 2015-05-13
2015-05-13 409
409Частоты, характеризующие ранжированный статистический ряд, можно складывать или накапливать. Накопленные частоты получаются последовательным суммированием значений частот от первой частоты до последней. Введем в ранжированном статистическом ряде дополнительную строчку и назовем ее кумуляты частот.
| Варианты | xi | ||||||||
| Частоты вариант | fi | ||||||||
| Кумуляты частот |
Рассмотрим как получилась эта строчка. В начале ряда стоит 1. В кумулятивном ряду на втором месте стоит 2 – это сумма первой и второй частоты, т.е. 1+1, на третьем месте стоит 4 – это сумма второй накопленной частоты и третьей частоты, т.е. 2+2, на четвертом месте 8=4+4 и т.д.
Если исследуется некоторый непрерывный признак, то вариационный ряд может состоять из очень большого количества чисел. В этом случае удобнее использовать группированную выборку. Для ее получения интервал, в котором заключены все наблюдаемые значения признака, разбивают на несколько равных частичных интервалов длиной h, а затем находят для каждого частичного интервала ni – сумму частот вариант, попавших в i-й интервал. Составленная по этим результатам таблица называется группированным статистическим рядом:
|
|
|
| Номера интервалов | … | k | ||
| Границы интервалов | (a, a + h) | (a + h, a + 2h) | … | (b – h, b) |
| Сумма частот вариант, попавших в интервал | n1 | n2 | … | nk |
Для того чтобы полученные данные представить в еще более компактном виде, используются таблицы распределения сгруппированных частот. Для составления такой таблицы необходимо:
1) общий диапазон изменения признака разделить на ряд поддиапазонов (классов) при условии, что ширина всех классов должна быть одинакова;
2) определить границы классов и их число в общем диапазоне;
3) подсчитать частоты встречаемости признака в каждом классе.
Обычно для построения распределения сгруппированных частот используется 7 – 15 классов. Для наиболее точного разбиения диапазона на классы (если в дальнейшем предполагаются математические операции с этими классами) можно использовать формулу Стэрджесса: N = 1 + 3,322 lg n, где n – объем выборки (количество значений признака), а N – количество классов.
Например, если n = 100, то N = 1 + 3,322 × 2» 8.
Пример
На выборке испытуемых численностью 100 человек определялся коэффициент интеллекта (IQ). Минимальное значениеIQоказалось равным 72, а максимальное – 134. Для составления таблицы сгруппированных частот используем 8 классов (в соответствии с формулой Стэрджесса). Определяем общий диапазон изменения признака – он будет соответствовать разнице между минимальным и максимальным значениями: 134 – 72 = 62. Следовательно, в каждый класс должно попадать по 8 значений признака (при разбиении на классы можно слегка расширить диапазон с тем расчетом, чтобы в каждом классе оказалось одинаковое число значений и чтобы крайние значения не оказались за пределами диапазона). В соответствии с этим определяем границы классов и составляем таблицу сгруппированных частот:
|
|
|
| Номер класса (N) | ... | ||||
| Границы класса (x min ¸ x max) | 72 -79 | 80-87 | 88-5 | ... | 128-135 |
| Среднее значение (х¯) | 75,5 | 83,5 | 91,5 | ... | 131,5 |
| Частоты (f i ) | ... | ||||
| Накопленные частоты (F i) | … |
Накопленные частоты, приведенные в 5-й строке, могут быть использованы в некоторых статистических расчетах (например, для вычисления критерия l по Колмогорову). Накопленные частоты вычисляются путем простого суммирования частот от 1-го до N -го класса: F 1 = f 1; F 2 = f 1 + f 2; F 3 = f 1 + f 2 + f 3 и т. д.
3. Квантили
Квантиль – точка на числовой оси (значение признака), делящая совокупность наблюдений в определенной пропорции. Определение квантилей достаточно часто используется в психодиагностических процедурах (при определении тестовых норм и др.). Для определения квантилей необходимо иметь ряд значений исследуемого признака, ранжированных в порядке возрастания величины.
Различают несколько разновидностей квантилей:
а) квартили (Q)делят совокупность наблюдений (ранжированный ряд) на 4 равные части: 1-й квартиль (Q 1) делит ряд в соотношении 25:75%, 2-й (Q 2) – в соотношении 50:50% и 3-й (Q 3 ) – в соотношении 75:25%.
б) квинтили (K) делят выборку на 5 равных частей: K 1 – в соотношении 20:80%, K 2 – 40: 60%, K 3 – 60:40%, K 4 – 80:20%.
в) децили (D) делят ранжированный ряд на 10 равных частей: D 1 = 10%, D 2 = 20%,... D 9 = 90%.
г) наконец, процентили (Р) делят совокупность наблюдений на 100 частей (в процентном отношении).
Соотношения квантилей можно представить в виде следующей схемы:
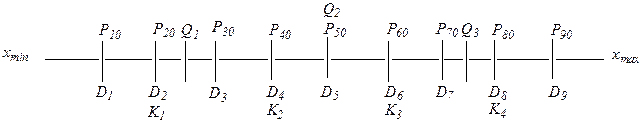
Пример
На 20 испытуемых определялся уровень личностной тревожности (УЛТ) по тесту Спилбергера. При ранжировании значений признака получен следующий вариационный ряд. Задача состоит в том, чтобы определить значения 1-го, 2-го и 3-го квартилей.
| №№ | ||||||||||||||||||||
| УЛТ | ||||||||||||||||||||
Q 1 = 36 Q 2 = 41,5 Q 3 = 45
Для определения значений квартилей разбиваем ранжированный ряд на 4 равные части (по 5 значений признака). 1-й квартиль располагается между 5-м и 6-м значениями ряда, оба из которых соответствуют 36. Следовательно, Q 1 = 36. 2-й квартиль расположен между 10-м значением, равным 41, и 11-м, равным 42. Представляется разумным определить значение 2-го квартиля как среднее между двумя смежными значениями (Q 2 = 41,5). Значение 3-го квартиля лежит между 15-м и 16-м значениями ряда (Q 3 = 45).
Точно так же мы можем определить значения квинтилей (разбиение ранжированного ряда на 5 частей по 4 значения признака) или децилей (разбиение ряда на 10 равных частей по 2 значения переменной в каждой).








