 2015-06-05
2015-06-05 1228
1228К важнейшим статистическим характеристикам количественных данных относятся средние и показатели вариабельности (разброса). В настоящее время имеются разнообразные программы анализа данных, универсальные и специализированные. Первые называют также пакетами статистических программ(ПСП); они содержат большое число разнообразных процедур, каждая из которых предназначена для реализации определенного класса методов (описательная статистика, регрессионный, кластерный, факторный и другие виды анализа). Эти пакеты позволяют проводить комплексный статистический анализ, начиная от управления данными и расчета выборочных характеристик исходных признаков и заканчивая использованием разнообразных «тонких» методов, и рекомендуются для выполнения большинства работ по анализу данных в юриспруденции.
Популярным среди специалистов пакетом является SPSS (Statistical Package for the Social Sciences) – комплекс программ анализа данных общественных наук. Система SPSS развивается, начиная с 1975 года, и в настоящее время в продаже в России имеется версия 18.0 этого пакета, однако уже версия базового модуля SPSS Base 8.0 для Windows 95, вышедшая в 1997 году, практически полностью покрывает потребности в анализе данных в юриспруденции.
Для системы SPSS, являющейся «стандартом де факто» для специалистов, работающих в государственных и региональных органах статистики, имеются руководства по эксплуатации и применению на русском языке, поставляемые фирмой СПСС Русь вместе с пакетом SPSS Base для Windows; наряду с этими пособиями рекомендуется также книга: Бююль А., Цёфель П. SPSS: Искусство обработки информации. Анализ статистических данных и восстановление скрытых закономерностей. СПб.: ООО «ДиаСофтЮП», первое издание которой вышло в 2002 году.
Из множества аналитических процедур, предусмотренных в пакете SPSS Base, основными в юриспруденции являются описательные статистики и критерии сравнения средних.
Описательные статистики являются первым шагом в изучении набора данных. Эта процедура реализует:
· подсчет частот и процентов для числовых и строковых переменных;
· расчет накопленных процентов для количественных переменных и переменных с упорядоченными категориями;
· расчет робастных (устойчивых) статистик (медиана, квартили, процентили) для количественных переменных, которые не обязательно подчиняются нормальному распределению;
· определение статистик типа среднего и стандартного отклонения для переменных с нормальным или симметричным распределением;
· построение столбиковых диаграмм для представления переменных с неупорядоченными и упорядоченными категориями;
· построение гистограмм для представления количественных переменных.
Такие же возможности имеются и в процедуре дескриптивные статистики. Кроме того, в этой процедуре можно также вычислить z -статистики (результат преобразования исходных данных к нормированному виду).
Приведем пример. Имеется набор данных по показателю «число зарегистрированных преступлений на 100 тыс. человек населения» в федеральных округах РФ за 1990 и 2009 гг. – табл. 2.
Таблица 2
Число зарегистрированных преступлений на 100 тыс. человек населения
| Федеральный округ | 1990 г. | 2009 г. |
| ЦФО СЗФО ЮФО ПФО УФО СФО ДФО |
С помощью процедуры «частоты» для этих данных рассчитаем следующие статистические характеристики – табл. 3:
среднее арифметические невзвешенное (Mean);
медиану (Median);
среднее квадратическое отклонение (Std. Deviation);
минимальное значение (Minimum);
максимальное значение (Maximum).
В табл. 3 приведены также размах (разность между максимальным и минимальным значениями) и относительная характеристика вариабельности – коэффициент вариации, выраженный в процентах.
Таблица 3
Число зарегистрированных преступлений на 100 тыс. человек населения
(выборка – федеральные округа РФ)
| Статистика | 1990 г. | 2009 г. |
| N | ||
| Mean | 1288,00 (РФ: 1243) | 2148,43 (РФ: 2110) |
| Median | 1305,00 | 2118,00 |
| Std. Deviation | 267,195 | 479,047 |
| Minimum | ||
| Maximum | ||
| Размах | 1685 – 882 = 803 | 2640 – 1355 = 1285 |
| Коэф. вариации | 20,7% | 22,3% |
Видно, что изучаемый показатель характеризуется значительной пространственной и временной изменчивостью – величина коэффициента вариации по выборке федеральных округов превышает 20%, а средние значения показателя по РФ в 1990 и 2009 гг. – 1288 и 2148 на 100 тыс. человек населения – заметно отличаются.
Наглядно это видно из диаграмм последовательности, построенных в графическом редакторе пакета SPSS Base 11.0 – рис. 1.
| а | б |
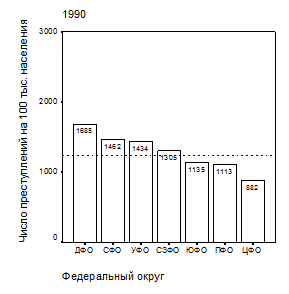 | 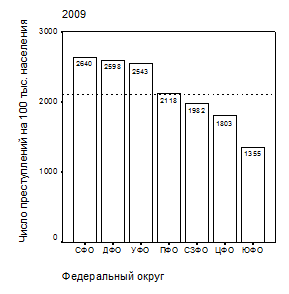 |
| Рис. 1. Распределение зарегистрированных преступлений по федеральным округам РФ (на 100 тыс. населения): а – 1990 г.; б – 2009 г. Пунктир – уровень РФ |

