2015-05-27
2015-05-27 440
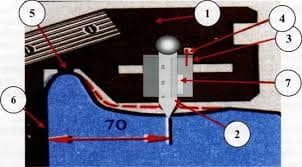
4401. Данные ИО (информационное обеспечение) обычно группируются в отдельные массивы, каждый из которых относится к определенному объекту описания. Такие массивы называются файлами. Вся совокупность файлов образует базу данных, которую можно многократно использовать при проектировании различных РЭС для различных этапов и уровней.
2.
3. Каждый объект предметной области характеризуется своими атрибутами, каждый атрибут имеет имя и значение. Например, объект осциллограф. Имена его атрибутов — частота повторения, чувствительность, полоса пропускания; значения атрибутов — соответствующие значения параметров. Или объект транзистор, имена его атрибутов — наименования параметров, значения атрибутов — значения параметров и т. д.
4, 5. Вся совокупность информации, описывающей один объект предметной области на логическом уровне, называется записью. Запись полностью характеризует объект и все его атрибуты.
Совокупность записей об одной и той же категории объектов образует файл.
6.
7.
8.
9.
10.
11. Для создания, расширения, корректировки и коллективного использования данных создаются специальные системы управления базами данных (СУБД).
По назначению СУБД является элементом информационного обеспечения, так как организует автоматизированное обеспечение проектировщика информацией, а по содержанию это комплекс программ, то есть элемент программного обеспечения.
СУБД должна:
· обеспечивать пользователю возможность создавать новые БД с идентичной логической структурой данных (деление по изучаемым темам);
· позволять записывать, хранить, находить, редактировать и считывать данные;
· поддерживать хранение больших массивов данных, объем базы данных составляет до 150 тыс. слов (entries), в течение долгого времени, защищая их от системных сбоев и случайной порчи (автоматическое восстанавление базы с помощью журналов СУБД);
· обеспечивать модификацию БД;
· позволять осуществлять ввод основной массы данных посредством считывания (записи) массива данных, подготовленного подпрограммой ППРД;
· обеспечить контроль достоверности вводимых данных в каждом поле таблиц БД (обязательное поле, умолчание, шаблон и т.д.);
· предусмотреть возможность объединения или совместного использования нескольких автономно заполненных на других рабочих местах тематических БД при физическом перенесении их с помощью ГМД или CD на основной компютер;
· обеспечивать нахождение слов, выделение, просмотр и редактирование таблиц БД с удобным графическим интерфейсом;
12.
13.
14. Независимость данных это свойство системы управления базой данных, позволяющее программам быть независимыми от изменений в структуре данных
15. Языки, используемые в БД, делят на языки описания данных (ЯОД) и языки манипулирования данными (ЯМД).
В общем случае ЯОД описывает различные типы записей, их имена и форматы, а также служит для определения:
типов элементов данных, которые нужны в качестве ключей;
отношений между записями или их частями и именования этих отношений;
типа данных, которые используются в записях;
диапазона их значений;
числа элементов, их порядка и т. п.;
секретности частей данных и режимов доступа к ним.
Обычно ЯМД дают возможность манипулирования данными без знания несущественных для программиста подробностей. Они могут реализоваться как расширение языков программирования общего назначения путем введения в них специальных операторов или путем реализации специального языка.
При работе с БД используются несколько типов языков:
манипулирования данными;
программирования;
описания физической организации данных.
Языки программирования, применяемые в БД, представляют собой распространенные языки типа ФОРТРАН, КОБОЛ и многие новые языки.
Языки описания логических схем пользователя реализуются средствами описания данных языка прикладного программирования, средствами СУБД, специальным языком.
Наиболее широко распространен первый способ описания. Он имеет в основе операторы объявления (например, DECLARE в языке PL/I, STRUCT в СИ, type в ADA).
Языки описания схем БД предназначены для администратора БД. С их помощью определяют глобальные описания данных.
Языки описания физической организации данных описывают физическую структуру размещения схемы на машинных носителях. С их помощью определяют методы доступа, предписывающие размещение данных на тех или иных носителях, и т. п.
16, 17. Процесс проектирования БД начинают с построения концептуальной модели (КМ). Концептуальная модель состоит из описания объектов и их взаимосвязей без указания способов физического хранения. Построение КМ начинается с анализа данных об объектах и связях между ними, сбора информации о данных в существующих и возможных прикладных программах. Другими словами, КМ — это модель предметной области.
Версия КМ, обеспечиваемая СУБД, называется логической моделью (ЛМ). Подмножества ЛМ, которые выделяются для пользователей, называются внешними моделями (подсхемами). Логическая модель отображается в физическую, которая отображает размещение данных и методы доступа. Физическую модель называют еще внутренней.
Внешние модели не связаны с используемыми ТС и методами доступа к БД. Они определяют первый уровень независимости данных. Второй уровень независимости данных связан с отсутствием изменений внешних моделей при изменении КМ.
18. Независимость данных это свойство системы управления базой данных, позволяющее программам быть независимыми от изменений в структуре данных
19, 20, 21. В настоящее время существует три модели данных: реляционная, сетевая и иерархическая.
В основу реляционной модели положено понятие теоретико-множественного отношения (реляции), которое представляется в виде таблицы. Она является наиболее удобным инженерным представлением для пользователя (рис. 10.3а). Каждый столбец ее соответствует атрибуту объекта, и ему присваивается соответствующее имя. В столбцах таблицы (отношения) вводятся значения атрибутов. Используя отношения связи и язык реляционной алгебры, можно осуществлять выбор любого подмножества информации: по строкам, столбцам или другим признакам. Применяя операции "разрезания" и "склеивания" отношений, можно получить разнообразные файлы в нужной форме (рис. 10.3б).
При использовании реляционной модели атрибут объекта может сам выступать как объект другой предметной области, т.е. задействуется относительность (отсюда — отношение) понятий объекта и его атрибутов.
Иерархическая модель данных — это некоторая их совокупность, состоящая из отдельных деревьев, в которых все связи направлены от одного сегмента, называемого исходным, к нескольким порожденным, т. е. реализуются связи типа "один ко многим" (рис. 10.4а). Сегмент — это одно или несколько полей, являющихся основной единицей обмена между прикладной программой и языком описания данных. При реализации иерархической системы каждое дерево описывается в виде отдельного файла данных.
Сетевая модель данных является более общей структурой по сравнению с иерархической. Каждый отдельный сегмент (ячейка) может иметь произвольное число непосредственных исходных (старших) сегментов, а также и произвольное число порожденных (младших) (рис. 10.4б).

Рис. 10.3. Пример (а) и общий вид (б) реляционной модели данных
Это обеспечивает представление отношения "многие к многим". Сетевые структуры могут быть описаны с помощью раскрашенных файлов.

Рис. 10.4. Иерархическая (а) и сетевая (б) модели данных