 2015-06-05
2015-06-05 1777
1777Понятие "нормальный алгоритм" ввел в 1947 г. советский ученый А.А. Марков в качестве одного из уточнений представления об алгоритме. Он положил, что нормальный алгоритм, являясь алгоритмом в некотором алфавите VT, порождает в нем некоторый детерминированный процесс переработки только одного слова Ро и только в одном алфавите. Словами Рi в алгоритме Маркова могут быть арифметические, алгебраические или логические выражения.
Нормальный алгоритм Маркова есть указание использовать упорядоченный список правил подстановки: αi⇒bi, где ai и bi — некоторые слова в алфавите VT.
Множество правил и порядок их использования позволяют выполнять преобразования исходного слова Ро в заключительное слово Q, т.е. Ро→P1→P2→…→Pi→...→Q.
Для организации последовательного и упорядоченного просмотра правил последние должны быть индексированы i∈{1, 2, 3,...}.
Если слово Рi есть цепочка вида (g1aig2) в алфавите Vт, где g1 и g2 – слова в этом же алфавите и среди множества правил первым в упорядоченном списке есть правило ai⇒bi, то нужно выполнить подстановку (g1aig2)⇒(g1bi g2).
Суть упорядоченного использования правил состоит в том, что каждое переработанное слово вновь поступает в «начало» алгоритма и вновь проверяется на подстановку правил в соответствии с протоколом.
Среди множества правил выделяют заключительное αi→•bi, результатом подстановки которого формируется слово Q и дается указание об окончании работы алгоритма.
Процесс может оборваться на некотором слове Рi, для которого нет соответствующего правила. Тогда это слово направляется в «тупик».
Для того чтобы построить модель алгоритма, необходимо выделить упорядоченную последовательность левых частей правил подстановки, так называемых распознавателей вхождения слов αi в слово Pi, и множество соответствующих операторов подстановки слова bi в слово Pi+1.
На схеме алгоритма эти блоки обозначены так: • распознаватели вхождения - PBi; • операторы подстановки – ОПi:
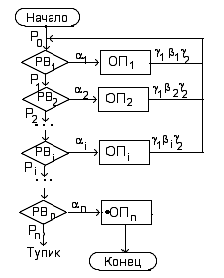
Распознаватели вхождения соединяются последовательно в соответствии с заданной последовательностью правил. Второй выход распознавателя вхождения при обнаружении αi в слове Рi передает информацию о слове Pi=g1aig2 в ОПi, где выполняется соответствующая замена слова αi на слово bi, т.е. g1aig2⇒g1big2=Pi+1.
Оператор подстановки направляет слово Pi+1 в «начало» алгоритма, если применена простая подстановка, и в «конец» алгоритма, если применена заключительная подстановка.
Пример. Преобразовать цифры десятичного числа в унарный код.
Если Ро=#X1Х2Х3...#, где X1,Х2,Х3,… - цифры, то Q=#|x1#|x2#|x3#..., где |xi – означает xi «палочек» унарного кода. Алфавит VT для преобразования цифры в код содержит символы Vт ={X, #, |, (}. Ниже приведена схема этого алгоритма:
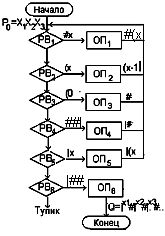
Протокол:
1) # X →#(X, 4) ##|→#|,
2) (X →(X-1|, 5) |X →|(X,
3) (0 → #, 6) |## →•|#.
Пусть x=234. Тогда
Р0=# 234##⇒#(234##⇒#(1|34##⇒#(0||34##⇒# #||34##⇒ #||34##⇒
#||(34##⇒#||(2|4##⇒#||(1||4##⇒#||(0
4##⇒#||##
4##⇒ #||#
(4##⇒#||#
(3|#|⇒#||#
(2||##⇒#||#
(1
##⇒ #||#
(0
|##⇒#||#
##
|##⇒#||#
#
|##⇒#||#
#•|##=#||#
#
Q.

