 2015-06-05
2015-06-05 453
453Кластерный анализ представляет собой метод деления статистической совокупности на части (группы, классы, кластеры) одновременно по всем наиболее существенным признакам.
В отличие от метода группировок, где на основе предварительного теоретического анализа априорно выделяются качественно своеобразные группы, определяются для них (групп) наиболее существенные черты (признаки), по которым производится классификация, кластерный анализ позволяет вначале по определенным количественным критериям выделить группы по комплексу признаков, а затем теоретически обосновать качественное своеобразие выделенных частей совокупности.
Наиболее существенным с методологической точки зрения при кластерном анализе является следующее:
а) образование единой меры, охватывающей все признаки;
б) чисто количественное определение границ групп.
Эти подходы находят отражение в следующем алгоритме классификации:
1. Пусть имеется 1, 2,..., j,..,m объектов, каждый из которых характеризуется 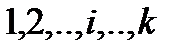 признаками. Тогда значение
признаками. Тогда значение 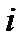 -го признака по
-го признака по 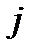 -му объекту можно записать как
-му объекту можно записать как 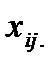 Ставится задача провести классификацию единиц одновременно по всем
Ставится задача провести классификацию единиц одновременно по всем 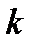 признакам.
признакам.
2. Поскольку каждый из признаков имеет свою размерность и единицу измерения, признаки следует привести в сопоставимый вид, что может быть сделано через нормированное отклонение 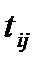 .
.
С этой целью следует:
· найти 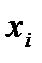 — среднее значение по каждому из признаков;
— среднее значение по каждому из признаков;
• найти 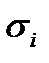 — среднее квадратическое отклонение по каждому из к признаков;
— среднее квадратическое отклонение по каждому из к признаков;
• пронормировать 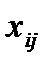 как
как
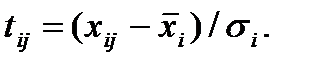
Осуществив переход от к 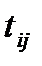 , получим единицы, свободные от содержания, имеющие с высокой степенью надежности границы в пределах ± З
, получим единицы, свободные от содержания, имеющие с высокой степенью надежности границы в пределах ± З  . С нормированными отклонениями можно проводить любые алгебраические операции, чего нельзя было делать с .
. С нормированными отклонениями можно проводить любые алгебраические операции, чего нельзя было делать с .
3. Выбирается функция состояния между объектами (единицами наблюдения). В качестве таковой может выступать:
• евклидово расстояние
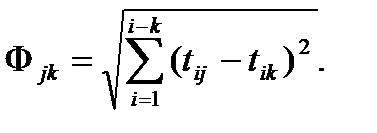
Согласно этой формуле вначале следует найти расстояние между двумя объектами но одному признаку (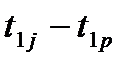 ), затем по другому (
), затем по другому (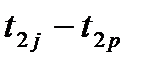 ) и т.д. Полученные разности возводят в квадрат и суммируют, из полученной суммы извлекают квадратный корень;
) и т.д. Полученные разности возводят в квадрат и суммируют, из полученной суммы извлекают квадратный корень;
• 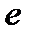 -норма для
-норма для 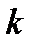 -го признака
-го признака 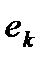 . Эту функцию наиболее часто используют, однако для определения расстояния между объектами наблюдения можно применять и другие методы. Важно учесть тот факт, что при расчете функции расстояния по любому из методов признакам может быть придан разный вес (м). Тогда функция расстояния, вычисленная, например, как евклидово расстояние, будет иметь вид:
. Эту функцию наиболее часто используют, однако для определения расстояния между объектами наблюдения можно применять и другие методы. Важно учесть тот факт, что при расчете функции расстояния по любому из методов признакам может быть придан разный вес (м). Тогда функция расстояния, вычисленная, например, как евклидово расстояние, будет иметь вид:
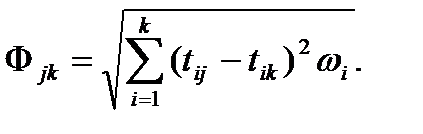
Определение веса (весового коэффициента 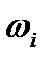 ) для каждого из признаков можно осуществлять на основе предварительного корреляционно-регрессионного или факторного анализа, экспертных оценок и других методов.
) для каждого из признаков можно осуществлять на основе предварительного корреляционно-регрессионного или факторного анализа, экспертных оценок и других методов.
4. Если число классов (кластеров) известно заранее, то устанавливаются типичные их представители, то есть определяются значения признаков по типичным представителям.
Если число кластеров заранее не задано и неизвестны их типичные представители, то их число принимаем условно равным С. Каждый из объектов следует отнести к тому из С-классов, с которым он имеет минимальную (по сравнению с другими классами) величину функции близости (расстояния).
Так как во втором случае число С неизвестно, оно подбирается методом перебора. Этот метод включает:
• определение функции расстояния каждого объекта с каждым (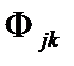 );
);
• установление порогового значения функции расстояния (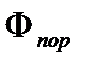 );
);
• объединение объектов в один кластер, когда расстояние между ними меньше, чем пороговое. В результате объединения получается некоторое число кластеров, но часть объектов может остаться вне кластеров;
• нахождение центров тяжести по сформированным кластерам.
• определение функции близости между центрами тяжести образованных кластеров, между центрами тяжести и значением признаков по отдельным объектам, между необъединёнными объектами. Принцип последующего объединения остается прежним — объединение проводится при значении функции расстояния меньшем, чем пороговое значение. Процесс объединения завершается, когда все значения функции расстояния будут больше, чем пороговое значение. Классификацию на основе перебора можно осуществить и без установления порогового значения. По такому алгоритму на этом шаге итерации объединяются в один кластер два (несколько) объекта, имеющие минимальную величину функции расстояния. На втором шаге находится центр тяжести по образованному кластеру и вновь определяются значения функции расстояния, объединяются объекты (кластеры) с минимальным значением функции расстояния. На третьем и последующих шагах процесс объединения продолжается до тех пор, пока все объекты не будут объединены в кластер.
На основе кластерного анализа может быть проведена классификация как объектов, так и признаков. В качестве функции расстояния в этом случае используется величина arccos 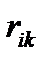 , где
, где 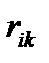 — коэффициент парной корреляции между признаками
— коэффициент парной корреляции между признаками 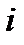 и
и 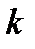 . При
. При 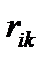 =0 значение функции равно
=0 значение функции равно 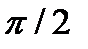 , а при = 1 — нулю. Процесс осреднения признаков может быть осуществлен по любому из описанных выше способов.
, а при = 1 — нулю. Процесс осреднения признаков может быть осуществлен по любому из описанных выше способов.








