 2015-05-30
2015-05-30 2856
2856Может быть представлено как в бумажном, так и в электронном виде, однако, порождается и используется по другим нежели информационного обеспечения корпоративного уровня. К внешнему информационному обеспечению относятся:
· Нормативные документы, регламентирующие поведение предприятия на рынке производства;
· Взаимодействия, регламентирующие с потребительской продукцией;
· Предприятиями, с которыми осуществляется корпорация и поставки и т. п.
Распределение информационного обеспечения по 3 категориям: внутримашинное, внешнее и внемашинное – складывается, прежде всего, в выборе или использовании технологических решений автоматизации доступа и использования данного вида информационного обеспечения. В частности для организации работы с внешними информационными обеспечениями, более всего подходит Internet технологии(в частности http и ftp). Это обусловлено:
1. универсальностью каналов связи внешних по отношению к предприятию
2. характером внешнего информационного обеспечения, который является «долгоживущим» с точки зрения актуальности данных
3. использованием внешнего информационного обеспечения преимущественно «в одну сторону» (чтение и ознакомление без корректировки данных).
В тоже время существует и используются специализированные базы данных и системы для работы с ними, такие например как ГАРАНТ, Консультант плюс. внемашинные и внутримашинные информационные обеспечения говорят, образуют информационную среду корпоративного уровня. С точки зрения технологии автоматизации на корпоративном уровне могут использоваться как универсальные схемы сетевого взаимодействия, так и специализированные (каналы связи: сети). специализированные с использованием универсальных каналов связи: продажа ж\д билетов, банковские системы, системы абонентского обслуживания системы производственных корпораций.
На корпоративном уровне наибольшее распространение как технология создания автоматизированных баз данных получила технология ORACLE (СУБД).
На нижнем уровне любая технология автоматизации замыкается на идеологию организации автоматизированных рабочих мест или APM, каждая из которых представляет из себя:
1. компьютер
2. набор программ приложений непосредственно установленных и функционирующих с данного рабочего места
3. человек – специалист, который выполняет закрепленные за данным рабочим местом функции
В этом случае нужно воспринимать, что основанием организации рабочего места является прикладное программное информационное обеспечение, которое состоит из прикладных программ (программ приложений) и баз данных (элементов информационного обеспечения, внутримашинного уровня необходимо для выполнения функций данного рабочего места).
В этом случае говорят о технологиях обработки данных персонального уровня, и соответствующих программных продуктах поддерживающих этот уровень. Например: My SQL и Access образуют СУБД.
15. Определите структуру и особенности информационных систем персонального, локального и корпоративного уровня.
16. Структура СУБД.
Современное СУБД – это специализированный комплекс программ или просто программный продукт, позволяющий «стандартным» образом осуществлять доступ к данным.
С точки зрения наполнения СУБД представляет из себя набор трех языковых конструкций (язык – директивы или команды, записанные в виде формальных выражениях языка высокого уровня или доступных в интерактивном режиме преимущественно через меню визуального или графического интереса):
1. язык определения данных (ЯОД) – с помощью ЯОД описывается структура и типология данных для последующего их представления в соответствующих базах данных
2. язык манипулирования данных (ЯМД) – включает в себя набор директивов по поиску и преобразованию данных, которые необходимо выполнять в процессе обработки данных, в частности базовые операции манипулирования данных, является запрос на поиск данных
3. язык обслуживания баз данных (ЯОБД) – формальное выражение языка, либо интегрированные манипуляции, которые необходимы для обслуживания носителей информации: копирование, администрирование доступа, и т.п. Как правило, язык управления файлами, которые являются частью операционной среды компьютера (обслуживание файлов или файловые процессы)
17. Что такое АБД, БД, СУБД?
Базами данных называется понятие, которое соотносят как с автоматизированными, так и с неавтоматизированными способами хранения информации.
Состоит из двух компонентов:
1. хранение (библиотека)
2. метод доступа (систематизированный, алфавитный)
Смысл организации баз данных заключается в построении надежного способа хранения информации и построение эффективной процедуры доступа к информации.
Автоматизированная база данных состоит из:
1. баз данных (хранение информации)
2. СУБД (программный инструмент, с помощью которого строятся доступы к информации)
В эволюции программных средств меняются компьютеры, замечено, что данные, с которыми должны работать программы меняются гораздо медленнее. Поэтому основным принципом, обеспечивающим обновления программных методов и инструментов автоматизации является принцип разделения программ и данных.
Современное СУБД – это специализированный комплекс программ или просто программный продукт, позволяющий «стандартным» образом осуществлять доступ к данным.
18. Архитектура СУБД.
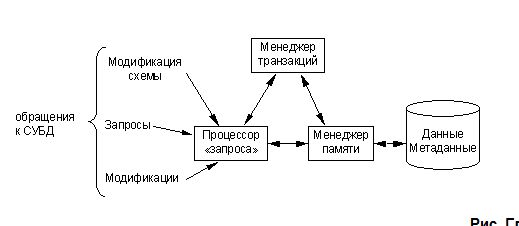
Данные, метаданные — содержат не только данные, но и информацию о структуре данных (метаданные). В реляционной СУБД метаданные включают в себя системные таблицы (отношения), имена отношений, имена атрибутов этих отношений и типы данных этих атрибутов.
Часто СУБД поддерживает индексы данных. Индекс — это структура данных, которая помогает быстро найти элементы данных при наличии части их значения (например, индекс, который находит кортежи конкретного отношения, имеющие заданное значение одного из атрибутов). Индексы — часть хранимых данных, а описания, указывающие, какие атрибуты имеют индексы — часть метаданных.
Менеджер памяти — получает требуемую информацию из места хранения данных и изменяет в нем информацию по требованию расположенных выше уровней системы.
Менеджер файлов контролирует расположение файлов на диске и получает блок или блоки, содержащие файлы, по запросу менеджера буфера (диск в общем случае делится на дисковые блоки — смежные области памяти, содержащие от 4000 до 16000 байт).
Менеджер буфера управляет основной памятью. Он получает блоки данных с диска через менеджер файлов и выбирает страницу основной памяти для хранения конкретного блока. Он может временно сохранять дисковый блок в основной памяти, но возвращает его на диск, когда страница основной памяти нужна для другого блока. Страницы также возвращаются на диск по требованию менеджера транзакций.
Процессор «запроса» — обрабатывает запросы и запрашивает изменения данных или метаданных. Он предлагает лучший способ выполнения необходимой операции и выдает соответствующие команды менеджеру памяти.
Процессор (менеджер) запросов превращает запрос или действие с БД, которые могут быть выполнены на очень высоком уровне (например, в виде запроса SQL), в последовательность запросов на хранимые данные типа отдельных кортежей отношения или частей индекса на отношении. Часто самой трудной частью обработки запроса является его организация, т. е. выбор хорошего плана запроса или последовательности запросов к системе памяти, отвечающей на запрос.
Менеджер транзакций — отвечает за целостность системы и должен обеспечить одновременную обработку многих запросов, отсутствие интерференции запросов (сложение, min, max) и защиту данных в случае выхода системы из строя. Он взаимодействует с менеджером запросов, т. к. должен знать, на какие данные воздействуют текущие запросы (для избежания конфликтных ситуаций), и может отложить некоторые запросы и операции для избежания конфликтов.
19. Внешняя, внутренняя и логические модели данных.
Исходя из трехуровневой архитектуры БД, различают три, связанных между собой, модели данных, получаемых в результате проектирования и отображающие результаты проектирования.
1. Внешняя модель данных, отображает обобщенное представление всех пользователей. Эту модель называют описанием предметной области, формируемым на естественном языке. Представить внешнюю модель можно как в формализованном (схемы, рисунки, таблицы), так и в неформализованном (словесное описание на языке проектировщиков) виде.
2. Концептуальная модель. Она может быть выражена в виде диаграммы, схемы, рисунка, отображающего обобщенное логическое представление информации предметной области (концептуальная информационно логическая модель предметной области) или в виде рисунка, схемы, отображающего обобщенное логическое представление данных (концептуальная логическая модель данных), не зависимое от выбранной СУБД.
3. Внутренняя модель. Является результатом отображения концептуальной модели средствами языка определения данных выбранной СУБД.
В литературе по БД предложено и опубликовано достаточно много различных моделей данных, используемых при проектировании БД как инструментальное средство. Модели, отображающие уровни архитектуры БД, строятся по правилам этих моделей.
20. Языки описания и манипулирования данными.
СУБД включает два основных компонента:
1. ЯОД – язык описания данных
2. ЯМД - язык манипулирования данными
«Язык» понимается в расширительном смысле, включая в себя определенную систему понятий: «знаковую систему отображения этих понятий и способов использования данных понятий».
Конструкций языков много: dBASE, FoxPro.
ЯОД и ЯМД строятся на основе логических моделей данных. Логической моделью данных является некоторый способ представления информации или описание реальных объектов в физическую меру.
21. Обслуживание и администрирование данных
На физическом уровне конечным элементом представления данных является некий поименованный по правилам файлов системы неделимый элемент данных или файл, являющийся единицей хранения информации.
Исходный набор действий над файлами – операция, связанная с созданием, хранением, перемещением файлов; составляет основу языка обслуживания данных любой СУБД.
Особенностью обслуживания данных в рамках любой СУБД являются дополнительные (т. е. принятые) механизмы администрирования файлов с точки зрения информационной безопасности. Доступ со стороны файловых процессов невозможен (закрыта оболочка). Первый уровень обслуживания данных FTP-сервер.
22. Файловая организация данных и структурированные данные.
Файловая система определяет способ организации, хранения и именования данных на носителях информации. Она определяет формат физического хранения информации, которую принято группировать в виде файлов. Конкретная файловая система определяет размер имени файла, максимальный возможный размер файла, набор атрибутов файла. Некоторые файловые системы предоставляют сервисные возможности, например, разграничение доступа или шифрование файлов.
Файловая система связывает носитель информации, с одной стороны, и API для доступа к файлам — с другой. Когда прикладная программа обращается к файлу, она не имеет никакого представления о том, каким образом расположена информация в конкретном файле, также, как и на каком физическом типе носителя (CD, жёстком диске, магнитной ленте или блоке флеш-памяти) он записан. Всё, что знает программа — это имя файла, его размер и атрибуты. Эти данные она получает от драйвера файловой системы. Именно файловая система устанавливает, где и как будет записан файл на физическом носителе (например, жёстком диске).
Структурированные типы данных предназначены для задания сложных структур данных. Структурированные типы данных конструируются из составляющих элементов, называемых компонентами, которые, в свою очередь, могут обладать структурой. В качестве структурированных типов данных можно привести следующие типы данных: массивы и записи (структуры).
С математической точки зрения массив представляет собой функцию с конечной областью определения. Например, рассмотрим конечное множество натуральных чисел
называемое множеством индексов. Отображение из множества во множество вещественных чисел задает одномерный вещественный массив. Значение этой функции для некоторого значения индекса называется элементом массива, соответствующим. Аналогично можно задавать многомерные массивы.
Запись (или структура) представляет собой кортеж из некоторого декартового произведения множеств. Действительно, запись представляет собой именованный упорядоченный набор элементов, каждый из которых принадлежит типу. Таким образом, запись есть элемент множества. Объявляя новые типы записей на основе уже имеющихся типов, пользователь может конструировать сколь угодно сложные типы данных.
Общим для структурированных типов данных является то, что они имеют внутреннюю структуру, используемую на том же уровне абстракции, что и сами типы данных.
Поясним это следующим образом. При работе с массивами или записями можно манипулировать массивом или записью и как с единым целым (создавать, удалять, копировать целые массивы или записи), так и поэлементно. Для структурированных типов данных есть специальные функции - конструкторы типов, позволяющие создавать массивы или записи из элементов более простых типов.
Работая же с простыми типами данных, например с числовыми, мы манипулируем ими как неделимыми целыми объектами. Чтобы "увидеть", что числовой тип данных на самом деле сложен (является набором битов), нужно перейти на более низкий уровень абстракции. На уровне программного кода это будет выглядеть как ассемблерные вставки в код на языке высокого уровня или использование специальных побитных операций
23. ftp:/ и http:/ сервисы.
На более высоком уровне, но также это уровень физического представления механизм обмена данными между компьютерами реализован в виде FTP протокола (file transport protocol), а на уровне файлов системы компьютера в форме файловых процессов или программных оболочек.
Важно, что на физическом уровне конечным элементом представления данных является некий поименованный по правилам файлов системы неделимый элемент данных или файл, являющийся единицей хранения информации.
Исходный набор действий над файлами – операция, связанная с созданием, хранением, перемещением файлов; составляет основу языка обслуживания данных любой СУБД.
Особенностью обслуживания данных в рамках любой СУБД являются дополнительные (т. е. принятые) механизмы администрирования файлов с точки зрения информационной безопасности. Доступ со стороны файловых процессов невозможен (закрыта оболочка). Первый уровень обслуживания данных FTP-сервер.
Преимуществом информационной технологии для работы с внешней и определенным условиям корпоративной информации является Интернет технологии ftp, http-сервисы. Протокол передачи файлов (File Transfer Protocol, FTP) дает пользователям простой путь передачи файлов на и с FTP сервера.
При использовании http-протокола, информация, структурированная до уровня неделимых с точки зрения поиска и передачи данных, информационных единиц, файлов.
Http-протокол является удобным способом для структурирования информационных массивов с точки зрения восприятия их информационного содержания. Наименьшей информационной единицей в http-протоколе является понятие «фрейм» - рамка, содержанием которой может быть либо конечная информационная единица (рисунок, текст), либо гиперссылка.
Используемая на этом уровне технология представления данных удобна для передачи и хранения информации, ее использования вне компьютера, т.е. людьми.
24. Иерархическая модель данных.
Наиболее часто встречающаяся модель без автоматизированной обработки информации – иерархическая модель данных. Данные структурируются следующим образом:
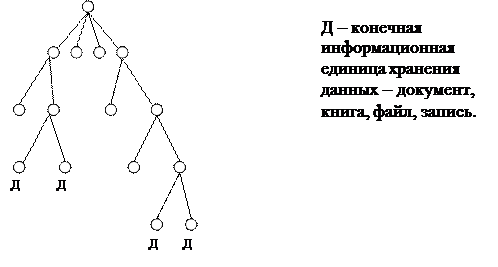

Данная модель отражает способ кодирования (построения) записи, а точнее имени записи, которая строится как иерархический классификатор. По такому принципу построены, например, алфавитный и систематический каталоги. В производственных системах иерархический способ соответствует принципу построения сложных технических объектов и используется для создания имен уникальных документов вхождения производственных единиц в конечную продукцию (по принципу: изделие – агрегат – узел - деталь). Иерархический способ кодирования производственных систем строится в соответствии с универсальными десятичными классификаторами и фиксируется в основной надписи любого конструкторского технического документа.
Иерархический способ по сравнению с другими моделями позволяет очень быстро осуществлять поиск необходимой информации в массивах большого объема. Поисковая операция заключается в анализе уникального имени и ограниченного числа операций выборки а соответствии с уровнем иерархии.
Недостаток иерархического способа заключается в том, что на определенном уровне при недостаточно развитой системе построения уникальных имен полученный массив может оказаться слишком большим, т.е. под одним именем могут храниться множество записей. Признаки, используемые для идентификации записи, называются ключами.
25. Сетевая модель данных.
Сетевая модель данных очень хорошо описывает структуру организационно-технической деятельности, связанной с решением задач управления. Основной операцией для такой структуры является поиск массива информационных единиц, образующих пути,
Сетевая модель является наиболее перспективной для организации интеллектуальных систем обработки информации. В частности, широко используются сематические сети и сети фреймов и фреймы. На этом основано описание технологий в Internete.
26. Реляционная модель данных.
В теоретическом смысле представление информации в виде реляционной модели является наиболее фундаментальным, матем. Обоснованным того раздела деятельности, который называется компьютеризацией науки. (CS – computer since)
За термином «реляционная модель» стоит понятие реляционная алгебра, которое ввёл американец Кодд, в другом варианте Кодд «Компьютерная матем.» Реляционная модель является уникальной с точки зрения её формальной проработки. Реляционное представление может быть проинтегрировано в терминах любых других логических моделей данных.
Следствие этого факта является то, что существующее многообразие программных реализаций СУБД, реализаций типа dBase, Clipper, For Base, Access по сути построены на одном и том же матем. аппарате реляционной алгебры и представляют из себя одинаковый по смыслу набор процедур, вытекающих из соответствующих операций реляционной алгебры и отличаются «технологией» программной реализации.
Таблица представляет собой такой же элемент данных, состоящих из строк и столбцов; информационная единица – запись в строке, которая обладает определённой структурой, задаваемой перечнем имён и типов столбцов, потом все записи будут совпадать.
Понятию отношение соответствует понятие таблица,,строке- кортеж, столбцу домен
Обобщение:
Реляционная модель (алгебра) как синоним алгебры операций над таблицами также как сложение, вычитание – операция над числами. Операции реляционной алгебры – слияние таблиц, удаление, ставка записей, а их программные реализация – операторы или команды языка СУБД (Insert, Delete).
В развёрнутой форме реляционная СУБД наиболее приспособлена таким образом для обработки табличной информации и является естественным механизмом или инструментом для автоматизации представлений обработки табличной информации. Представление информации в табличной форме является естественным в системах организационно-технического управления.
В технической сфере – табличные документы естественным образом описывают состав проектируемых и выпускаемых объектов.
27. Структура реляционного представления. Атрибуты, кортежи, домены.
Реляционная модель данных была предложена Е. Коддом в 1970 г. В основе реляционной модели данных лежит понятие отношения.
Отношение – подмножество декартова произведения одного или более доменов.
Домен – множество возможных значений конкретного атрибута.
Атрибут – свойство объекта, явления или процесса. Примеры атрибутов: фамилия, имя, отчество, дата рождения.
Кортеж – элемент отношения, это отображение имен атрибутов в значения, взятые из соответствующих доменов. Конечное множество кортежей образует отношение. Если отношение создается из n доменов, то каждый кортеж имеет n компонент.
Следующие наборы терминов эквивалентны:
отношение, таблица, файл;
кортеж, строка, запись;
атрибут, поле.
Реляционная база данных – это совокупность отношении, содержащих всю информацию, которая должна храниться в базе данных.
28. Создание простейшей информационно-аналитической системы
Существуют два принципиально различных подхода к проектированию информационно-аналитических систем (ИАС). В первом из них система создается на основе известных типов объектов и связей действующих между ними. Такие ИАС включают информацию двух типов: административно-справочную и экспериментально-мониторинговую. Хотя сбор информации в них может быть организован на систематической основе, однако нет гарантий, что состав, количество и качество имеющихся данных будут достаточны для решения возникающих задач. Последовательность действий при проектировании ИАС на основе такого подхода такова: Выбор цели создания ИАС -> Изучение объектов -> Выбор компоновки ИАС -> Определение состава подсистем -> Разработка структуры БД -> Накопление и ввод информации -> Испытание ИАС.
Другой возможный подход к проектированию ИАС полностью ориентирован на постановку и решение конкретных задач информационного менеджмента. Это могут быть задачи управления транспортными потоками в городе, мониторинга воздушного или водного бассейнов, выбора мест строительства автозаправочных станций и т.д. При этом сбор данных организуется не под «объект», как в первом варианте, а под «задачу». Другими словами сбор информации во втором подходе не является самодостаточным, а необходимым условием достижения цели, выраженной в формализованной постановке задачи.
29. Создание справочной системы и оптимальный подбор по параметру
Содержание справочной системы включает список тем, доступных в системе. Каждая тема имеет заголовок и уникальный символьный идентификатор. Дополнительно каждой теме можно поставить в соответствие уникальный индекс темы, который должен быть целым числом.
В справочной системе для поиска темы используются ключи, содержащие название темы и ссылку на нее. Каждая тема может иметь более одного ключа поиска. Кроме того, один ключ может содержать ссылку на несколько тем.
Для организации контекстного вызова темы из справочной системы вы можете использовать числовые значения индексов или значения ключа. Использование идентификаторов тем для контекстного вывода справочной информации не допускается.
Чтобы связать между собой отдельные темы, используются перекрестные ссылки. При этом текст, используемый для организации перекрестной ссылки, выделяется зеленым цветом и подчеркиванием.
В описании любой системы используются термины, специфичные для конкретной системы. Например, в системах складского учета такими терминами будут накладная, счет, отпуск товара. В качестве термина может рассматриваться не только отдельное слово, но и любая фраза из текста темы. Справочная система Windows позволяет дать каждому термину приложения краткое определение. Такие термины на экране выделены зеленым цветом и пунктирным подчеркиванием. Если щелкнуть мышью на термине, для которого определено краткое описание, это описание появится на экране в рамке поверх текста темы.
30. Использование элементов управления.
элементом управления называют любой, объект фор-. мы или отчета, который служит для вывода данных на экран, оформления или выполнения макрокоманд. Элементы управления могут быть связанными, вычисляемыми или свободными.
Связанный (присоединенный) элемент управления присоединен к полю базовой таблицы или запроса. При вводе значения в связанный элемент управления поле таблицы текущей записи автоматически обновляется. Поле таблицы является источником данных связанного элемента управления.
Вычисляемый элемент управления создается на основе выражений. В выражениях могут использоваться данные полей таблицы или запроса, данные другого элемента управления формы или отчета и функции.
Свободные элементы управления предназначены для вывода на экран данных, линий, прямоугольников и рисунков. Свободные элементы управления называют также переменными или переменными памяти.
Все элементы управления могут быть добавлены в форму или отчет с помощью панели инструментов элементов управления, которая появляется при работе с формой или отчетом.
31. Оптимизация данных с использованием диаграмм
Диаграммы можно использовать не только для визуализации данные, но и для их анализа. При подборе оптимальных значений параметров можно найти исходное значение, которое, будучи использовано в формуле, приведет к нужному результату.
Чтобы изменить значения, полученные из формул ячеек листа, в плоских гистограммах, линейчатых, круговых и кольцевых диаграммах, графиках, точечных и пузырьковых диаграммах, перетащите маркер данных в диаграмме. Для этого выделите щелчком мыши ряд данных, значения которого следует изменить. Затем еще раз щелкните мышью, не меняя положение указателя. Для линейчатых диаграмм и гистограмм перетащите с помощью мыши верхний центральный маркер выделения". Для круговых и кольцевых диаграмм перетащите с помощью мыши наибольший маркер выделения на внешней границе маркера данных. При этом автоматически будут изменены исходные данные в таблице. Если значение маркера данных получено из формулы, появится диалоговое окно Подбор параметра (Goal Seek)
Сущ. стандартные типы: гистограмма, линейчатая, график, круговая, с областями, точечная, кольцевая, лепестковая, поверхность, пузырьковая, биржевая, цилиндрическая, коническая, пирамидальная И нест.
Стройте диаграмму на отдельном листе (Вставка/Диаграмма) или на том же листе. Тип диаграммы выберите исходя из соображений наглядности. Далее следуйте указаниям мастера создания диаграмм.
Системы управления базами данных
32. Создание информационно-справочной системы с использованием локальных справочников.
33. Многомерный анализ данных.
В специализированных СУБД, основанных на многомерном представлении данных, данные организованы не в форме реляционных таблиц, а в виде упорядоченных многомерных массивов:
1) гиперкубов (все хранимые в БД ячейки должны иметь одинаковую мерность, то есть находиться в максимально полном базисе измерений) или
2) поликубов (каждая переменная хранится с собственным набором измерений, и все связанные с этим сложности обработки перекладываются на внутренние механизмы системы).
Использование многомерных СУБД оправдано только при следующих условиях:
1. Объем исходных данных для анализа не слишком велик (не более нескольких гигабайт), то есть уровень агрегации данных достаточно высок.
2. Набор информационных измерений стабилен (поскольку любое изменение в их структуре почти всегда требует полной перестройки гиперкуба).
3. Время ответа системы на нерегламентированные запросы является наиболее критичным параметром.
4. Требуется широкое использование сложных встроенных функций для выполнения кроссмерных вычислений над ячейками гиперкуба, в том числе возможность написания пользовательских функций.
34. Использование форм при создании информационных систем.
Важнейшей проблемой, решаемой при проектировании баз данных, является создание такой их структуры, которая бы обеспечивала минимальное дублирование информации, упрощала процедуры обработки и обновления данных. Нормальные формы – набор формальных требований универсального характера к организации данных, которые позволяют эффективно решать перечисленные задачи.
Каждой нормальной форме соответствует некоторый набор ограничений. Отношение находится в определенной нормальной форме, если оно удовлетворяет набору ограничений этой формы.
Формы – средства для ввода данных. Смысл их в том, чтобы предоставить пользователю средства для заполнения только тех полей, которые ему заполнять положено. Одновременно с этим в форме можно разместить специальные элементы управления (счетчики, списки, переключатели и пр.) для автоматизации ввода.
С помощью форм информацию можно не только вводить, но и отображать. При выводе данных с помощью форм можно применить специальные средства оформления. Иногда формы, предназначенные для вывода на экран, называют формами просмотра, а формы, предназначенные для ввода данных – формами ввода.

