 2015-02-24
2015-02-24 412
412Известно, что симметрическую положительно определенную матрицу можно разложить как 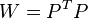 , где P- некоторая невырожденная квадратная матрица. Тогда обобщённая сумма квадратов может быть представлена как сумма квадратов преобразованных (с помощью P) остатков
, где P- некоторая невырожденная квадратная матрица. Тогда обобщённая сумма квадратов может быть представлена как сумма квадратов преобразованных (с помощью P) остатков 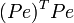 . Для линейной регрессии
. Для линейной регрессии 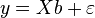 это означает, что минимизируется величина:
это означает, что минимизируется величина:
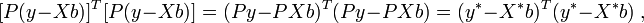
где 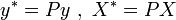 , то есть фактически суть обобщённого МНК сводится к линейному преобразованию данных и применению к этим данным обычного МНК. Если в качестве весовой матрицы
, то есть фактически суть обобщённого МНК сводится к линейному преобразованию данных и применению к этим данным обычного МНК. Если в качестве весовой матрицы 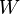 используется обратнаяковариационная матрица
используется обратнаяковариационная матрица 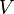 случайных ошибок
случайных ошибок  (то есть
(то есть 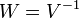 ), преобразование P приводит к тому, что преобразованная модель удовлетворяет классическим предположениям (Гаусса-Маркова), следовательно оценки параметров с помощью обычного МНК будут наиболее эффективными в классе линейных несмещенных оценок. А поскольку параметры исходной и преобразованной модели одинаковы, то отсюда следует утверждение — оценки ОМНК являются наиболее эффективными в классе линейных несмещенных оценок (теорема Айткена). Формула обобщённого МНК имеет вид:
), преобразование P приводит к тому, что преобразованная модель удовлетворяет классическим предположениям (Гаусса-Маркова), следовательно оценки параметров с помощью обычного МНК будут наиболее эффективными в классе линейных несмещенных оценок. А поскольку параметры исходной и преобразованной модели одинаковы, то отсюда следует утверждение — оценки ОМНК являются наиболее эффективными в классе линейных несмещенных оценок (теорема Айткена). Формула обобщённого МНК имеет вид:
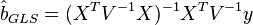
σ2i При i=j
E(ui ,uj )= (4.5)
σij При i ≠j
Оценки ОМНК получаются по формуле β ˆ = (X′ Ω-1) X′ Ω-1 y. Подчеркнем, что для применения ОМНК в (4.5) необходимо знать значения в правой части равенства (в частности элементы матрицыΩ), что на практике случается крайне редко. Поэтому каким либо способом оценивают величины σ2 i, σy, i, j=1,…,n. А затем используют эти оценки в расчетах коэффициентов модели. Этот подход соста  вляет суть так называемого доступного обобщенного метода наименьших квадратов.
вляет суть так называемого доступного обобщенного метода наименьших квадратов.
Вопрос №24. Проверка гипотез о гомоскедастичности регрессионных остатков:
1.Составим вариационный ряд: 0,1,2,3,4,5. Если в статистическом распределении вместо частот (относительных частот) указать накопленные частоты (относительные накопленные частоты), то такой ряд распределения называют кумулятивным.
Накопленная частота представляет собой сумму частот всех значений, от x 1 до xi.: Fi = ∑ij=1 nj. По накопленной частоте можно определить, для какой части выборки значения переменной X не превосходят значения xi.
Если исследуется некоторый непрерывный признак, то вариационный ряд может состоять из очень большого количества чисел. В этом случае удобнее использовать группированную выборку. Для ее получения интервал, в котором заключены все наблюдаемые значения признака, разбивают на несколько равных частичных интервалов длиной h, а затем находят для каждого частичного интервала ni – сумму частот вариант, попавших в i -й интервал. Составленная по этим результатам таблица называется группированным статистическим рядом.
Для получения группированной выборки нужно:
1) Опредеить минимальное и максимальное значение вариант и рассчитываем размах вариационного ряда по формуле: R=Xmax - Xmin
2) Рассчитать число классов по формуле Стерджеса: 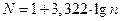
3) Рассчитать интервал каждого класса по формуле: 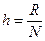
4) Составить таблицу границ классов.
5) Рассчитать среднее значение каждого класса.








