 2015-05-13
2015-05-13 1006
1006Одной из проблем, связанных с решением задач классификации рассматриваемым методом, является то обстоятельство, что не всегда можно легко найти линейную границу между двумя классами. В таких случаях один из вариантов - увеличение размерности, т.е. перенос данных из плоскости в трехмерное пространство, где возможно построить такую плоскость, которая идеально разделит множество образцов на два класса. Опорными векторами в этом случае будут служить объекты из обоих классов, являющиеся экстремальными.
Если классы линейно неразделимы, поступают так: все элементы обучающей выборки вкладываются в пространство Х более высокой размерности с помощью специального отображения 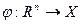 . При этом
. При этом 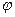 выбирается так, чтобы в новом пространстве Х выборка была линейно разделима. Классифицирующая функция F принимает вид
выбирается так, чтобы в новом пространстве Х выборка была линейно разделима. Классифицирующая функция F принимает вид 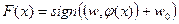 .
.
Выражение 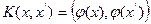 называется ядром классификации. С математической точки зрения ядром может служить любая положительно определенная симметричная функция 2-х переменных. Положительная определенность нужна, чтобы соответствующая функция Лагранжа в задаче оптимизации была ограничена снизу, то есть задача оптимизации корректно определена.
называется ядром классификации. С математической точки зрения ядром может служить любая положительно определенная симметричная функция 2-х переменных. Положительная определенность нужна, чтобы соответствующая функция Лагранжа в задаче оптимизации была ограничена снизу, то есть задача оптимизации корректно определена.
Чаще всего на практике используют следующие ядра.
1. Полиномиальное: 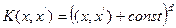 .
.
2. Радиальная базисная функция 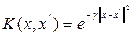 .
.
3. Сигмоид 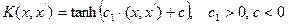 .
.
С одной стороны ядра – одно из самых из самых красивых и плодотворных изобретений в машинном обучении, а с другой стороны до сих пор не найдено эффективного общего подхода к их подбору. Алгоритм классификации в общем виде
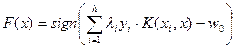 ,
,
где 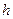 - опорные объекты (пусть это первые после перенумерации).
- опорные объекты (пусть это первые после перенумерации).
Этот алгоритм можно рассматривать как двухслойную нейронную сеть, имеющую 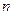 входных нейронов, нейронов в скрытом слое,
входных нейронов, нейронов в скрытом слое,
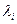 - это вес, выражающий степень важности ядра.
- это вес, выражающий степень важности ядра.
Как и любой другой метод, метод SVM имеет свои сильные и слабые стороны, которые следует учитывать при выборе данного метода.
Недостаток метода состоит в том, что для классификации используется не все множество образцов, а лишь их небольшая часть, которая находится на границах.
Достоинство метода состоит в том, что для классификации методом опорных векторов, в отличие от большинства других методов, достаточно небольшого набора данных. При правильной работе модели, построенной на тестовом множестве, вполне возможно применение данного метода на реальных данных.
Метод опорных векторов позволяет:
· получить функцию классификации с минимальной верхней оценкой ожидаемого риска (уровня ошибки классификации);
· использовать линейный классификатор для работы с нелинейно разделяемыми данными, сочетая простоту с эффективностью.








