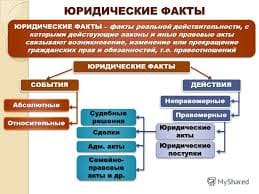
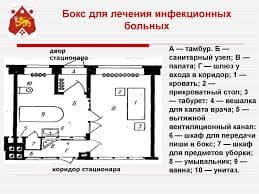
2015-04-12
2015-04-12 643
643Этот алгоритм является самым простым, хотя и далеко не лучшим. Он выражается следующей формулой:
h(x) = x mod N.
Здесь N – размер хеш-таблицы, так что вычисленное значение индекса будет в пределах от 0 до N–1, как принято в программах на C. Если массив описан от 1 до N (как обычно бывает в Паскале), то нужно еще прибавить к индексу единицу.
Вычисление по этой формуле требует выполнения всего одной команды целочисленного деления с остатком. Хотя для большинства процессоров это не самая быстрая команда, требование быстрого вычисления можно считать вполне удовлетворенным. С требованием хорошего рассеивания дело обстоит гораздо хуже. Хотя данная функция покрывает все значения индексов, отображая на каждый из них примерно одинаковое количество допустимых ключей, она плохо справляется с рассеиванием неравномерностей. Во-первых, легко видеть, что соседние (отличающиеся на 1) значения ключей будут почти всегда отображаться на соседние позиции хеш-таблицы. Это уже нехорошо с точки зрения разрешения возможных коллизий. Во-вторых, если значительная часть ключей отстоят друг от друга на расстояние, имеющее общий множитель с размером таблицы N, то число используемых позиций таблицы резко уменьшается, что приведет к частым коллизиям.
Поясним сказанное таким примером. Пусть N = 10 000, а значения всех используемых ключей заканчиваются на 0. Очевидно, что тогда и все значения h(x) тоже будут заканчиваться на 0, т.е. будет использоваться лишь 1/10 часть всех позиций таблицы, что приведет к частым коллизиям.
Чтобы избежать описанной неприятности, в случае использования алгоритма деления стараются в качестве размера хеш-таблицы выбирать простое число, не имеющее общих делителей ни с какими другими числами. Но даже с этим уточнением данный алгоритм используют лишь в задачах, не требующих особо качественного хеширования.