2014-02-24
2014-02-24 773
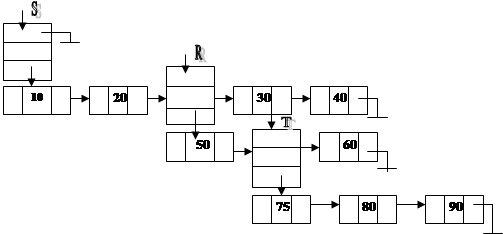
773Рис. 62. Структура набора
Рис. 61. Рекурсивная интерпретация списка
Как следует из рекурсивного определения списка, условием завершения его обработки является достижение пустого списка в процессе применения шагов рекурсии.
Рассмотрим две рекурсивные процедуры, одна из которых распечатывает содержимое информационных полей линейного односвязного списка в прямом порядке (Print_Front), а вторая – в обратном порядке (Print_Back).
| Procedure Print_Front(first: PList); | { распечатка содержимого списка } |
| Begin | { в прямом направлении } |
| If first <> nil then begin | |
| writeln(first^.info); | |
| Print_Front(first^.link) | { задняя рекурсия (см. ниже) } |
| end; | |
| end; |
| Procedure Print_Back(first: PList); | { распечатка содержимого списка } |
| begin | { в обратном направлении } |
| if first <> nil then begin | |
| Print_Back(first^.link) | |
| writeln(first^.info); | |
| end; | |
| End; |
6.3.3. Иерархические линейные структуры данных: наборы
Набор - это ортогональная структура иерархически определенных линейных списков. Набор - это линейная упорядоченная динамическая последовательность, каждый элемент которой является либо атомом, либо набором. Атом определяет “неделимый” элемент набора, предназначенный для хранения элементарной порции информации.
Пример структуры набора представлен на рис. 62:
Описание набора:
S{ 5 } = < 10, 20, R, 30, 40 >;
Эта запись означает, что набор, идентифицируемый указателем S, состоит из пяти элементов: атомов, содержащих значения 10 и 20, набора, идентифицируемого указателем R, и атомов, содержащих значения 30 и 40. Аналогично описаны наборы R и T.
R{ 3 } = < 50, T, 60 >;
T{ 3 } = < 75, 80, 90 >;
 |
Так как набор состоит из разнородных элементов, для реализации наборов используются разнородные списки. Головные элементы наборов одновременно участвуют в двух видах связей: они являются членами набора более высокого уровня (вертикальная связь в иерархии) и членами своего собственного набора (горизонтальная связь). Для того чтобы создать структуру набора, необходимо вначале определить наборы каждого уровня, состоящие только из атомов, а затем в соответствии с определенными условиями включить набор в качестве элемента в набор более высокого уровня.
Создать Т{ 3 } = < 75, 80, 90 >;
Создать R{ 2 } = < 50, 60 >;
Создать S{ 4 } = < 10, 20, 30, 40 >;
Первая директива означает, что необходимо создать набор, идентифицируемый указателем Т и состоящий из трех атомов со значениями 75, 80, 90. Остальные директивы определяются аналогично.
Включить Т в R{ 2 };
Включить R в S{ 3 };
Первая директива означает, что набор Т включается в набор R в качестве второго элемента. Вторая директива означает, что набор R включается в набор S в качестве третьего элемента. Результатом выполнения данных директив является структура набора, показанного на рис. 62.
Описание элемента хранения набора и процедура, распечатывающая значения атомов набора, приведены ниже.
| Type | ||||
| PNabor = ^ Nabor; | { тип – указатель на элемент хранения набора } | |||
| Nabor = record | { тип – элемент хранения набора } | |||
| right: PNabor; | { горизонтальная связь в наборе } | |||
| case t: boolean of | { признак типа элемента набора: } | |||
| true: (under: PNabor); | { набор – вертикальная связь в наборе } | |||
| false: (zn: word) | { атом – значение атома } | |||
| end; | ||||
| Var Head: PNabor; | ||||
| Procedure Write_Nabor(p: PNabor); | { p – указатель на головной элемент набора } | |||
| begin | ||||
| if p <> nil then begin | { набор не пуст? } | |||
| if p^.t then Write_Nabor(p^.under) | { элемент – набор: распечатать набор } | |||
| else writeln(p^.zn); | { элемент – атом: распечатать значение атома} | |||
| Write_Nabor(p^.right) | { распечатать следующий элемент набора } | |||
| end | ||||
| end; | ||||
Структура набора адекватна для отображения динамических вложенных понятий предметной области. Например, в ассоциацию (набор) “Акционеры” могут входить как отдельные частные лица (атомы), так и коллективы – организации, являющиеся ассоциациями собственных акционеров (наборы).
Так как для хранения фреймов активации рекурсивной процедуры используется автоматическая память, при обработке данных нерекурсивной природы следует использовать итеративные алгоритмы, не требующие дополнительного расхода памяти, если только рекурсивные алгоритмы не оказываются более ясными и понятными. Примером алгоритма, обрабатывающего данные нерекурсивной природы, но имеющего гораздо более эффективную рекурсивную реализацию по сравнению с итеративной, яаляется алгоритм решения задачи о “ханойских башнях”. При вычислении же значения факториала натурального числа N несомненно следует предпочесть итеративную процедуру.
Если процедура содержит единственный рекурсивный вызов и он является последним действием процедуры, то говорят, что имеет место задняя рекурсия (tail recursion) (см. процедуру Print_Front). Этот рекурсивный вызов требует затрат на создание фреймов активации и запоминание их в стеке. Когда рекурсивный вычислительный процесс доходит до условия завершения, выполняется серия возвратов, выталкивающих фреймы активации из стека. Если при наличии задней рекурсии фреймы активации не используются для окончательных вычислений, следует предпочесть итеративную реализацию (см. процедуру Print из программного модуля!!!). Рекурсивная процедура Print_Back, не содержащая задней рекурсии, имеет более эффективную реализацию, чем итеративная процедура, выполняющая те же действия.
7. Иерархические Нелинейные структуры данных. деревья