 2015-01-30
2015-01-30 205755
205755Учебное заведение: Федеральная служба государственной статистики (Росстат). Тип материала: Учебное пособие
Наиболее совершенной характеристикой вариации является среднее квадратическое откложение, которое называют стандартом (или стандартным отклонение). Среднее квадратическое отклонение (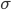 ) равно квадратному корню из среднего квадрата отклонений отдельных значений признака от средней арифметической:
) равно квадратному корню из среднего квадрата отклонений отдельных значений признака от средней арифметической:
Среднее квадратическое отклонение простое:
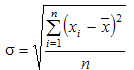
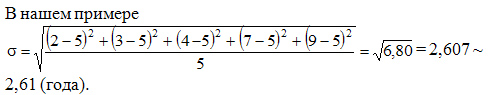
Среднее квадратическое отклонение взвешенное применяется для сгруппированных данных:
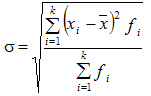
Между средним квадратическим и средним линейным отклонениями в условиях нормального распределения имеет место следующее соотношение: ~ 1,25.
Среднее квадратическое отклонение, являясь основной абсолютной мерой вариации, используется при определении значений ординат кривой нормального распределения, в расчетах, связанных с организацией выборочного наблюдения и установлением точности выборочных характеристик, а также при оценке границ вариации признака в однородной совокупности.
Дисперсия, ее виды, среднеквадратическое отклонение.
Дисперсия случайной величины — мера разброса данной случайной величины, т. е. её отклонения отматематического ожидания. В статистике часто употребляется обозначение 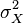 или
или 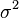 . Квадратный корень из дисперсии
. Квадратный корень из дисперсии 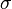 называется среднеквадратичным отклонением, стандартным отклонением или стандартным разбросом.
называется среднеквадратичным отклонением, стандартным отклонением или стандартным разбросом.
Общая дисперсия (σ2) измеряет вариацию признака во всей совокупности под влиянием всех факторов, обусловивших эту вариацию. Вместе с тем, благодаря методу группировок можно выделить и измерить вариацию, обусловленную группировочным признаком, и вариацию, возникающую под влиянием неучтенных факторов.
Межгрупповая дисперсия (σ2м.гр) характеризует систематическую вариацию, т. е. различия в величине изучаемого признака, возникающие под влиянием признака – фактора, положенного в основание группировки.
Среднеквадратическое отклонение (синонимы: среднее квадратическое отклонение, среднеквадратичное отклонение, квадратичное отклонение; близкие термины: стандартное отклонение, стандартный разброс) — в теории вероятностей и статистике наиболее распространённый показатель рассеивания значений случайной величиныотносительно её математического ожидания. При ограниченных массивах выборок значений вместо математического ожидания используется среднее арифметическоесовокупности выборок.
Среднеквадратическое отклонение измеряется в единицах измерения самой случайной величины и используется при расчёте стандартной ошибки среднего арифметического, при построении доверительных интервалов, при статистической проверке гипотез, при измерении линейной взаимосвязи между случайными величинами. Определяется какквадратный корень из дисперсии случайной величины.
Среднеквадратическое отклонение:
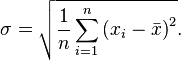
Стандартное отклонение (оценка среднеквадратического отклонения случайной величины x относительно её математического ожидания на основе несмещённой оценки её дисперсии):
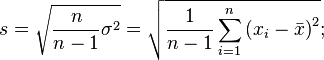
где 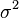 — дисперсия;
— дисперсия; 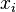 — i -й элемент выборки;
— i -й элемент выборки; 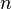 — объём выборки;
— объём выборки; 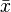 — среднее арифметическое выборки:
— среднее арифметическое выборки:
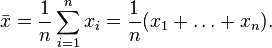
Следует отметить, что обе оценки являются смещёнными. В общем случае несмещённую оценку построить невозможно. Однако оценка на основе оценки несмещённой дисперсии является состоятельной.
Сущность, область применения и порядок определения моды и медианы.
Кроме степенных средних в статистике для относительной характеристики величины варьирующего признака и внутреннего строения рядов распределения пользуются структурными средними, которые представлены,в основном, модой и медианой.
Мода — это наиболее часто встречающийся вариант ряда. Мода применяется, например, при определении размера одежды, обуви, пользующейся наибольшим спросом у покупателей. Модой для дискретного ряда является варианта, обладающая наибольшей частотой. При вычислении моды для интервального вариационного ряда необходимо сначала определить модальный интервал (по максимальной частоте), а затем — значение модальной величины признака по формуле:
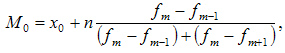
где:
- 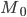 — значение моды
— значение моды
- 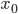 — нижняя граница модального интервала
— нижняя граница модального интервала
- 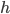 — величина интервала
— величина интервала
- 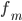 — частота модального интервала
— частота модального интервала
- 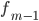 — частота интервала, предшествующего модальному
— частота интервала, предшествующего модальному
- 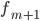 — частота интервала, следующего за модальным
— частота интервала, следующего за модальным
Медиана — это значение признака, которое лежит в основе ранжированного ряда и делит этот ряд на две равные по численности части.
Для определения медианы в дискретном ряду при наличии частот сначала вычисляют полусумму частот 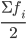 , а затем определяют, какое значение варианта приходится на нее. (Если отсортированный ряд содержит нечетное число признаков, то номер медианы вычисляют по формуле:
, а затем определяют, какое значение варианта приходится на нее. (Если отсортированный ряд содержит нечетное число признаков, то номер медианы вычисляют по формуле:
Ме = (n(число признаков в совокупности) + 1)/2,
в случае четного числа признаков медиана будет равна средней из двух признаков находящихся в середине ряда).
При вычислении медианы для интервального вариационного ряда сначала определяют медианный интервал, в пределах которого находится медиана, а затем — значение медианы по формуле:
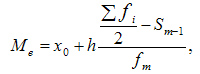
где:
- 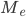 — искомая медиана
— искомая медиана
- — нижняя граница интервала, который содержит медиану
- — величина интервала
-  — сумма частот или число членов ряда
— сумма частот или число членов ряда
- 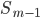 - сумма накопленных частот интервалов, предшествующих медианному
- сумма накопленных частот интервалов, предшествующих медианному
- — частота медианного интервала
Пример. Найти моду и медиану.
| Возрастные группы | Число студентов | Сумма накопленных частот ΣS |
| До 20 лет | ||
| 20 — 25 | ||
| 25 — 30 | ||
| 30 — 35 | ||
| 35 — 40 | ||
| 40 — 45 | ||
| 45 лет и более | ||
| Итого |
Решение:
В данном примере модальный интервал находится в пределах возрастной группы 25-30 лет, так как на этот интервал приходится наибольшая частота (1054).
Рассчитаем величину моды:
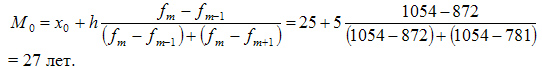
Это значит что модальный возраст студентов равен 27 годам.
Вычислим медиану. Медианный интервал находится в возрастной группе 25-30 лет, так как в пределах этого интервала расположена варианта, которая делит совокупность на две равные части (Σfi/2 = 3462/2 = 1731). Далее подставляем в формулу необходимые числовые данные и получаем значение медианы:
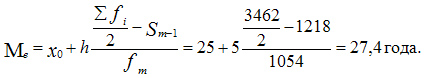
Это значит что одна половина студентов имеет возраст до 27,4 года, а другая свыше 27,4 года.
Кроме моды и медианы могут быть использованы такие показатели, как квартили, делящие ранжированный ряд на 4 равные части, децили - 10 частей и перцентили — на 100 частей.
Понятие выборочного наблюдения и область его применения.
Выборочное наблюдение применяется, когда применение сплошного наблюдения физически невозможно из-за большого массива данных или экономически нецелесообразно. Физическая невозможность имеет место, например, при изучении пассажиропотоков, рыночных цен, семейных бюджетов. Экономическая нецелесообразность имеет место при оценке качества товаров, связанной с их уничтожением, например, дегустация, испытание кирпичей на прочность и т.п.
Статистические единицы, отобранные для наблюдения, составляют выборочную совокупность или выборку, а весь их массив - генеральную совокупность (ГС). При этом числоединиц ввыборке обозначают n, а во всей ГС - N. Отношение n/N называется относительныйразмер или долявыборки.
Качество результатов выборочного наблюдения зависит от репрезентативности выборки, то есть от того, насколько она представительна в ГС. Для обеспечения репрезентативности выборки необходимо соблюдать принцип случайности отбора единиц, который предполагает, что на включение единицы ГС в выборку не может повлиять какой-либо иной фактор кроме случая.
Существует 4 способа случайного отбора в выборку:
- Собственно случайный отбор или «метод лото», когда статистическим величинам присваиваются порядковые номера, заносимые на определенные предметы (например, бочонки), которые затем перемешиваются в некоторой емкости (например, в мешке) и выбираются наугад. На практике этот способ осуществляют с помощью генератора случайных чисел или математических таблиц случайных чисел.
- Механический отбор, согласно которому отбирается каждая (N/n)-я величина генеральной совокупности. Например, если она содержит 100 000 величин, а требуется выбрать 1 000, то в выборку попадет каждая 100 000 / 1000 = 100-я величина. Причем, если они не ранжированы, то первая выбирается наугад из первой сотни, а номера других будут на сотню больше. Например, если первой оказалась единица № 19, то следующей должна быть № 119, затем № 219, затем № 319 и т.д. Если единицы генеральной совокупности ранжированы, то первой выбирается № 50, затем № 150, затем № 250 и так далее.
- Отбор величин из неоднородного массива данных ведется стратифицированным (расслоенным) способом, когда генеральная совокупность предварительно разбивается на однородные группы, к которым применяется случайный или механический отбор.
- Особый способ составления выборки представляет собой серийный отбор, при котором случайно или механически выбирают не отдельные величины, а их серии (последовательности с какого-то номера по какой-то подряд), внутри которых ведут сплошное наблюдение.
Качество выборочных наблюдений зависит и от типа выборки: повторная или бесповторная.
При повторном отборе попавшие в выборку статистические величины или их серии после использования возвращаются в генеральную совокупность, имея шанс попасть в новую выборку. При этом у всех величин генеральной совокупности одинаковая вероятность включения в выборку.
Бесповторный отбор означает, что попавшие в выборку статистические величины или их серии после использования не возвращаются в генеральную совокупность, а потому для остальных величин последней повышается вероятность попадания в следующую выборку.
Бесповторный отбор дает более точные результаты, поэтому применяется чаще. Но есть ситуации, когда его применить нельзя (изучение пассажиропотоков, потребительского спроса и т.п.) и тогда ведется повторный отбор.
Предельная ошибка выборки наблюдения, средняя ошибка выборки, порядок их расчета.
Рассмотрим подробно перечисленные выше способы формирования выборочной совокупности и возникающие при этом ошибки репрезентативности.
Собственно-случайная выборка основывается на отборе единиц из генеральной совокупности наугад без каких-либо элементов системности. Технически собственно-случайный отбор проводят методом жеребьевки (например, розыгрыши лотерей) или по таблице случайных чисел.
Собственно-случайный отбор «в чистом виде» в практике выборочного наблюдения применяется редко, но он является исходным среди других видов отбора, в нем реализуются основные принципы выборочного наблюдения. Рассмотрим некоторые вопросы теории выборочного метода и формулы ошибок для простой случайной выборки.
Ошибка выборочного наблюдения – это разность между величиной параметра в генеральной совокупности, и его величиной, вычисленной по результатам выборочного наблюдения. Для средней количественного признака ошибка выборки определяется
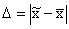
Показатель  называется предельной ошибкой выборки.
называется предельной ошибкой выборки.
Выборочная средняя 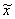 является случайной величиной, которая может принимать различные значения в зависимости от того, какие единицы попали в выборку. Следовательно, ошибки выборки также являются случайными величинами и могут принимать различные значения. Поэтому определяют среднюю из возможных ошибок – среднюю ошибку выборки
является случайной величиной, которая может принимать различные значения в зависимости от того, какие единицы попали в выборку. Следовательно, ошибки выборки также являются случайными величинами и могут принимать различные значения. Поэтому определяют среднюю из возможных ошибок – среднюю ошибку выборки 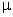 , которая зависит от:
, которая зависит от:
- объема выборки: чем больше численность, тем меньше величина средней ошибки;
- степени изменения изучаемого признака: чем меньше вариация признака, а, следовательно, и дисперсия, тем меньше средняя ошибка выборки.
При случайном повторном отборе средняя ошибка рассчитывается:
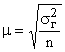 .
.
Практически генеральная дисперсия точно не известна, но в теории вероятности  доказано, что
доказано, что
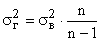 .
.
Так как величина 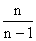 при достаточно больших n близка к 1, можно считать, что
при достаточно больших n близка к 1, можно считать, что 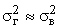 . Тогда средняя ошибка выборки может быть рассчитана:
. Тогда средняя ошибка выборки может быть рассчитана:
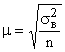 .
.
Но в случаях малой выборки (при n<30) коэффициент необходимо учитывать, и среднюю ошибку малой выборки рассчитывать по формуле
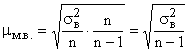 .
.
При случайной бесповторной выборке приведенные формулы корректируются на величину 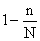 . Тогда средняя ошибка бесповторной выборки:
. Тогда средняя ошибка бесповторной выборки:
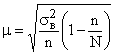 и
и 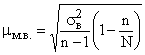 .
.
Т.к. 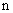 всегда меньше
всегда меньше 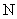 , то множитель (
, то множитель (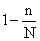 ) всегда меньше 1. Это значит, что средняя ошибка при бесповторном отборе всегда меньше, чем при повторном.
) всегда меньше 1. Это значит, что средняя ошибка при бесповторном отборе всегда меньше, чем при повторном.
Механическая выборка применяется, когда генеральная совокупность каким-либо способом упорядочена (например, списки избирателей по алфавиту, телефонные номера, номера домов, квартир). Отбор единиц осуществляется через определенный интервал, который равен обратному значению процента выборки. Так при 2% выборке отбирается каждая 50 единица =1/0,02, при 5% каждая 1/0,05=20 единица генеральной совокупности.
Начало отсчета выбирается разными способами: случайным образом, из середины интервала, со сменой начала отсчета. Главное при этом – избежать систематической ошибки. Например, при 5% выборке, если первой единицей выбрана 13-я, то следующие 33, 53, 73 и т.д.
По точности механический отбор близок к собственно-случайной выборке. Поэтому для определения средней ошибки механической выборки используют формулы собственно-случайного отбора.
При типическом отборе обследуемая совокупность предварительно разбивается на однородные, однотипные группы. Например, при обследовании предприятий это могут быть отрасли, подотрасли, при изучении населения – районы, социальные или возрастные группы. Затем осуществляется независимый выбор из каждой группы механическим или собственно-случайным способом.
Типическая выборка дает более точные результаты по сравнению с другими способами. Типизация генеральной совокупности обеспечивает представительство в выборке каждой типологической группы, что позволяет исключить влияние межгрупповой дисперсии на среднюю ошибку выборки. Следовательно, при нахождении ошибки типической выборки согласно правилу сложения дисперсий (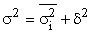 ) необходимо учесть лишь среднюю из групповых дисперсий. Тогда средняя ошибка выборки:
) необходимо учесть лишь среднюю из групповых дисперсий. Тогда средняя ошибка выборки:
при повторном отборе
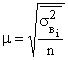 ,
,
при бесповторном отборе
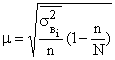 ,
,
где  – средняя из внутригрупповых дисперсий в выборке.
– средняя из внутригрупповых дисперсий в выборке.
Серийный (или гнездовой) отбор применяется в случае, когда генеральная совокупность разбита на серии или группы до начала выборочного обследования. Этими сериями могут быть упаковки готовой продукции, студенческие группы, бригады. Серии для обследования выбираются механическим или собственно-случайным способом, а внутри серии производится сплошное обследование единиц. Поэтому средняя ошибка выборки зависит только от межгрупповой (межсерийной) дисперсии, которая вычисляется по формуле:
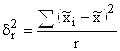
где r – число отобранных серий;
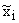 – средняя і-той серии.
– средняя і-той серии.
Средняя ошибка серийной выборки рассчитывается:
при повторном отборе:
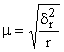 ,
,
при бесповторном отборе:
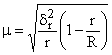 ,
,
где R – общее число серий.
Комбинированный отбор представляет собой сочетание рассмотренных способов отбора.
Средняя ошибка выборки при любом способе отбора зависит главным образом от абсолютной численности выборки и в меньшей степени – от процента выборки. Предположим, что проводится 225 наблюдений в первом случае из генеральной совокупности в 4500 единиц и во втором – в 225000 единиц. Дисперсии в обоих случаях равны 25. Тогда в первом случае при 5 %-ном отборе ошибка выборки составит:
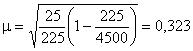
Во втором случае при 0,1 %-ном отборе она будет равна:
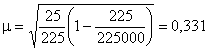
Таким образом, при уменьшении процента выборки в 50 раз, ошибка выборки увеличилась незначительно, так как численность выборки не изменилась.
Предположим, что численность выборки увеличили до 625 наблюдений. В этом случае ошибка выборки равна:
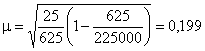
Увеличение выборки в 2,8 раза при одной и той же численности генеральной совокупности снижает размеры ошибки выборки более чем в 1,6 раза.
Методы и способы формирования выборочной совокупности.
В статистике применяются различные способы формирования выборочных совокупностей, что обусловливается задачами исследования и зависит от специфики объекта изучения.
Основным условием проведения выборочного обследования является предупреждение возникновения систематических ошибок, возникающих вследствие нарушения принципа равных возможностей попадания в выборку каждой единицы генеральной совокупности. Предупреждение систематических ошибок достигается в результате применения научно обоснованных способов формирования выборочной совокупности.
Существуют следующие способы отбора единиц из генеральной совокупности:
1) индивидуальный отбор — в выборку отбираются отдельные единицы;
2) групповой отбор — в выборку попадают качественно однородные группы или серии изучаемых единиц;
3) комбинированный отбор — это комбинация индивидуального и группового отбора.
Способы отбора определяются правилами формирования выборочной совокупности.
Выборка может быть:
- собственно-случайная состоит в том, что выборочная совокупность образуется в результате случайного (непреднамеренного) отбора отдельных единиц из генеральной совокупности. При этом количество отобранных в выборочную совокупность единиц обычно определяется исходя из принятой доли выборки. Доля выборки есть отношение числа единиц выборочной совокупности n к численности единиц генеральной совокупности N, т.е.
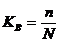
- механическая состоит в том, что отбор единиц в выборочную совокупность производится из генеральной совокупности, разбитой на равные интервалы (группы). При этом размер интервала в генеральной совокупности равен обратной величине доли выборки. Так, при 2%-ной выборке отбирается каждая 50-я единица (1:0,02), при 5%-ной выборке — каждая 20-я единица (1:0,05) и т.д. Таким образом, в соответствии с принятой долей отбора, генеральная совокупность как бы механически разбивается на равновеликие группы. Из каждой группы в выборку отбирается лишь одна единица.
- типическая – при которойгенеральная совокупность вначале расчленяется на однородные типические группы. Затем из каждой типической группы собственно-случайной или механической выборкой производится индивидуальный отбор единиц в выборочную совокупность. Важной особенностью типической выборки является то, что она дает более точные результаты по сравнению с другими способами отбора единиц в выборочную совокупность;
- серийная – при которой генеральную совокупность делят на одинаковые по объему группы - серии. В выборочную совокупность отбираются серии. Внутри серий производится сплошное наблюдение единиц, попавших в серию;
- комбинированная – выборка может быть двухступенчатой. При этом генеральная совокупность сначала разбивается на группы. Затем производят отбор групп, а внутри последних осуществляется отбор отдельных единиц.
В статистике различают следующие способы отбора единиц в выборочную совокупность:
- одноступенчатая выборка - каждая отобранная единица сразу же подвергается изучению по заданному признаку (собственно-случайная и серийная выборки);
- многоступенчатая выборка - производят подбор из генеральной совокупности отдельных групп, а из групп выбираются отдельные единицы (типическая выборка с механическим способом отбора единиц в выборочную совокупность).
Кроме того различают:
- повторный отбор – по схеме возвращенного шара. При этом каждая попавшая в выборку единица иди серия возвращается в генеральную совокупность и поэтому имеет шанс снова попасть в выборку;
- бесповторный отбор – по схеме невозвращенного шара. Он имеет более точные результаты при одном и том же объеме выборки.
Определение необходимого объема выборки (использование таблицы Стьюдента).
Одним из научных принципов в теории выборочного метода является обеспечение достаточного числа отобранных единиц. Теоретически необходимость соблюдения этого принципа представлена в доказательствах предельных теорем теории вероятностей, которые позволяют установить, какой объем единиц следует выбрать из генеральной совокупности, чтобы он был достаточным и обеспечивал репрезентативность выборки.
Уменьшение стандартной ошибки выборки, а следовательно, увеличение точности оценки всегда связано с увеличением объема выборки, поэтому уже на стадии организации выборочного наблюдения приходится решать вопрос о том, каков должен быть объем выборочной совокупности, чтобы была обеспечена требуемая точность результатов наблюдений. Расчет необходимого объема выборки строится с помощью формул, выведенных из формул предельных ошибок выборки (А), соответствующих тому или иному виду и способу отбора. Так, для случайного повторного объема выборки (n) имеем:
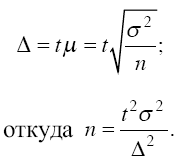
Суть этой формулы – в том, что при случайном повторном отборе необходимой численности объем выборки прямо пропорционален квадрату коэффициента доверия (t2) и дисперсии вариационного признака (?2) и обратно пропорционален квадрату предельной ошибки выборки (?2). В частности, с увеличением предельной ошибки в два раза необходимая численность выборки может быть уменьшена в четыре раза. Из трех параметров два (t и?) задаются исследователем.
При этом исследователь исходя из целии задач выборочного обследования должен решить вопрос: в каком количественном сочетании лучше включить эти параметры для обеспечения оптимального варианта? В одном случае его может больше устраивать надежность полученных результатов (t), нежели мера точности (?), в другом – наоборот. Сложнее решить вопрос в отношении величины предельной ошибки выборки, так как этим показателем исследователь на стадии проектировки выборочного наблюдения не располагает, поэтому в практике принято задавать величину предельной ошибки выборки, как правило, в пределах до 10 % предполагаемого среднего уровня признака. К установлению предполагаемого среднего уровня можно подходить по разному: использовать данные подобных ранее проведенных обследований или же воспользоваться данными основы выборки и произвести небольшую пробную выборку.
Наиболее сложно установить при проектировании выборочного наблюдения третий параметр в формуле (5.2) – дисперсию выборочной совокупности. В этом случае необходимо использовать всю информацию, имеющуюся в распоряжении исследователя, полученную в ранее проведенных подобных и пробных обследованиях.
Вопрос об определении необходимой численности выборки усложняется, если выборочное обследование предполагает изучение нескольких признаков единиц отбора. В этом случае средние уровни каждого из признаков и их вариация, как правило, различны, и поэтому решить вопрос о том, дисперсии какого из признаков отдать предпочтение, возможно лишь с учетом цели и задач обследования.
При проектировании выборочного наблюдения предполагаются заранее заданная величина допустимой ошибки выборки в соответствии с задачами конкретного исследования и вероятность выводов по результатам наблюдения.
В целом формула предельной ошибки выборочной средней величины позволяет определять:
- величину возможных отклонений показателей генеральной совокупности от показателей выборочной совокупности;
- необходимую численность выборки, обеспечивающую требуемую точность, при которой пределы возможной ошибки не превысят некоторой заданной величины;
- вероятность того, что в проведенной выборке ошибка будет иметь заданный предел.
Распределение Стьюдента в теории вероятностей — это однопараметрическое семейство абсолютно непрерывных распределений.
Ряды динамики (интервальные, моментные), смыкание рядов динамики.
Ряды динамики - это значения статистических показателей, которые представлены в определенной хронологической последовательности.
Каждый динамический ряд содержит две составляющие:
1) показатели периодов времени (годы, кварталы, месяцы, дни или даты);
2) показатели, характеризующие исследуемый объект за временные периоды или на соответствующие даты, которые называют уровнями ряда.
Уровни ряда выражаются как абсолютными, так и средними или относительными величинами. В зависимости от характера показателей строят динамические ряды абсолютных, относительных и средних величин. Ряды динамики из относительных и средних величин строят на основе производных рядов абсолютных величин. Различают интервальные и моментные ряды динамики.
Динамический интервальный ряд содержит значения показателей за определенные периоды времени. В интервальном ряду уровни можно суммировать, получая объем явления за более длительный период, или так называемые накопленные итоги.
Динамический моментный ряд отражает значения показателей на определенный момент времени (дату времени). В моментных рядах исследователя может интересовать только разность явлений, отражающая изменение уровня ряда между определенными датами, поскольку сумма уровней здесь не имеет реального содержания. Накопленные итоги здесь не рассчитываются.
Важнейшим условием правильного построения динамических рядов является сопоставимость уровней рядов, относящихся к различным периодам. Уровни должны быть представлены в однородных величинах, должна иметь место одинаковая полнота охвата различных частей явления.
Для того, чтобы избежать искажения реальной динамики, в статистическом исследовании проводятся предварительные расчеты (смыкание рядов динамики), которые предшествуют статистическому анализу динамических рядов. Под смыканием рядов динамики понимается объединение в один ряд двух и более рядов, уровни которых рассчитаны по разной методологии или не соответствуют территориальным границам и т.д. Смыкание рядов динамики может предполагать также приведение абсолютных уровней рядов динамики к общему основанию, что нивелирует несопоставимость уровней рядов динамики.
Понятие сопоставимости рядов динамики, коэффициенты, темпы роста и прироста.
Ряды динамики — это ряды статистических показателей, характеризующих развитие явлений природы и общества во времени. Публикуемые Госкомстатом России статистические сборники содержат большое количество рядов динамики в табличной форме. Ряды динамики позволяют выявить закономерности развития изучаемых явлений.
Ряды динамики содержат два вида показателей. Показатели времени (годы, кварталы, месяцы и др.) или моменты времени (на начало года, на начало каждого месяца и т.п.). Показатели уровней ряда. Показатели уровней рядов динамики могут быть выражены абсолютными величинами (производство продукта в тоннах или рублях), относительными величинами (удельный вес городского населения в %) и средними величинами (средняя заработная плата работников отрасли по годам и т. п.). В табличной форме ряд динамики содержит два столбца или две строки.
Правильное построение рядов динамики предполагает выполнение ряда требований:
- все показатели ряда динамики должны быть научно обоснованными, достоверными;
- показатели ряда динамики должны быть сопоставимы по времени, т.е. должны быть исчислены за одинаковые периоды времени или на одинаковые даты;
- показатели ряда динамики должны быть сопоставимы по территории;
- показатели ряда динамики должны быть сопоставимы по содержанию, т.е. исчислены по единой методологии, одинаковым способом;
- показатели ряда динамики должны быть сопоставимы по кругу учитываемых хозяйств. Все показатели ряда динамики должны быть приведены в одних и тех же единицах измерения.
Статистические показатели могут характеризовать либо результаты изучаемого процесса за период времени, либо состояние изучаемого явления на определенный момент времени, т.е. показатели могут быть интервальными (периодическими) и моментными. Соответственно первоначально ряды динамики могут быть либо интервальными, либо моментными. Моментные ряды динамики в свою очередь могут быть с равными и неравными промежутками времени.
Первоначальные ряды динамики могут быть преобразованы в ряд средних величин и ряд относительных величин (цепной и базисный). Такие ряды динамики называют производными рядами динамики.
Методика расчета среднего уровня в рядах динамики различна, обусловлена видом ряда динамики. На примерах рассмотрим виды рядов динамики и формулы для расчета среднего уровня.
Абсолютные приросты (Δy) показывают, на сколько единиц изменился последующий уровень ряда по сравнению с предыдущим (гр.3. — цепные абсолютные приросты) или по сравнению с начальным уровнем (гр.4. — базисные абсолютные приросты). Формулы расчета можно записать следующим образом:

При уменьшении абсолютных значений ряда будет соответственно "уменьшение", "снижение".
Показатели абсолютного прироста свидетельствуют о том, что, например, в 1998 г. производство продукта "А" увеличилось по сравнению с 1997 г. на 4 тыс. т, а по сравнению с 1994 г. — на 34 тыс. т.; по остальным годам см. табл. 11.5 гр. 3 и 4.
Коэффициент роста показывает, во сколько раз изменился уровень ряда по сравнению с предыдущим (гр.5 — цепные коэффициенты роста или снижения) или по сравнению с начальным уровнем (гр.6 — базисные коэффициенты роста или снижения). Формулы расчета можно записать следующим образом:
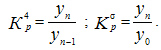
Темпы роста показывают, сколько процентов составляет последующий уровень ряда по сравнению с предыдущим (гр.7 — цепные темпы роста) или по сравнению с начальным уровнем (гр.8 — базисные темпы роста). Формулы расчета можно записать следующим образом:
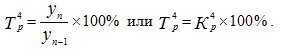
Так, например, в 1997 г. объем производства продукта "А" по сравнению с 1996 г. составил 105,5 % (
Темпы прироста показывают, на сколько процентов увеличился уровень отчетного периода по сравнению с предыдущим (гр.9- цепные темпы прироста) или по сравнению с начальным уровнем (гр.10- базисные темпы прироста). Формулы расчета можно записать следующим образом:
Тпр = Тр - 100% или Тпр= абсолютный прирост / уровень предшествующего периода * 100%
Так, например, в 1996 г. по сравнению с 1995 г. продукта "А" произведено больше на 3,8 % (103,8 %- 100%) или (8:210)х100%, а по сравнению с 1994 г. — на 9% (109% — 100%).
Если абсолютные уровни в ряду уменьшаются, то темп будет меньше 100% и соответственно будет темп снижения (темп прироста со знаком минус).
Абсолютное значение 1% прироста (гр. 11) показывает, сколько единиц надо произвести в данном периоде, чтобы уровень предыдущего периода возрос на 1 %. В нашем примере, в 1995 г. надо было произвести 2,0 тыс. т., а в 1998 г. — 2,3 тыс. т., т.е. значительно больше.
Определить величину абсолютного значения 1% прироста можно двумя способами:
- уровень предшествующего периода разделить на 100;
- цепные абсолютные приросты разделить на соответствующие цепные темпы прироста.
Абсолютное значение 1% прироста = 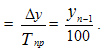
В динамике, особенно за длительный период, важен совместный анализ темпов прироста с содержанием каждого процента прироста или снижения.
Заметим, что рассмотренная методика анализа рядов динамики применима как для рядов динамики, уровни которых выражены абсолютными величинами (т, тыс. руб., число работников и т.д.), так и для рядов динамики, уровни которых выражены относительными показателями (% брака, % зольности угля и др.) или средними величинами (средняя урожайность в ц/га, средняя заработная плата и т.п.).
Наряду с рассмотренными аналитическими показателями, исчисляемыми за каждый год в сравнении с предшествующим или начальным уровнем, при анализе рядов динамики необходимо исчислить средние за период аналитические показатели: средний уровень ряда, средний годовой абсолютный прирост (уменьшение) и средний годовой темп роста и темп прироста.
Методы расчета среднего уровня ряда динамики были рассмотрены выше. В рассматриваемом нами интервальном ряду динамики средний уровень ряда исчисляется по формуле средней арифметической простой:
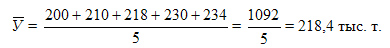
Среднегодовой объем производства продукта за 1994- 1998 гг. составил 218,4 тыс. т.
Среднегодовой абсолютный прирост исчисляется также по формуле средней арифметической простой:
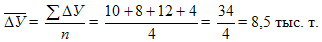
Ежегодные абсолютные приросты изменялись по годам от 4 до 12 тыс.т (см.гр.3), а среднегодовой прирост производства за период 1995 — 1998 гг. составил 8,5 тыс. т.
Методы расчета среднего темпа роста и среднего темпа прироста требуют более подробного рассмотрения. Рассмотрим их на примере приведенных в таблице годовых показателей уровня ряда.
Средний уровень ряда динамики.
Ряд динамики (или временной ряд) – это числовые значения определенного статистического показателя в последовательные моменты или периоды времени (т.е. расположенные в хронологическом порядке).
Числовые значения того или иного статистического показателя, составляющего ряд динамики, называют уровнями ряда и обычно обозначают буквой y. Первый член ряда y1 называют начальным или базисным уровнем, а последний yn – конечным. Моменты или периоды времени, к которым относятся уровни, обозначают через t.
Ряды динамики, как правило, представляют в виде таблицы или графика, причем по оси абсцисс строится шкала времени t, а по оси ординат – шкала уровней ряда y.
Средние показатели ряда динамики
Каждый ряд динамики можно рассматривать как некую совокупность n меняющихся во времени показателей, которые можно обобщать в виде средних величин. Такие обобщенные (средние) показатели особенно необходимы при сравнении изменений того или иного показателя в разные периоды, в разных странах и т.д.
Обобщенной характеристикой ряда динамики может служить прежде всего средний уровень ряда. Способ расчета среднего уровня зависит от того, моментный ряд или интервальный (периодный).
В случае интервального ряда его средний уровень определяется по формуле простой средней арифметической величины из уровней ряда, т.е.
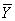 =
= 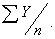
Если имеется моментный ряд, содержащий n уровней (y1, y2, …, yn) с равными промежутками между датами (моментами времени), то такой ряд легко преобразовать в ряд средних величин. При этом показатель (уровень) на начало каждого периода одновременно является показателем на конец предыдущего периода. Тогда средняя величина показателя для каждого периода (промежутка между датами) может быть рассчитана как полусумма значений у на начало и конец периода, т.е. как 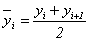 . Количество таких средних будет
. Количество таких средних будет 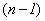 . Как указывалось ранее, для рядов средних величин средний уровень рассчитывается по средней арифметической.
. Как указывалось ранее, для рядов средних величин средний уровень рассчитывается по средней арифметической.
Следовательно, можно записать:
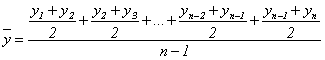 .
.
После преобразования числителя получаем:
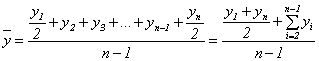 ,
,
где Y1 и Yn — первый и последний уровни ряда; Yi — промежуточные уровни.
Эта средняя 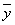 известна в статистике как средняя хронологическая для моментных рядов. Такое название она получила от слова «cronos» (время, лат.), так как рассчитывается из меняющихся во времени показателей.
известна в статистике как средняя хронологическая для моментных рядов. Такое название она получила от слова «cronos» (время, лат.), так как рассчитывается из меняющихся во времени показателей.
В случае неравных промежутков между датами среднюю хронологическую для моментного ряда можно рассчитать как среднюю арифметическую из средних значений уровней на каждую пару моментов, взвешенных по величине расстояний (отрезков времени) между датами, т.е.
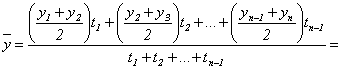
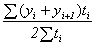 .
.
В данном случае предполагается, что в промежутках между датами уровни принмали разные значения, и мы из двух известных (yi и yi+1) определяем средние, из которых затем уже рассчитываем общую среднюю для всего анализируемого периода.
Если же предполагается, что каждое значение yi остается неизменным до следующего (i+ 1 )- го момента, т.е. известна точная дата изменения уровней, то расчет можно осуществлять по формуле средней арифметической взвешенной:
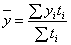 ,
,
где 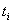 – время, в течение которого уровень
– время, в течение которого уровень 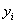 оставался неизменным.
оставался неизменным.
Кроме среднего уровня в рядах динамики рассчитываются и другие средние показатели – среднее изменение уровней ряда (базисным и цепным способами), средний темп изменения.
Базисное среднее абсолютное изменение представляет собой частное от деления последнего базисного абсолютного изменения на количество изменений. То есть
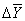 Б =
Б = 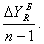
Цепное среднее абсолютное изменение уровней ряда представляет собой частное от деления суммы всех цепных абсолютных изменений на количество изменений, то есть
Ц = 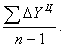
По знаку средних абсолютных изменений также судят о характере изменения явления в среднем: рост, спад или стабильность.
Из правила контроля базисных и цепных абсолютных изменений следует, что базисное и цепное среднее изменение должны быть равными.
Наряду со средними абсолютным изменением рассчитывается и среднее относительное тоже базисным и цепным способами.
Базисное среднее относительное изменение определяется по формуле:
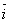 Б=
Б=  =
= 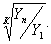
Цепное среднее относительное изменение определяется по формуле:
Ц= 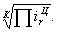
Естественно, базисное и цепное среднее относительное изменения должны быть одинаковыми и сравнением их с критериальным значением 1 делается вывод о характере изменения явления в среднем: рост, спад или стабильность.
Вычитанием 1 из базисного или цепного среднего относительного изменения образуется соответствующий среднийтемп изменения, по знаку которого также можно судить о характере изменения изучаемого явления, отраженного данным рядом динамики.
Сезонные колебания и индексы сезонности.
Сезонные колебания – устойчивые внутригодичные колебания.
Основной принцип хозяйствования для получения максимального эффекта – это максимизация доходов и минимизация затрат. Изучая сезонные колебания решается задача максимального уравнения в каждом уровне года.
При изучении сезонных колебаний решаются две взаимосвязанные задачи:
1. Выявление специфики развития явления во внутригодовой динамике;
2. Измерение сезонных колебаний с построением модели сезонной волны;
Для измерения сезонных колебаний обычно исчисляют индеек сезонности. В общем виде они определяются отношением исходных уравнений ряда динамики к теоретическим уравнениям, выступающим в качестве базы для сравнения.
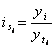 ;
;
Так как на сезонные колебания накладываются случайные отклонения, для их устранения производят усреднение индексов сезонности.
В этом случае для каждого периода годового цикла определяются обобщенные показатели в виде средних сезонных индексов:
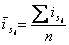 ;
;
Средние индексы сезонных колебаний свободны от влияние случайных отклонений основной тенденции развития.
В зависимости от характера тренда формула среднего индекса сезонности может принимать следующие виды:
1. Для рядов внутригодовой динамики с ярковыраженной основной тенденцией развития:
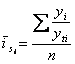 ;
;
2. Для рядов внутригодовой динамики в которой повышающийся или снижающийся тренд отсутствует, либо незначителен:
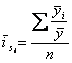 , где
, где 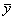 - общее среднее;
- общее среднее;
Методы анализа основной тенденции.
На развитие явлений по времени оказывают влияние факторы различные по характеру и силе воздействия. Некоторые из них носят случайный характер, другие оказывают практически постоянное воздействие и формируют в рядах динамики определенную тенденцию развития.
Важной задачей статистики является выявление в рядах динамики тренда, освобожденного от действия различных случайных факторов. С этой целью ряды динамики подвергаются обработке методами укрупнения интервалов, скользящей средней и аналитического выравнивания и др.
Метод укрупнения интервалов основан на укрупнении периодов времени, к которым относятся уровни ряда динамики, т.е. представляет из себя замену данных, имеющих отношение к мелким временным периодам, данными по более крупным периодам. Особенно эффективен, когда первоначальные уровни ряда относятся к коротким промежуткам времени. Например, ряды показателей, относящиеся к ежедневным событиям, заменяются рядами, относящимся к недельным, помесячным и т.д. Это позволит более отчетливо показать «ось развития явления». Средняя, исчисленная по укрупненным интервалам, позволяет выявлять направление и характер (ускорение или замедление роста) основной тенденции развития.
Метод скользящей средней схож с предыдущим, но в данном случаефактические уровнизаменяются средними уровнями, рассчитанными для последовательно подвижных (скользящих) укрупненных интервалов, охватывающих m уровней ряда.
Например, если принять m=3, то вначале рассчитывается средняя из первых трех уровней ряда, затем – из такого же числа уровней, но начиная со второго по счету, далее – начиная с третьего и т.д. Таким образом, средняя как бы «скользит» по ряду динамики, передвигаясь на один срок. Рассчитанные из m членов скользящие средние относятся к середине (центру) каждого интервала.
Этот метод устраняет лишь случайные колебания. Если же ряд имеет сезонную волну, то она сохранится и после сглаживания методом скользящей средней.
Аналитическое выравнивание. В целях устранения случайных колебаний и выявления тренда применяется выравнивание уровней ряда по аналитическим формулам (или аналитическое выравнивание). Его суть состоит в замене эмпирических (фактических) уровней 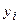 теоретическими
теоретическими 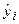 , которые рассчитаны по определенному уравнению, принятому за математическую модель тренда, где теоретические уровни рассматриваются как функция времени:
, которые рассчитаны по определенному уравнению, принятому за математическую модель тренда, где теоретические уровни рассматриваются как функция времени: 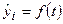 . При этом каждый фактический уровень рассматривается как сумма двух составляющих:
. При этом каждый фактический уровень рассматривается как сумма двух составляющих: 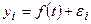 , где
, где 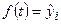 - систематическая составляющая и выраженная определенным уравнением, а
- систематическая составляющая и выраженная определенным уравнением, а 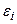 - случайная величина, вызывающая колебания вокруг тренда.
- случайная величина, вызывающая колебания вокруг тренда.
Задача аналитического выравнивания сводится к следующему:
1. Определение на основе фактических данных вида гипотетической функции , способной наиболее адекватно отразить тенденцию развития исследуемого показателя.
2. Нахождение по эмпирическим данным параметров указанной функции (уравнения)
3. Расчет по найденному уравнению теоретических (выровненных) уровней.
Выбор той или иной функции осуществляется, как правило, на основе графического изображения эмпирических данных.
В качестве моделей служат уравнения регрессии, параметры которых рассчитывают по способу наименьших квадратов
Ниже приводятся наиболее часто используемые для выравнивания динамических рядов уравнения регрессии с указанием для отражения каких именно тенденций развития они наиболее всего подходят.
| Вид уравнения | Отражаемая уравнением тенденция развития |
Уравнение прямой 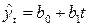 | Равномерный рост при b1>0 или равномерное падение при b1 < 0 |
Показательная функция 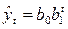 | Ускоряющийся рост при b1>1 или замедляющееся падение при b1 |
Гипербола 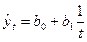 | Замедляющееся падение при b1 > 0 или замедляющийся рост при b1 < 0 |
Парабола 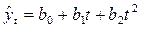 | Рост, переходящий в падение, или падение, переходящее в рост в точке t = 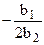 |
Для нахождения параметров приведенных выше уравнений существуют специальные алгоритмы и компьютерные программы. В частности для нахождения параметров уравнения прямой может быть использован такой алгоритм:
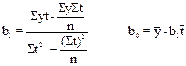
Если периоды или моменты времени пронумеровать так, чтобы получилось St =0, то вышеприведенные алгоритмы существенно упростятся и превратятся в
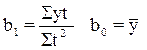
Выровненные уровни на графике расположатся на одной прямой, проходящей на самом близком расстоянии от фактических уровней данного динамического ряда. Сумма квадратов отклонений является отражением влияния случайных факторов.
С ее помощью рассчитаем среднюю (стандартную) ошибку уравнения:
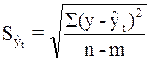
Здесь n - число наблюдений, а m - число параметров в уравнении (их у нас два – b1 и b0).
Основная тенденция (тренд) показывает, как воздействуют систематические факторы на уровни ряда динамики, а колеблемость уровней около тренда (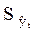 ) служит мерой воздействия остаточных факторов.
) служит мерой воздействия остаточных факторов.
Для оценки качества используемой модели динамического ряда применяется также критерий F Фишера. Он представляет из себя отношение двух дисперсий, а именно отношение дисперсии, вызванной регрессией, т.е. изучаемым фактором, к дисперсии, вызванной случайными причинами, т.е. остаточной дисперсией:
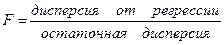
В развернутом виде формула этого критерия может быть представлена так:
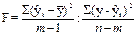
где n - число наблюдений, т.е. число уровней ряда,
m - число параметров в уравнении, y - фактический уровень ряда,
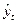 - выровненный уровень ряда,
- выровненный уровень ряда, 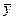 - средний уровень ряда.
- средний уровень ряда.
Более удачная, чем другие, модель не всегда может оказаться достаточно удовлетворительной. Ее можно признать таковой только в том случае, когда критерий F у нее перешагнет известную критическую границу. Эта граница устанавливается с помощью таблиц F-распределения.
Сущность и классификация индексов.
Под индексом в статистике понимают относительный показатель, характеризующий изменение величины какого-либо явления во времени, пространстве или по сравнению с любым эталоном.
Основным элементом индексного отношения является индексируемая величина. Под индексируемой величиной понимают значение признака статистической совокупности, изменение которого является объектом изучения.
С помощью индексов решаются три главные задачи:
1) оценка изменения сложного явления;
2) определение влияния отдельных факторов на изменение сложного явления;
3) сравнение величины какого-то явления с величиной прошлого периода, величиной по другой территории, а также с нормативами, планами,прогнозами.
Индексы классифицируют по 3-м признакам:
1) по содержанию индексируемых величин;
2) по степени охвата элементов совокупности;
3) по методам расчета общих индексов.
По содержанию индексируемых величин индексы разделяются на индексы количественных (объемных) показателей и индексы качественных показателей. Индексы количественных показателей -индексы физического объема промышленной продукции, физического объема продаж, численности и др. Индексы качественных показателей — индексы цен, себестоимости, производительности труда, средней заработной платы и др.
По степени охвата единиц совокупности индексы делятся на два класса: индивидуальные и общие. Для их характеристики введем следующие условные обозначения, принятые в практике применения индексного метода:
q - количество (объем) какого-либо продукта в натуральном выражении; р - цена единицы продукции; z - себестоимость единицы продукции; t — затраты времени на производство единицы продукции (трудоемкость); w — выработка продукции в стоимостном выражении в единицу времени; v - выработка продукции в натуральном выражении в единицу времени; Т — общие затраты времени или численность работников.
Для того чтобы различать, к какому периоду или объекту относятся индексируемые величины, принято справа внизу за соответствующим символом ставить подстрочные знаки. Так, например, в индексах динамики, как правило, для сравниваемых (текущих, отчетных) периодов используется подстрочный знак 1 и для периодов, с которыми производится сравнение,
Индивидуальные индексы служат для характеристики изменения отдельных элементов сложного явления (например -изменение объема выпуска продукции одного вида). Они представляют собой относительные величины динамики, выполнения обязательств, сравнения индексируемых величин.
Индивидуальный индекс физического объема продукции определяется
С аналитической точки зрения приведенные индивидуальные индексы динамики аналогичны коэффициентам (темпам) роста и характеризуют изменение индексируемой величины в текущем периоде по сравнению с базисным, т. е. показывают, во сколько раз она возросла (уменьшилась) или сколько процентов составляет ее рост (снижение). Значения индексов выражают в коэффициентах или процентах.
Общий (сводный) индекс отражает изменение всех элементов сложного явления.
Агрегатный индекс является основной формой индекса. Агрегатным он называется потому, что его числитель и знаменатель представляют собой набор «агрегат»
Средние индексы, их определение.
Помимо агрегатных индексов в статистике применяется другая их форма – средневзвешенные индексы. К их исчислению прибегают тогда, когда имеющаяся в распоряжении информация не позволяет рассчитать общий агрегатный индекс. Так, если отсутствуют данные о ценах, но имеется информация о стоимости продукции в текущем периоде и известны индивидуальные индексы цен по каждому товару, то общий индекс цен как агрегатный определить нельзя, однако возможно исчислить его как средний из индивидуальных. Точно так же, если не известны количества произведенных отдельных видов продукции, но известны индивидуальные индексы и стоимость продукции базисного периода, то можно определить общий индекс физического объема продукции как средневзвешенную величину.
Средний индекс – это индекс, вычисленный как средняя величина из индивидуальных индексов. Агрегатный индекс является основной формой общего индекса, поэтому средний индекс должен быть тождествен агрегатному индексу. При исчислении средних индексов используются две формы средних: арифметическая и гармоническая.
Средний арифметический индекс тождествен агрегатному индексу, если весами индивидуальных индексов будут слагаемые знаменателя агрегатного индекса. Только в этом случае величина индекса, рассчитанного по формуле средней арифметической, будет равна агрегатному индексу.

