 2014-02-02
2014-02-02 414
414Таблица 2. Методы сжатия данных
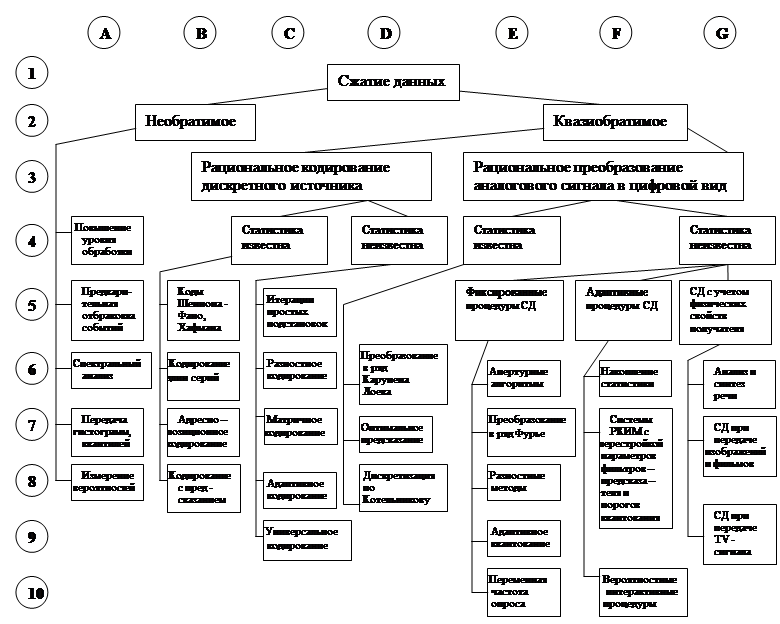
Рис. 2. Классификация методов сжатия данных
Классификация методов сжатия данных
Таблица 1. Действующие в настоящее время космические научные аппараты
Рис.1. Типовая структура информационной системы
Области применения и примеры использования сжатия данных
В настоящее время ряд областей науки и техники характеризуется исключительно большими объемами передаваемых и хранимых данных и в них целесообразно применение СД. Перечислим основные:
1. Космические исследования.
2. Физические эксперименты.
3. Вычислительная техника.
4. Средства связи.
5. Телеметрические системы.
6. Интернет.
7. Метеорология.
8. Библиотеки.
9. Архивы.
10. Системы видеонаблюдения.
11. Телевидение.
На рис. 1 представлена структура, характерная для большинства информационных систем.
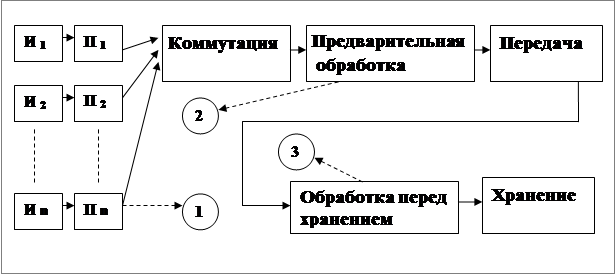
Как правило, имеется несколько источников информации (И1.....Иn). Это могут быть датчики, детекторы, данные ЭВМ и т.д. Вслед за источниками всегда находятся некоторые первичные преобразователи (П1.....Пn), которые преобразуют сигналы с источников к некоторому единому представлению. Например, АЦП, если источники аналоговые, а обработка дискретная. Поскольку источников несколько - необходима коммутация, т.е. опрос источников в соответствии с заданным алгоритмом. Например, это может быть циклический опрос, опрос с приоритетами и т.д. Под предварительной обработкой, как правило, понимают совокупность преобразований данных перед поступлением их в канал передачи. Это может быть отбраковка данных, контроль, сжатие, преобразование к формату канала и др.
Обработка перед хранением, как правило, включает в себя контроль данных, отбраковку, представление в виде соответствующем средству хранения. Цифрами 1, 2, 3 помечены блоки, в которых может быть реализована функция СД.
В качестве примера рассмотрим большой адронный коллайдер (БАК). БАК представляет собой кольцевой ускоритель окружностью 27 км, расположенный под землей, в монолитной скале, недалеко от Женевы. Следует отметить, что НИЯУ МИФИ весьма плотно сотрудничает с ЦЕРН по тематикам
коллайдера (изготовление датчиков БАК, написание программного обеспечения, анализ данных и т.д.). Преподаватели, аспиранты и студенты МИФИ постоянно работают в ЦЕРН, а результаты сотрудничества используются в учебном процессе МИФИ.
Этот пример выбран, поскольку он показывает, с какими объемами данных приходится иметь дело современным ученым. Очевидно, что данный эксперимент имеет огромное значение, как для науки, так и для образования.
БАК позволяет оперировать с самыми малыми расстояниями (вплоть до нанонанометра, или 10 –18 м) и энергиями порядка тераэлектронвольт (1 ТэВ = 1012 эВ).
При таких энергиях, теоретически возможна фиксация неуловимых частиц Хиггса, ответственных, как полагают, за
существование массы у других частиц, а также частиц, образующих темную материю, составляющую большую часть вещества во Вселенной.
Миллионы каналов данных от датчиков (блоки И1....Иn на рис.1) после первичного преобразования (блоки П1.....Пn на рис.1) создают общий объем данных порядка одного петабайта (миллиарда мегабайтов) каждые две секунды. Сырые данные поступают на систему обработки первого уровня. Этот уровень поддерживается сотнями специализированных компьютерных плат со схемной реализацией логики. На этой стадии отбираются (предварительная обработка, блок 2 на рис.1) 100 тыс. блоков данных в секунду (перспективные события) для более тщательного анализа на следующей стадии более высокого уровня. По сути, реализуется необратимое сжатие данных, поскольку общий объем информации, предоставляемый датчиками, несоизмеримо превосходит возможности обработки.
Система обработки данных должна уменьшать их поток до управляемой величины, и имеет несколько уровней. Система запуска более высокого уровня (блок 3 на рис.1) передает приблизительно 100 событий в секунду на концентратор вычислительных ресурсов глобальной сети БАК - распределенную вычислительную сеть GRID. Сеть объединяет мощности вычислительных центров и делает их доступными
пользователям, в том числе и образовательным учреждениям, предоставляя неоценимую «живую» физическую информацию. Сетевое программное обеспечение, при среднем времени между блоками данных, отобранных системой запуска первого уровня – 10 мкс, успевает «реконструировать» каждое событие. Программное обеспечение обеспечивает «привязку» следов частиц к общим исходным точкам. Далее оно «проектирует» события - формирует массивы энергий, импульсов, траекторий частиц. Затем происходит создание архивов на магнитных носителях. На каждом из этапов обработки производится дополнительное сжатие данных с возможностью последующего восстановления информации.
В области космических применений, потоки данных с космических аппаратов, независимо от их назначения, имеют
одну общую тенденцию - стремление к увеличению. Это связано с естественным желанием исследователей расширять номенклатуру, количество и длительность экспериментов.
Следует учитывать, что на бортовые системы сбора, обработки и передачи данных накладываются дополнительные условия, связанные с ограничениями на вес, габариты, потребляемую мощность систем летательных аппаратов, что является естественной преградой для удовлетворения возрастающих потребностей. В табл. 1 представлены аппараты, работающие в настоящее время.
| № | Аппарат | Объект изучения | Год запуска |
| «Марс-Одиссей» (НАСА США) (прибор «Хенд» РФ) | Марс. Научные измерения на орбите вокруг Марса. | ||
| «Марс – Экспресс» (ЕКА ЕС) (6 приборов РФ) | Марс. Научные измерения на орбите вокруг Марса. | ||
| «Венера Экспресс» (ЕКА ЕС) (6 приборов РФ) | Венера. Научные измерения на орбите вокруг Марса. | ||
| «Ресурс – КД» (РФ) (прибор «Памела») | Антивещество в солнечных лучах. Потоки антипротонов и позитронов. | ||
| «Лунный разведывательный орбитальный комплекс» (НАСА США) (система «ЛЕНД» РФ) | Поиск водяного льда в полярных районах Луны. | ||
| «Коронас – Фотон» (РФ) | Вспышки на Солнце. Мониторинг «космической погоды». | ||
| «Всемирная космическая обсерватория Ультрафиолет» (РФ) | Космические объекты и происходящие в них процессы. |
Данные взяты с официального сайта Федерального Космического Агентства и составляют лишь небольшую часть запущенных или планируемых к запуску спутников.
Применение СД на международных космических станциях позволило сократить объем передаваемых данных в десятки раз, что в свою очередь позволило увеличить время работы приборов за счет экономии бортовой памяти, предавать больше информации при тех же пропускных способностях каналов.
В ряде систем основной целью применения СД является экономия носителей информации, помещений для хранения
носителей и т.д. В этом случае СД осуществляется на этапе обработки данных перед хранением.
Особенно остро эта проблема стоит в архивах долгосрочного хранения на основе больших ЭВМ.
В НИЯУ МИФИ подобные задачи возникают перед физиками, получающими огромные потоки информации с космических объектов, в работе которых принимает участие МИФИ (пункты 4,6 в Таблице 1), кроме того рациональное хранение данных осуществляется в учебных компьютерных классах МИФИ, корпоративной сети МИФИ.
В настоящее время термин «сжатие данных» объединяет большое количество различных методов сокращения объемов передаваемых и хранимых данных. Эти методы различаются по целому ряду признаков. Они могут быть ориентированы на аналоговый или дискретный источники, быть адаптивными или неадаптивными, работать в условиях известных или неизвестных статистических характеристик источника сообщений и т.д.
В связи с этим, имеет смысл провести классификацию существующих методов сжатия, что позволит на ее основе, из всего множества методов сжатия, выбирать те, которые соответствуют поставленным задачам в каждом конкретном случае.
Данная классификация разработана мной на каф.12 и отличается от предыдущих тем, что в ней учитывается большее количество признаков методов сжатия и при этом для каждого метода можно определить набор этих признаков и, наоборот, для заданного набора признаков выбрать соответствующие методы.Классификация представлена на рис. 2.
Используются следующие признаки:
· восстанавливаемость (с определенной точностью) исходного сигнала;
· тип источника (аналоговый или дискретный источники);
· априорное знание статистики источника;
· адаптивность;
· вид воздействия на исходный сигнал.
Классификация построена таким образом, что все ее блоки адресуемы. На нижних уровнях классификации находятся списки названий методов.
Пусть, например, нас заинтересовало название «Кодирование длин серий» (блок В6). Из классификации выясняем (следуя снизу вверх), что этот метод относятся к рациональному кодированию, предполагает известной статистику источника сообщений, используется для кодирования дискретных источников, является квазиобратимым преобразованием. Наоборот, пусть требуется подобрать квазиобратимый метод сжатия аналогового источника, не зависящий от знания статистики и не требующий создания сложных адаптивных систем. Следуя сверху вниз, приходим к группе «Фиксированные процедуры СД» (блок Е5).
Все методы СД можно разбить на две основные группы, необратимое СД (блок В2) и квазиобратимое (блок F2). К необратимым методам относятся такие методы, после применения, которых невозможно восстановить все исходные данные целиком. В результате применения таких методов экспериментатор получает интересующие его характеристики исследуемого процесса, например, вероятности тех или иных событий, спектры и т.д. Применение такого метода - суть повышение уровня обработки на борту. При этом передаются не исходные данные, а окончательный результат вычислений, что естественно резко снижает объем передаваемых данных.
Однако необратимое сжатие принципиально неприменимо, если исследователи сами не могут четко сформулировать интересующие их параметры исходного процесса и требуют обязательной передачи всех исходных данных. Типичный для практики случай.
К квазиобратимому СД относятся все методы допускающие восстановление исходного представления исследуемого процесса с заданной точностью. Их можно разделить на две основные группы - рациональное кодирование дискретного источника (блок С3) и рациональное преобразование аналогового сигнала в цифровой (блок F3).
Ко второй группе относятся методы дискретизации и квантования непрерывного сигнала, учитывающие его естественную избыточность. Если статистика известна, наиболее применяемые процедуры – предсказание, интерполяция, передача вместо исходного непрерывного процесса коэффициентов разложения его в какой - либо ряд (блоки D6,7,8). Если статистика неизвестна, как правило, на практике применяются апертурные алгоритмы (блок Е6), поскольку они не требуют знания статистики источника, легко реализуются практически и обеспечивают высокие коэффициенты сжатия.
Особняком стоят методы СД с учетом физических свойств получателя (блоки G5,6.7,9). Они ориентированы на особенности человеческих органов чувств. Например, можно допустить такие искажения тембра голоса, которые позволят разобрать смысл сообщения и за счет этого снизить объем передаваемых данных. При передаче изображений используется уменьшение контрастности или яркости и т.д.
Рациональное кодирование используется для сжатия данных дискретных источников. В частности оно может рассматриваться, как второй этап сжатия данных непрерывного источника после дискретизации и квантования исходного сигнала.
В случае известной статистики источника, как правило, применяют различные варианты кодирования длин серий и адресно-позиционного кодирования (блоки В6,7), поскольку эти методы легко реализуются и не требуют громоздких таблиц соответствия. В тех случаях, когда наблюдается изменение во времени какой - либо величины, используется кодирование с предсказанием (блок В8). Для кодирования дискретных источников с небольшими алфавитами используются оптимальные методы статистического кодирования (коды Шеннона - Фано, Хафмана) (блок В5), позволяющие полностью устранить избыточность при известной статистике.
Задача сжатия данных дискретного источника существенно усложняется, если статистические характеристики источника не известны, известны не полностью, меняются во
времени (блоки С5 – С9). Основные теоретические работы, посвященные решению этой задачи. Долгое время в литературе не удавалось найти сведений о практическом применении результатов этих работ. В основном это связало со следующими причинами:
§ высокая трудоемкость реализации («адаптивное кодирование», «универсальное кодирование» блоки С8,9,);
§ недостаточная эффективность простых в реализации методов (например, «итерации простых подстановок», «разностное кодирование» блоки С5,6);
§ узкие классы источников, на которые ориентированы методы, например, «матричное кодирование» (блок – С7) используется в случае монотонности дискретных данных.
В настоящее время, в связи с развитием флэш – технологий, методы универсального кодирования, трудоемкость которых раньше казалась немыслимой стали вполне реализуемы на практике.
Отметим, что каждый блок классификации это именно метод СД, а не способ (или алгоритм). Под способом (или алгоритмом) СД, как правило, понимается комбинация нескольких методов, например архиваторы.
Для удобства восприятия, в табл. 2 сведены методы сжатия данных с указанием блоков в классификации и номеров областей применения в перечне раздела 1.
1. Космические исследования.
2. Физические эксперименты.
3. Вычислительная техника.
4. Средства связи.
5. Телеметрические системы.
6. Интернет.
7. Метеорология.
8. Библиотеки.
9. Архивы.
10. Системы видеонаблюдения.
11. Телевидение.
| Метод сжатия | Блок | № обл. |
| Повышение уровня обработки | А4 | 1 - 11 |
| Предварительная отбраковка событий | А5 | 1,2,3,5 |
| Спектральный анализ | А6 | 2,4,5 |
| Передача гистограмм, квантилей | А7 | 1,2,5,7 |
| Измерение вероятностей | А8 | 1,2,5 |
| Оптимальное кодирование (коды Шеннона, Фано, Хафмана) | В5 | 3,6,8,9 |
| Кодирование длин серий | В6 | 1,2,4,5,10,11 |
| Адресно – позиционное кодирование | В7 | 1,2,4,5,10,11 |
| Кодирование с предсказанием | В8 | 4,5,7 |
| Итерации простых подстановок | С5 | 3,4,9 |
| Разностное кодирование | С6 | 4,5 |
| Матричное кодирование | С7 | |
| Адаптивное кодирование | С8 | 1-6 |
| Универсальное кодирование | С9 | 1-9 |
| Преобразование в ряд Карунена, Лоева | D6 | 4,5 |
| Оптимальное предсказание | D7 | 1,2,5 |
| Дискретизация по Котельникову | D8 | 1,2,4,5 |
| Апертурные алгоритмы | Е6 | 1,2,4,5 |
| Преобразование в ряд Фурье | Е7 | 1.2.4.5.7 |
| Разностные методы | Е8 | 2-5 |
| Адаптивное квантование | Е9 | 2.4.5 |
| Переменная частота опроса | Е10 | 1,2,5 |
| Накопление статистики | F6 | 2,3,6,7 |
| Системы РКИМ с перестройкой параметров фильтров предсказателя и порогов квантования | F7 | 1,4,5 |
| Вероятностные интерактивные процедуры | F10 | 3-6 |
| Анализ и синтез речи | G6 | 1,3,4,6,11 |
| СД при передаче изображений и фильмов | G7 | 1,5,6,7 |
| СД при передаче ТВ - сигнала | G9 | 10,11 |
И в заключение
Постоянный рост объемов предаваемой и хранимой информации
приводит к перегрузкам средств хранения и каналов передачи
данных, что обусловливает необходимость применения сжатия
данных. Методов сжатия много. Они отличаются по ряду признаков.
В данной лекции мы рассмотрели подходы к систематизации и
упорядоченью этих признаков. С этой целью в лекции
представлены следующие материалы:
§ Обобщенная структурная схема информационной системы.
§ Конкретных примеры применения методов СД.
§ Подробная классификация методов СД.
§ Таблица соответствия областей применения и методов СД.
Использование результатов лекции поможет облегчить
ориентирование в широкой области науки и техники под названием
«сжатие данных».








