использование Хранилищ данных дает следующие преимущества:
1) Данные, записанные в хранилище, являются «очищенными» по сравнению с данными, хранящимся в OLTP-системах. Это означает, что в хранилище погружаются не все данные, которые присутствуют в OLTP-системах, но лишь те, которые представляют интерес с точки зрения анализа. Например, в хранилище может быть занесена информация о проданных товарах, но не о времени продажи с точностью до секунды. Кроме того, в хранилище заносится производная информация, которая может упростить и ускорить последующий анализ — например, средние значения, суммы, аппроксимации и т.д.
2) В процессе погружения данные «связываются» между собой — унифицируются формы представления, формализуются логические связи, осуществляется «привязка» к одному моменту времени и т.д. В результате хранилище содержит не просто набор данных, но данные, взаимосвязанные между собой.
3) Хранилище данных объединяет между собой данные за промежутки времени, достаточно длительные для долговременного анализа. Это является существенным отличием от OLTP-систем, объединяющим информацию за небольшие промежутки времени. За счет фильтрации данных при погружении появляется возможность увеличить промежуток времени, к которому относятся данные в хранилище. Как правило, этот период равен нескольким месяцам или годам.
4) Информация, содержащаяся в хранилище, может быть представлена конечному пользователю в удобной для него форме.
Таблица 3.1. Сравнение характеристик данных в OLTP и OLAP-системах.
| Характеристика | Операционные | Аналитические |
| Частота обновления | Высокая частота, маленькими порциями | Малая частота, большими порциями |
| Источники данных | В основном внутренние | В основном внешние |
| Объемы хранимых данных | Сотни мегабайт, гигабайты | Гигабайты и терабайты |
| Возраст данных | Текущие (за период от нескольких месяцев до одного года) | Текущие и исторические (за период в несколько лет, десятки лет) |
| Назначение | Фиксация, оперативный поиск и преобразование данных | Хранение детализированных и агрегированных исторических данных, аналитическая обработка, прогнозирование и моделирование |
Для правильного понимания концепции Хранилищ данных необходимо понимание следующих принципиальных моментов:
- Концепция Хранилищ Данных — это не концепция анализа данных, скорее это концепция подготовки данных для анализа.
- Концепция Хранилищ Данных не предопределяет архитектуру целевой аналитической системы. Она говорит о том, какие процессы должны выполняться в системе, но не о том, где конкретно и как эти процессы должны выполняться.
- Концепция Хранилищ Данных предполагает не просто единый логический взгляд данные организации (как иногда это трактуется). Она предполагает реализацию единого интегрированного источника данных.
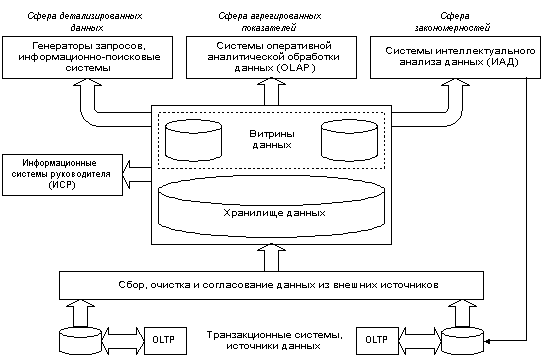
Рис. 3.2. Типовая архитектура Хранилищ данных.








