 2015-04-01
2015-04-01 423
423Алгоритм [36], также как и все агломеративные иерархические методы, в начале все точки рассматривает как кластеры и на каждом шаге объединяет наиболее близкую пару. Но вместо подсчета сходства (или расстояния) для каждого кластера выбирается некоторое количество c наилучшим образом представляющих кластер представительных точек, и далее только эти точки используются для определения сходства между кластерами.
В частности, выбирается расстояние между двумя наиболее близкими представительными точками двух кластеров. Определяются представительные точки выбором c наиболее удаленных точек, принадлежащих кластеру и далее уменьшением расстояния между этими точками и центром кластера на некоторую долю a этого расстояния. Если применяется мера, сходства, то уменьшено должно быть сходство.
Таким образом, если a = 0, то метод приближается к методам кластеризации по принципу ближайшего соседа, а в случае a = 1, к центроидным методам. Авторы метода советуют выбирать a от 0.2 до 0.7, что позволит, по их мнению, получать кластеры несферической формы. А значение с предлагают выбирать от 10 до 50, в зависимости от объема данных и предполагаемого размера и формы кластеров.
Выбор таких точек происходит следующим образом. Сначала выбирается первая точка, наиболее удаленная от центра (средней точки, среднего вектора) кластера. И далее на каждом следующем шаге, выбирается точка наиболее удаленная от всех точек, найденных ранее. Предполагается, что эти с представительных точек наилучшим образом отражают форму и геометрические размеры кластеров, к которым они относятся.
Рассмотрим подробнее сам алгоритм кластеризации. В начале, для каждого кластера набор представительных точек содержит всего одну точку, поскольку сами кластеры состоят из одной точки.
Шаг 1. Для каждого кластера находится наиболее близкий кластер.
Шаг 2. Пары, имеющие наибольшее сходство объединяются и для новообразованного кластера находятся представительные точки и наиболее близкий кластер.
Шаг 3. Выполняется пересчет наиболее близкого кластера для некоторого поднабора кластеров. Этому поднабору принадлежат те кластеры, у которых наиболее близкими кластерами были объединенные кластеры. Причем, если близость нового кластера с кластером из этого поднабора еще больше, чем с кластером, вошедшим в объединение, то пересчет не требуется и наиболее близким считается новый кластер. Если полученные на этом шаге кластеры отвечают целевой функции, то завершить кластеризацию, если нет – перейти к шагу 3.
Такой подход позволяет действительно получать кластеры любых, как сферических, так и несферических форм, а также различных размеров. Общая временная сложность этого алгоритма равна O(n2log(n)), где n – количество объектов кластеризации, причем это максимальная сложность, его средняя сложность равна O(n2+nm log(n)), где m – переменное число кластеров, входящих в поднабор на 4-ом шаге. Кроме того, пространственная сложность этого алгоритма за счет использования динамических структур данных (кучи, деревья) равна O(n)).
Также, для увеличения производительности в этом алгоритме применяется прием предварительного разделения. Основная идея такого подхода заключается в том, чтобы разделить пространство n объектов на p равных частей и провести иерархическую кластеризацию в каждой из них, пока количество кластеров в каждой такой части не станет равно
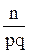 , (39)
, (39)
где q > 0. Далее производиться уже иерархическая кластеризация всех полученных кластеров.
К недостаткам данного метода можно отнести то, что он, при объединении кластеров, не учитывает их внутреннего сходства, то есть он использует целевую функцию для всего разбиения, но не на каждом шаге при выборе объединяемых кластеров. И, разумеется, как и у многих подобных методов, основной недостаток CURE в том, что необходимы задаваемые параметры, от которых в большой степени зависят результаты анализа.








