 2015-06-10
2015-06-10 4750
47501. Открыть книгу MS Excel «Простая замена.xlsm», в строке предупреждения включить выполнение макросов.
2. Скопировать текст криптограммы (без знака конца абзаца) из Приложения 2 в соответствии с номером варианта (выбор варианта осуществляется по порядковому номеру в официальном списке группы).
3. Перейти на лист «Загрузить криптограмму» и выбрать ячейку B3. Установить курсор мыши в строку формул, вставить в нее скопированный текст и нажать Enter. Затем нажать кнопку Загрузить криптограмму.
4. После загрузки криптограммы будет открыт лист «Криптограмма». Под символами криптограммы по мере расшифровки должны отображаться символы открытого текста. Первоначально отображаются знаки ###, что указывает на то, не установлено никаких соответствий между символами криптограммы и символами нормативного алфавита.
ЗАМЕЧАНИЕ. В силу особенностей реализации книги «Простая замена.xlsm», текст криптограммы, наряду с цифрами – символами алфавита шифрования может содержать только знаки пробела, двойных кавычек, «.», «,», «;», «:», «!», «-». Если текст содержит другие знаки (например, «?», скобки, «…» и т.п.), после загрузки криптограммы следует очистить ячейки, содержащие эти символы с помощью клавиши Del. Нельзя использовать операцию вырезки  , используйте только операцию копирования и клавишу Del.
, используйте только операцию копирования и клавишу Del.
5. Подсчитать частоты появления символов криптограммы:
· Двузначные числа, составляющие криптограмму последовательно занести в столбец G таблицы «Назначить» на листе «Частоты символов». По мере занесения чисел соответствующие им знаки ### на листе «Криптограмма» будут заменены на символ «_». Поэтому заносить в таблицы следует только те числа, для которых отображаются ###.
· После того, как все символы шифр-алфавита занесены в таблицу «Назначить» (о чем свидетельствует отсутствие знаков ### на листе «Криптограмма»), скопировать значения из столбца G таблицы в столбец A таблицы «Статистика - Криптограмма» на листе «Частоты символов». В столбце B отобразятся частоты встречаемости в криптограмме символов шифр-алфавита (использованных для шифрования текста двузначных чисел).
6. После того, как все символы криптограммы занесены в таблицы «Криптограмма» и «Назначить», следует снять защиту с листа «Частоты символов». Для этого перейти на лист «Частоты символов» (команда Рецензирование/Снять защиту листа).
7. На листе «Частоты символов» упорядочить таблицу «Криптограмма» по столбцу «Част» в порядке убывания частот, а таблицу «Назначить» – по столбцу «Крипт» в порядке возрастания значений символов шифр-алфавита (Данные/ Сортировка).
8. После переупорядочения защитить лист «Частоты символов» (Рецензирование / Защитить лист).
9. На листе «Частоты символов» приведены стандартные частоты символов русского языка для нормативного алфавита без пробела. Диаграммы позволяют провести визуальное сравнение стандартных частот и частот криптограммы.
10. Высказать предположение относительно соответствия наиболее часто встречающихся символов буквам «О» и «Е» и занести эти буквы в таблицу «Назначить» рядом с нужными символами шифр-алфавита. Буквы отобразятся на листе «Криптограмма» в соответствующих местах текста.
ЗАМЕЧАНИЕ. Поскольку текст криптограммы не слишком велик, следует учесть, что закономерности русского языка могут проявляться в нем не в строгом соответствии с таблицей стандартных частот.
11. Проанализировать правильность выдвинутой гипотезы с точки зрения закономерностей русского языка. Если имеется несоответствие, следует переназначить буквы символам шифр-алфавита в таблице «Назначить» на листе «Частоты символов».
12. Используя рекомендации по криптоанализу, последовательно выдвинуть гипотезы относительно соответствия между другими символами криптограммы и буквами русского языка, каждый раз:
· задавая соответствие в таблице «Назначить» на листе «Частоты символов»,
· проводя анализ корректности полученной частичной расшифровки с точки зрения русского языка на листе «Криптограмма»,
· изменяя, в случае несоответствия, сделанные на листе «Частоты символов» назначения.
13. После завершения расшифровки текста показать его преподавателю.
Контрольный вопрос:
1. Что является ключом (секретным параметром) шифра простой замены?
(Ключом шифра простой замены является соответствие между символами нормативного и шифр-алфавитов)
2. Почему нельзя сопоставить символ открытого текста символу шифра, используя только данные о частотах встречаемости символов?
(Частоты символов русского языка отражают закономерности появления символов по всем текстам русского языка. Частоты встречаемости символов криптограммы отражают закономерности конкретного текста. Каждый конкретный текст имеет свои индивидуальные особенности, поэтому распределение частот может отличаться)
Лабораторная работа №11. Криптоанализ многоалфавитных шифров (шифр Виженера)
Рассмотренный ранее шифр простой замены является одноалфавитным, поскольку каждый символ алфавита криптограммы всегда заменяет один и тот же символ нормативного алфавита. Простейшим примером такого шифра является шифр Цезаря, в котором алгоритм шифрования получается путем циклического сдвига нормативного алфавита на S позиций (рис.46).
| порядковый № символа | ||||||||||
| алфавит исходного текста | a | b | c | d | e | w | x | y | z | |
| ¯ | ¯ | ¯ | ¯ | ¯ | … | ¯ | ¯ | ¯ | ¯ | |
| алфавит шифра | d | e | f | g | h | z | a | b | c | |
| порядковый № символа |
Рис.46. Пример шифра Цезаря
Пронумеровав буквы алфавита, начиная с нуля, получим математическое описание этого шифра:
ci = (ai + S)mod L,
где ai, ci – i -тый элемент открытого текста и шифр-текста соответственно, L – мощность (количество различных символов) нормативного алфавита, S – сдвиг, одинаковый для всех символов, 0≤ S ≤ L -1. При S =0 алфавит шифрования совпадает с нормативным.
Многоалфавитные шифры используют не один, а целый набор алфавитов шифрования, примером многоалфавитной замены является шифр Виженера.
Шифрование осуществляется по таблице, представляющей собой квадратную матрицу размерностью L × L, где L – мощность (число различных символов) используемого алфавита. Первая строка содержит все символы нормативного алфавита. Каждая следующая строка получается из предыдущей циклическим сдвигом на один символ влево.
Далее выбирается ключ или ключевая фраза. После чего шифрование осуществляется следующим образом:
· под каждой буквой исходного сообщения последовательно записываются буквы ключа;
· если ключ оказался короче сообщения, его последовательно используют несколько раз;
· каждая буква шифр-текста находится на пересечении столбца таблицы, определяемого буквой открытого текста, и строки, определяемой буквой ключа.
На рис.47 показана таблица Виженера для русского языка (алфавит без буквы «Ё», содержит пробел). В таблице выделены строки – алфавиты шифрования, используемые, если выбрано ключевое слово «МАЯК».
Пример шифрования. Пусть требуется зашифровать открытый текст «ГРУЗИТЕ АПЕЛЬСИНЫ БОЧКАМИ», выбрано ключевое слово «МАЯК»:
| Исходное сообщение | Г | Р | У | З | И | Т | Е | _ | А | П | Е | Л | Ь | С | И | Н | Ы | _ | Б | О | Ч | К | А | М | И |
| Ключ | М | А | Я | К | М | А | Я | К | М | А | Я | К | М | А | Я | К | М | А | Я | К | М | А | Я | К | М |
| Криптограмма | П | Р | С | С | Ф | Т | Г | Й | М | П | Г | Х | З | С | Ж | Ч | Ж | _ | _ | Ш | В | К | Я | Ц | Ф |
В многоалфавитных шифрах один и тот же символ шифр-текста может заменять разные символы открытого текста. Так, в рассмотренном примере буква «С» заменяет в разных случаях буквы «У», «З» и «С»; символ «_» – букву «Б» и символ «_».
Буквы ключа определяют величину смещения символов криптограммы относительно символов открытого текста. Таким образом,
ci = (ai + Si )mod L,
где ai, ci – i -тый элемент открытого текста и шифр-текста соответственно, L – мощность (количество различных символов) нормативного алфавита, Si – сдвиг, определяемый i -тым символом гаммы.

Рис.47. Пример таблицы Виженера
Гамма получается периодическим повторением некоторого ключевого слова. Например, ключевое слово «МАЯК» порождает гамму вида «МАЯКМАЯКМАЯК…». Si – числовой эквивалент соответствующей буквы ключа, 0 ≤ Si ≤ L -1.
Шифр Цезаря является частным случаем шифра Виженера с периодом гаммы, равным единице.
Шифры многоалфавитной замены маскируют естественную частоту появления символов в тексте. Поэтому многоалфавитные замены значительно надежнее одноалфавитных. Однако, частотный анализ применим и в этом случае.
Пусть М – длина ключевого слова. Если ключевое слово короче шифруемого текста, то ключевое слово будет последовательно повторяться, поэтому М – период гаммы.
Разобьем криптограмму на блоки, равные по длине периоду гаммы. Символы криптограммы, занимающие одинаковое положение в таких блоках, имеют одинаковое смещение относительно символов исходного текста, то есть для их получения использован один и тот же алфавит шифрования. Этот алфавит шифрования задает шифр простой замены, а именно, простейший случай замены – шифр Цезаря.
Описанное свойство дает возможность применить частотный анализ для каждой группы символов криптограммы, соответствующих определенной букве ключа. Такие группы символов называют группами периода. Число групп периода равно длине ключа M.
Частотный анализ символов, составляющих группу периода, позволяет криптоаналитику определить величину смещения нормативного алфавита для каждой группы, то есть ключ шифрования. Такой метод криптоанализа может быть эффективен, если длина криптограммы N превышает 20*M (N > 20M), М – длина ключа.
Обычно криптоанализ шифра Виженера проводится в два этапа. На первом этапе определяется число M, на втором этапе – само ключевое слово.
Для определения числа M применяется тест Казиски, названный в честь Ф. Казиски, применившего его в 1863 г. Тест основан на простом наблюдении о том, что два одинаковых отрезка открытого текста, отстоящих друг от друга на расстоянии, кратном M, будут одинаково зашифрованы. В силу этого в криптограмме ищутся повторяющиеся фрагменты длиной, не меньшей трех, и определяются расстояния между ними. Случайное появление в шифр-тексте таких одинаковых фрагментов достаточно маловероятно.
Пусть d1, d2,... – найденные расстояния между повторениями и d – наибольший общий делитель (НОД) этих чисел. Тогда M должно быть cреди делителей d. Чем больше повторяющихся фрагментов имеется в шифр-тексте, тем более вероятно, что M совпадает с d.
Для определения значения M, можно использовать автокорреляционный метод. Текст криптограммы выписывается в строку, под ним выписываются строки, в которых текст сдвинут влево на 1, 2, 3, 4 и так далее позиции (t =1,2,3,…). Затем для каждой строки подсчитывается число позиций (столбцов), в которых символ совпал с символом исходной строки в той же позиции (ci = ci+t). Для каждой строки вычисляются автокорреляционные коэффициенты, равные отношению числа совпадений к длине строки. Для t, кратных периоду гаммы, автокорреляционные коэффициенты должны быть заметно больше, чем для сдвигов, не кратных периоду.
Для проверки правильности выбора значения М, может быть использован метод индекса совпадения, введенный в практику в 1920 году американским криптологом и криптоаналитиком У. Фридманом, впервые успешно применившим вероятностно-статистические методы в криптологии.
Индексом совпаденияIС (х) для последовательности х = (x1,...,xm), составленной из букв алфавита A, называется вероятность того, что две случайно выбранные буквы из этой последовательности совпадают.
Пусть A – алфавит мощностью L, состоящий из символов ai, i = 0,…,L-1; A = {a1,...,aL-1}. Значение индекса совпадения экспериментально может быть получено как:
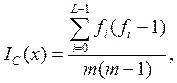
где fi – число появлений буквы ai в последовательности x.
Пусть х – строка осмысленного текста на естественном языке. Допустим, что буквы в х появляются в любом месте текста с вероятностями р0,...,рL-1 независимо друг от друга, рi – вероятность появления буквы ai в осмысленном тексте. Тогда, при достаточно больших m и определении pi как pi = fi / m получаем приближённую формулу:
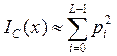 .
.
Взяв за основу значения вероятностей рi для открытых текстов на естественном языке (например, из таблицы 6 частот букв русского языка и подобных таблиц), можно получить теоретически ожидаемые значения индекса совпадения для разных языков (табл.11).
Таблица 11. Индексы совпадения европейских языков
| Язык | Русский | Русск. с пробелом | Алгл. | Франц. | Нем. | Итал. | Испан. |
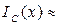 | 0,055 | 0,068 | 0,066 | 0,078 | 0,076 | 0,074 | 0,077 |
Шифрование некоторого открытого текста шифром простой замены не изменяет значения индекса соответствия. Действительно, в этом случае вероятности рi переставляются местами, но значение их суммы остается неизменной. Таким образом, значения из таблицы 11 будут справедливы для любых шифров простой замены, в том числе, и в случае, когда х является группой периода шифра Виженера.
В то же время, если последовательность х – реализация независимых испытаний случайной величины, имеющей равномерное распределение, то индекс совпадения вычисляется по формуле:
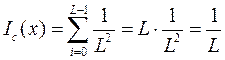 .
.
Таким образом, если х является случайной последовательностью букв алфавита А мощностью L, значение индекса соответствия будет ощутимо ниже – около 1/L. Для русского языка это значение составляет 0,030.
Заметная разница значений IС(x) для осмысленных текстов и случайных последовательностей букв позволяет в большинстве случаев установить точное значение периода гаммы (длины ключевого слова) M в шифре Виженера.
Пусть у = (у1,у2,…,уN) – криптограмма, полученная шифром Виженера, и пусть высказано предположение относительно периода гаммы (длины ключевого слова) M. Выпишем символы шифр-текста y построчно с периодом M и обозначим столбцы получившейся таблицы через Y ↓ i,i = 1,…,M:
| Y ↓ 1 | Y ↓ 2 | … | Y ↓ M |
| y1 | y2 | … | yM |
| yM+1 | yM+2 | … | y2M |
| y2M+1 | y2M+2 | … | y3M |
| … | … | … | … |
Если M – это истинная длина ключевого слова, то каждый столбец Y ↓ i, i = 1,…, M, представляет собой группу периода – участок открытого текста, зашифрованный простой заменой – шифром Цезаря со сдвигом Si, определяемым i символом ключевого слова. Поэтому, из таблицы 11, IС(Y↓i) ≈ 0,055 при любом i (для русского текста).
С другой стороны, если M было выбрано неверно и отлично от длины ключевого слова, то столбцы Y↓i будут более похожи на случайные последовательности букв, поскольку они являются результатом зашифрования фрагментов открытого текста некоторым многоалфавитным шифром. Тогда значения IС(Y↓i) будут ближе к числу 1/L (для русского языка ≈ 0,030).
Предположим, что на первом этапе мы нашли длину ключевого слова M. Теперь требуется найти само ключевое слово, то есть определить сдвиги Si, i = 1,…,M каждой из групп периода.
Для решения этой задачи может быть использован взаимный индекс совпадения.
Пусть х = (х],...,хm), у = (у1,...,ут¢) – две последовательности (строки) букв алфавита А.
Взаимным индексом совпаденияМIс(х,у) последовательностей х и у называется вероятность того, что случайно выбранная буква из х совпадает со случайно выбранной буквой из у.
Пусть f0, f1,…, fL-1 и f¢0, f¢1,…, f¢L-1 – частоты вхождений букв алфавита A в строки х и у соответственно. Тогда:
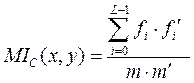 .
.
Рассмотрим относительные сдвиги Si-Sj групп периода Y ↓ i и Y ↓ j.
При нулевом сдвиге между столбцами – группами периода индекс MIc(x,y) близок к индексу совпадения в естественном языке (табл.11). Ненулевые относительные сдвиги дают более низкие значения индекса взаимного совпадения. Это наблюдение позволяет определить величины относительных сдвигов Si-Sj столбцов Y↓i и Y↓j.
Используя изложенный метод, можно связать системой уравнений относительные сдвиги различных пар столбцов Y ↓ i и Y ↓ j. В результате останется 33 (для русского языка) варианта для ключевого слова, из которых можно выбрать наиболее предпочтительный вариант (если ключевое слово является осмысленным).
Этот метод будет эффективным для небольших значений M, поскольку для хороших сближений индексов совпадения требуются тексты достаточно большой длины.

