 2015-06-26
2015-06-26 7070
7070Современное программное обеспечение ИС очень многообразно. ИС могут иметь функциональные подсистемы, разнесенные территориально по подразделениям и филиалам компании и имеющие собственную архитектуру и конфигурацию, программно-аппаратные средства, систему управления и персонал. Активно работающие компании не испытывают недостатка в данных. Данные находятся везде – в рабочих файлах персональных компьютеров, базах данных, видео и графических презентациях, бумажных и электронных документах. Вся информация, которую использует менеджер в повседневной деятельности и в процессе принятия решений, может быть условно разделена на три категории: формализованная, частично формализованная и неформализованная. В зависимости от степени формализации определяются и типы решений – структурированные, частично структурированные и неструктурированные.
Компьютер обрабатывает данные, представленные в формализованном виде – в виде чисел. Формализация данных является важнейшей составляющей работы информационных систем. Примером формализованных данных является представление результатов деятельности компании в виде наборов числовых таблиц: финансовые отчеты, баланс, денежные транзакции, платежи, оперативные сводки о выполнении суточных заданий, заказы, накладные и т. д. Действия с формализованными данными легче автоматизируются и могут проходить практически без участия человека. При заполнении матриц используется метод сценариев, строящихся по принципу "что, если…?" с помощью систем поддержки принятия решения (Decision Support System – DSS).
Значительная часть данных, особенно на верхнем уровне управления, бывает неформализованной – политические новости, сведения о партнерах и конкурентах, информация с фондовых и валютных бирж, сводные неформальные отчеты по периодам, деловая переписка, протоколы встреч, семинаров, научные публикации и обзоры, гипертексты в Интернете. Такие данные наиболее трудно формализуемы, но их анализ является обязательной составляющей деятельности высшего руководителя. В этом случае основная тяжесть в принятии решения и ответственность за его результаты лежит на руководителе – здесь огромную роль играют его знания, деловой опыт, компетенция и интуиция. Компьютерные, информационные экспертные системы (Expert System – ES) только дополняют эти качества.
Если данные являются недостаточно структурированными и фрагментированными среди разнообразных платформ, операционных систем, различных СУБД и приложений, то особенно важным процессом является концентрация по некоторым согласованным правилам этих данных в массивы, называемые метаданными (Metadata). Решения для управления метаданными предоставляют расширенные возможности доступа к массивам структурированных данных вместе с отображением их взаимоотношений с другими массивами информации. Использование специальных хранилищ – репозиториев (Repository) – также может рационализовать или придать смысл этим данным за счет идентификации и сравнения.
Работа с неформализованными данными вызывает значительные трудности. Эти структуры данных, разбитые на категории, довольно сложно поддерживать с помощью репозитория. Особенно это касается систем управления смыслом и содержанием (Content Management Systems – CMS), а также документацией. Специализированные репозитории и поисковые машины предоставляют только отдельные решения, и ни одно из них не покрывает весь спектр данных. Тем не менее, для решений на базе репозиториев существует возможность объединения как формализованных, так и неформализованных метаданных, что может быть достигнуто путем разработки соответствующих интерфейсов к этим новым технологиям. Подобный репозиторий станет центральным каналом доступа ко всем корпоративным массивам данных, идентифицируя взаимоотношения между данными, а также то, насколько сотрудники, заказчики и партнеры их используют.
Не все необходимые данные присутствуют в ИС в явном виде. Полезную информацию приходится искать среди большого количества дополнительных данных, и этот процесс называется извлечением данных (Data Mining – DM).
Полезная информация может быть спрятана очень глубоко; ИС извлекает правдоподобные данные, но они могут не отражать ее суть, может возникнуть опасность получения смещенных оценок (Biased Estimator), когда выявляется не совсем тот фактор, который влиял на исследуемый объект или систему. Информация практически всегда бывает размыта. Реальную информацию в такой ситуации извлечь трудно, и это может привести к ошибочным оценкам и прогнозам.
Пользователи могут получать полноценную отдачу от информации только в том случае, если эта информация точна, полна, из нее несложно извлекать знания. Информация из хранилищ данных может быть объединена с информацией из неструктурированных источников, с последующим предоставлением доступа к ней различным группам пользователей, причем каждая из подобных групп может иметь свои ожидания относительно того, каким образом им должна быть предоставлена информация.
Знания имеют небольшую ценность, если они не являются руководством к действию или не намечаются к использованию в бизнес-процессах. Пользователи нуждаются в таком представлении информации, которое бы соответствовало их уникальным бизнес-процессам. На рынке предлагается много программных продуктов для решения разнообразных общих и частных проблем. Среди них:
- системы генерации отчетов для формального представления информации (например, программный продукт Crystal Reports компании Crystal Decisions, предназначенный для создания корпоративной отчетности);
- аналитические системы для сложного динамического анализа данных;
- системы генерации персональных запросов, анализа и создания отчетов для индивидуальных пользователей, имеющих разнообразные потребности по представлению и анализу информации;
- решения по разработке КИС-приложений (Enterprise Information System Applications – EISA), предназначенные для создания инструментальных панелей руководителя и аналитических приложений для добычи данных.
В самом общем виде задачи руководителя можно свести к пяти ключевым вопросам: где мы находимся? чего мы хотим достичь? как мы туда попадем? сколько времени и ресурсов на это потребуется? сколько это будет стоить?
Для сложных систем характерно то, что управлять ими приходится, как правило, в условиях неполной информации, отсутствия знания закономерностей функционирования и постоянного изменения внешних факторов. Поэтому процессы управления и принятия решений имеют итерационный характер. После принятия решения и применения управляющего воздействия необходимо вновь оценить состояние, в котором находится система, и решить вопрос о том, правильно ли мы движемся по намеченному пути. Если отклонения нас не удовлетворяют, то необходимо переопределить наборы данных, скорректировать решение и "перезапустить" процесс управления.
Современные ИС при поиске ответов на поставленные вопросы позволяют аналитику формулировать и решать задачи нижеследующих классов:
- Аналитические – вычисление заданных показателей и статистических характеристик бизнес-деятельности на основе ретроспективной информации из баз данных.
- Визуализация данных – наглядное графическое и табличное представление имеющейся информации.
- Извлечение (добыча) знаний (Data Mining) – определение взаимосвязей и взаимозависимостей бизнес-процессов на основе существующей информации. К данному классу можно отнести задачи проверки статистических гипотез, кластеризации, нахождения ассоциаций и временных шаблонов. Например, путем анализа экономических и финансовых показателей деятельности компаний, которые затем обанкротились, банк может выявить некоторые стереотипы, которые можно будет учесть при оценке степени риска кредитования.
- Имитационные – проведение на ЭВМ экспериментов с формализованными (математическими) моделями, описывающими поведение сложных систем в течение заданного или формируемого интервала времени. Задачи этого класса применяются для анализа возможных последствий принятия того или иного управленческого решения (анализ "что, если?...").
- Синтез управления – используется для определения допустимых управляющих воздействий, обеспечивающих достижение заданной цели. Задачи этого типа применяются для оценки достижимости намеченных целей, определения множества возможных управляющих воздействий, приводящих к нужному результату.
- Оптимизационные – основаны на интеграции имитационных, управленческих, оптимизационных и статистических методов моделирования и прогнозирования. Вместе с постановкой задачи синтеза управления позволяют выбрать на множестве возможных управлений те из них, которые обеспечивают наиболее эффективное (с точки зрения определенного критерия) продвижение к поставленной цели.
В настоящее время существуют определенные категории ИС (или соответствующие модули интегрированных ИС), которые обслуживают каждый организационный уровень и помогают успешно решать указанные выше классы задач с обработкой соответствующего типа данных (рис. 3).
Современная компания с разветвленным бизнесом, как правило, имеет:
- системы поддержки деятельности руководителя (Executive Support Systems – ESS) на стратегическом уровне;
- управляющие информационные системы (Management Information Systems – MIS) и системы поддержки принятия решений (Decision Support Systems – DSS) на среднем управленческом уровне;
- рабочие системы знания (Knowledge Work System – KWS) и системы автоматизации делопроизводства (Office Automation Systems – OAS) на уровне знаний;
- системы диалоговой обработки транзакций (Transaction Processing Systems – TPS) на эксплуатационном уровне.
Системы диалоговой обработки транзакций (TPS) – базовые системы, обслуживающие исполнительский (эксплуатационный) уровень организации. Это компьютеризированная система для автоматического выполнения большого числа транзакций (Transactions), составляющих стандартный бизнес-процесс этого уровня. Примеры – коммерческие расчеты, заказы, регистрация продаж, заполнение стандартных форм, платежных ведомостей, отчетов. На этом уровне цели, задачи, ресурсы точно определены, их выполнение связано с минимальным риском, данные, как правило, формализованы. Правила очень жесткие, и решения всегда структурированы. Соответствие критериям и шаблонам должно быть полным. Объемы обрабатываемых данных велики, но потоки и структура данных (Data Flow and Data Structure) четко идентифицированы и легко контролируются автоматизированными средствами.
Информационные системы этого уровня не являются самостоятельными – они обычно выполняются в виде приложений, которые по тем или иным правилам интегрируются в общую корпоративную ИС.
| Типы решений: | Организационный уровень: | |||||||||||||||||
| Эксплуата- ционный | Знания | Управлен- ческий | Стратеги- ческий | |||||||||||||||
| Счета | ||||||||||||||||||
| структурированные | TPS | |||||||||||||||||
| Электронное планирование Документооборот | Повышение эффективности производства | |||||||||||||||||
| Транзакции | OAS | MIS | ||||||||||||||||
| частично структурированные | Разработка продукции | Подготовка бюджета | ||||||||||||||||
| KWS | DSS | |||||||||||||||||
| EIS | ||||||||||||||||||
| Планирование проекта | Развитие производства | |||||||||||||||||
| неструктурированны е | Подготовка и консолидация информации | ESS | ||||||||||||||||
| Новая продукция Новые рынки | ||||||||||||||||||
| TPS - системы выполнения транзакций; OAS – Системы автоматизации офиса; KWS – Системы работы знания; MIS – Управляющие информационные системы; DSS – Системы поддержки принятия решений (СППР); ESS – Исполнительные системы; EIS – экспертные системы. | ||||||||||||||||||
Рис. 3. Категории ИС, поддерживающие различные типы решений
Типичный пример: интеграция модулей "1С: Бухгалтерия", "LanDocs", "LanStaff" и пр. в систему диалоговой обработки данных. Технология такого встраивания хорошо отработана, есть достаточно много фирм (в их числе и "ЛАНИТ-ТЕРКОМ" в Санкт-Петербурге), которые быстро и качественно выполнят эту работу.
Рабочие системы знания (KWS) и автоматизации делопроизводства (OAS) обслуживают информационные потребности на тактическом и функционально- оперативном уровнях управления организацией.
Ключевые вопросы управления знаниями:
- Как формировать и актуализировать знания?
- Как сделать знания используемыми?
- Как измерить знания?
- Как оценить людей, владеющих знаниями?
- Как мотивировать владельцев знаний?
- Как заставить сотрудников делиться знаниями?
- Как выявить скрытые знания и поставить их служить бизнесу?
Рабочие системы знания используют разнородные, многопрофильные данные различной степени формализации. Их цель – аккумулировать знания и опыт, сформировать "рабочее" знание для сопровождения основной деятельности и для получения дополнительных оригинальных знаний, необходимых для выполнения, например, перепроектированных бизнес-процессов или для формирования подхода при оценке нестандартной ситуации, а также находить новые области применения для уже использованных данных. Они способствуют систематизации данных и созданию новых знаний. Задача руководителя подразделения KWS – гарантировать, чтобы новые знания и технический опыт были востребованы и должным образом интегрированы в бизнес. Рабочие места KWS выполняются в виде научных или инженерных АРМов (Workbench, Workstation) и являются частью КИС. Работники знания – высококвалифицированные специалисты с широким научным и техническим кругозором и хорошей профессиональной подготовкой.
Несколько примеров известных программных продуктов по формированию и управлению корпоративными знаниями:
- продукт "Microsoft SharePoint Portal" как средство управления знаниями (www.microsoft.ru);
- продукт "Система формирования и управления знаниями Excalibur Retrieval Ware" группы компаний АСК (http://www.ask.ru);
- линейка продуктов eDOCS компании Hummingbird (www.hummingbird.ru).
Пользователи системы автоматизации делопроизводства (менеджеры среднего звена, делопроизводители, технологи, разработчики и т. д.) работают с почти формализованными данными, их функции – дополнять и контролировать работу систем TPS на эксплуатационном уровне, а также делопроизводство и документооборот, которые образуют подсистему документационного обеспечения (ДОУ) на уровне организации. Локальные и сетевые OAS имеют развитый графический интерфейс, позволяющий успешно работать сотруднику с минимальной информационной подготовкой.
Подсистемы делопроизводства обеспечивают работу с электронными версиями документов, шаблонами и реквизитами учетно-контрольных форм в соответствии с правилами и стандартами делопроизводства, принятыми в России и в организации. Подсистемы документооборота обеспечивают строго регламентированное и контролируемое движение документов внутри и вне организации на основе информационных и коммуникационных технологий. Процессы делопроизводства и документооборота являются процессами, документально отражающими и обеспечивающими управленческие процессы.
Основные задачи подсистемы ДОУ применительно к программным системам автоматизации управленческой деятельности:
- документирование – создание документов, поддерживающих и регистрирующих управленческую деятельность (подготовка, оформление, согласование и изготовление);
- разработка правил и организация документооборота – обеспечение поиска, движения, хранения и использования документов;
- систематизация архивного хранения документов – определение правил отбора, систематизации, хранения данных и информации, поиск в базах и хранилищах данных и использование для поддержки принятия управленческих решений и производственных процедур.
Функции корпоративной автоматизированной подсистемы документационного обеспечения управления:
- организация единого порядка работы с документами в подразделениях;
- подготовка, изготовление, оформление в соответствии с шаблонами, согласование, корректировка, доставка, регистрация, учет документов;
- использование унифицированных форм представления и обработки документов;
- обмен документами внутри и между структурными подразделениями организации и с внешней средой;
- своевременное обеспечение сотрудников организации полной, точной и достоверной информацией о состоянии подготовки и исполнения документов, решений и поручений руководства организации;
- проведение информационно-справочной и аналитической работы по вопросам документационного обеспечения;
- обеспечение защиты процессов документооборота и делопроизводства;
- формирование отчетов, в том числе статистических, на основании информации о документах, их местонахождении и состоянии их исполнения.
Примеры фирм и программных продуктов, реализующих подсистему ДОУ:
- компания Lotus (дочерняя компания корпорации IBM) имеет 10-летнюю историю работы на российском рынке с продуктами, реализующими ДОУ в среде Notes – многие российские партнеры Lotus создали собственные корпоративные приложения в среде Notes, которые автоматизируют сложные процессы делопроизводства и работы с документами;
- среди наиболее известных отечественных продуктов этого класса можно назвать продукты "Босс-Референт" (АйТи), семейство продуктов "Золушка" и "DIS-Assistant" (Институт развития Москвы), ЭСКАДО (Интерпроком Лан), "CompanyMedia" и "OfficeMedia" (ИнтерТраст);
- основными известными игроками российского рынка ДОУ, помимо партнеров Lotus, являются следующие компании с соответствующими продуктами: Ланит ("LanDocs"), Оптима ("Optima Workflow"), Электронные Офисные Системы ("Дело") и ряд других поставщиков.
Первые управляющие информационные системы (Management Information Systems – MIS) стали появляться в 70-х годах ХХ века с развитием вычислительной техники. Такие ИС обслуживают управленческий уровень, обеспечивая менеджеров среднего и высшего звеньев текущей информацией о выполнении основных бизнес-процессов в компании и о некоторых изменениях во внешней среде. Они обеспечивают интерактивный доступ к показателям текущей деятельности фирмы, архиву отчетов и решений, приказам, распоряжениям, протоколам совещаний, отчетным формам.
Обычно такие системы ориентированы в основном на внутреннего пользователя и обслуживают функции планирования, управления подразделениями и службами, контроля и поддержки решений на управленческом уровне. Блок-схема MIS приведена на рис. 4.
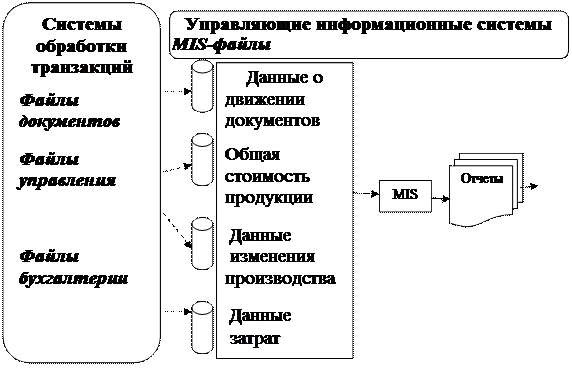
Рис. 4. Схема обработки данных и подготовки информации в MIS
Корпоративные управляющие системы:
- работают с формализованными и/или частично формализованными данными и поддерживают частично структурированные и слабоструктурированные решения в широком диапазоне на функционально-оперативном и управленческих уровнях, преобразуя формализованные данные в "MIS-файлы". Решения, поддержанные MIS, обязательны для исполнения на эксплуатационном уровне, пополняют "копилку" решений в KWS и транслируются посредством OAS;
- ориентированы на обеспечение текущих бизнес-процессов управленческими решениями, на создание отчетов и контроль исполнения;
- задают правила формирования информационных потоков и пучков внутри информационного поля компании, информационные требования известны и устойчивы;
- имеют небольшие аналитические возможности, ограниченные рамками текущей деятельности на уровне подразделений;
- недостаточно гибки, но имеют возможности для адаптации в любом подразделении;
- помогают в принятии оперативных решений, используя прошлые и настоящие данные, при этом используется больше внутренних данных, чем внешних.
MIS, как правило, является одним из основных модулей общей корпоративной ИС; для его разработки, внедрения и интеграции требуется тщательный анализ процессов и идентификация параметров информационного поля организации. В российских компаниях MIS обычно развивается на базе систем TPS и OAS, с которых часто начинается автоматизация рутинных процедур и процессов. Вследствие этого MIS постепенно превращается в автоматизированную информационную систему управления предприятием (не путать с АСУП – Автоматизированной Системой Управления Производством).
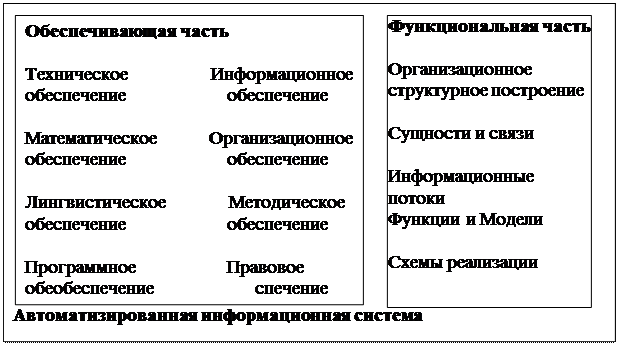
Рис. 5. Состав автоматизированной ИС управления (MIS)
Пользователями MIS являются практически все менеджеры компании. Выходные данные – периодические результаты деятельности в виде сводок, резюме, отчетов, докладных записок, служебные расследования. Менеджеры обладают доступом различной степени, т. к. часть информации может быть конфиденциальной. MIS имеет функциональную и обеспечивающую части (рис. 5).
В 1980-е годы американские и японские компании начали развивать ИС, которые разительно отличались от MIS. Эти системы положили начало процессу "интеллектуализации" ИС. Новые системы были меньшими, интерактивными, и их целью было помочь конечным пользователям работать со всеми типами данных, проводить аналитические исследования, строить модели и разыгрывать сценарии для решения слабоструктурированных и вообще неструктурированных проблем в инновационных проектах. Системы, предоставляющие такие возможности, называются системами поддержки принятия решений – СППР (Decision Support System – DSS). Основные компоненты системы поддержки принятия решения представлены на рис. 6.
В середине 1980-х такие системы стали использоваться в текущей деятельности крупных компаний и корпораций. В настоящее время DSS является обязательной частью корпоративных ИС (КИС) (рис. 7).
Приведем основные характеристики систем поддержки принятия решения:
- предлагают гибкость использования, адаптируемость и быструю реакцию;
- допускают управление входом и выходом;
- работают практически без участия профессиональных программистов;
- обеспечивают информационную поддержку для решений проблем, которые не могут быть определены заранее;
- применяют сложный многомерный и многофакторный анализ и инструментальные средства моделирования.
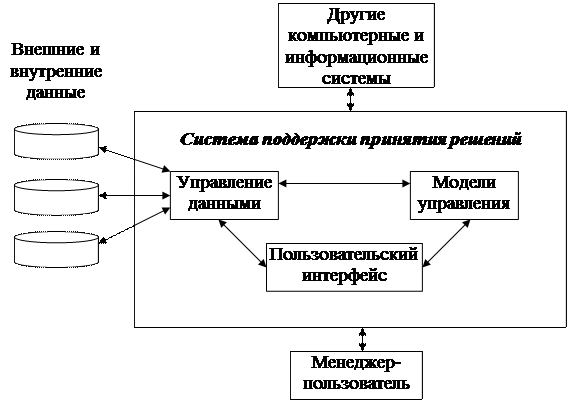
Рис. 6. Основные компоненты системы поддержки принятия решения
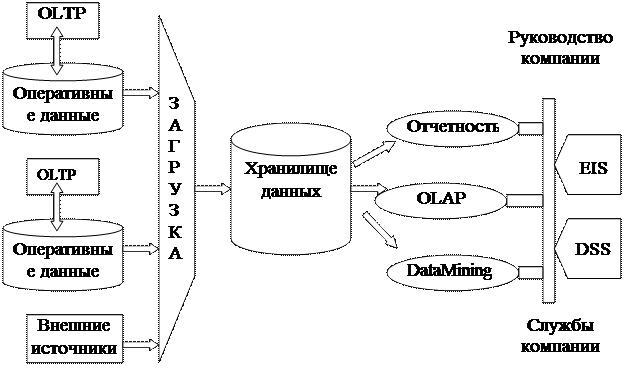
Рис. 7. Система поддержки принятия решения как составная часть КИС
Данные, приведенные в таблице 3, показывают различия между системами MIS и DSS.
Таблица 3.
Различия между системами MIS и DSS
| Параметр | MIS | DSS |
| Концепция | Обеспечивает формализованные и частично формализованные данные для принятия структурированных решений | Обеспечивает интегрированные инструментальные средства, многомерные разнородные данные, динамические модели и язык интерпретации |
| Системный анализ | Выделяет информационные требования в соответствии с установленными правилами | Формирует порядок применения инструментальных средств и динамических правил в процессе работы |
| Проект | Поставляет информацию, основанную на утвержденных требованиях | Итеративный процесс добавления новых данных и информации, вытекающий из динамики среды |
| Источник данных | Внутренняя и частично внешняя среда | Внешняя и внутренняя среда |
| Пользователи | Менеджеры эксплуатационного и управленческого уровней | Высшее руководство, менеджеры департаментов, ИТ-служб, управленческого уровня, аналитики |
Хорошо разработанные DSS применяются на многих уровнях предприятия. Руководители компании и ведущие менеджеры могут пользоваться финансовыми модулями DSS, чтобы предсказать эффективность использования активов компании при изменении деловой активности или экономической ситуации в стране. Менеджерам среднего звена та же система может быть полезной для оценки перспективности краткосрочных инвестиций по выполняемым проектам. Для руководителей проектов это инструмент для финансового планирования и распределения средств по планируемым закупкам.
DSS состоят из трех компонент: программного ядра и хранилища данных, аналитических средств обработки, анализа и представления информации, телекоммуникационных устройств.
Хранилище данных предоставляет единую среду хранения корпоративных данных, организованных в структуры и оптимизированных для выполнения аналитических операций.
Аналитические средства позволяют конечному пользователю, не имеющему специальных знаний в области информационных технологий, осуществлять навигацию и представление данных в терминах предметной области. Для пользователей различной квалификации DSS располагают различными типами интерфейсов доступа к своим сервисам.
Аналитические системы (рис. 8) позволяют решать три основных задачи: анализ разнородной многомерной информации разной степени формализованности в реальном времени, последующий интеллектуальный анализ данных с построением моделей развития деловой ситуации и ведение отчетности. Процесс принятия делового решения отличается от аналогичного процесса в научной или социальной сфере тем, что преобразование рабочей гипотезы в решение осложняется двумя объективно существующими проблемами.
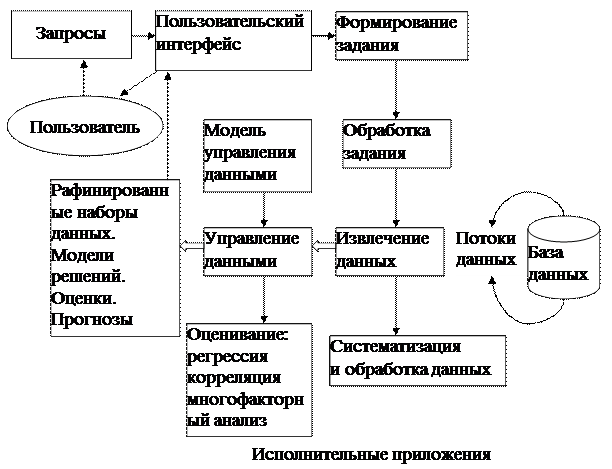
Рис. 8. Аналитическая ИС
Первая из них состоит в том, что накопление личного опыта в ходе повседневной деятельности у бизнесменов отстает от динамичного изменения экономической ситуации, что особенно характерно для современной России.
Вторая проблема заключается в том, что в предпринимательской деятельности в условиях свободного рынка практически отсутствует возможность проведения целенаправленных экспериментов, которые позволяют проверять правильность гипотезы на практике. Следовательно, применительно к бизнес-деятельности процесс принятия решения претерпевает разрыв как минимум в двух точках: на этапе выдвижения гипотез и на этапе экспериментальной верификации моделей. Ликвидировать эти разрывы призвано активно развивающееся направление информационных технологий – технология многомерного анализа данных (On-Line Analytical Processing – OLAP). Коротко эту технологию можно охарактеризовать следующими словами: Быстрый Анализ Разделяемой Многомерной Информации (Fast Analysis of Shared Multidimensional Information – FASMI).
Ценность технологии многомерного анализа данных для бизнеса определяется тем, что она позволяет извлекать из несистематизированных структурированных (как правило, в виде таблиц) данных информацию и знания, использование которых в принятии и реализации решений позволяет создавать дополнительную стоимость в компании по сравнению со стоимостью, создаваемой в отсутствие такой информации.
Исторически сложилось так, что сегодня термин "OLAP" подразумевает не только многомерный взгляд на данные со стороны конечного пользователя, но и многомерное представление данных в целевой БД. Именно с этим связано появление в качестве самостоятельных терминов "Реляционный OLAP" (ROLAP) и "Многомерный OLAP" (MOLAP).
OLAP-сервис представляет собой инструмент для анализа больших объемов данных в режиме реального времени. Взаимодействуя с OLAP- системой, пользователь сможет осуществлять гибкий просмотр информации, получать произвольные срезы данных и выполнять аналитические операции детализации, свертки, сквозного распределения, сравнения во времени одновременно по многим параметрам. Вся работа с OLAP-системой происходит в терминах предметной области и позволяет строить статистически обоснованные модели деловой ситуации.
Программные средства OLAP это инструмент оперативного анализа данных, содержащихся в хранилище. Главной особенностью является то, что эти средства ориентированы на использование не специалистом в области информационных технологий, не экспертом-статистиком, а профессионалом в прикладной области управления – менеджером отдела, департамента, управления, и, наконец, директором. Имея в своем распоряжении гибкие механизмы манипулирования данными и визуального отображения, менеджер сначала рассматривает с разных сторон данные, которые могут быть (а могут и не быть) связаны с решаемой проблемой. Далее он сопоставляет различные показатели бизнеса между собой, стараясь выявить скрытые взаимосвязи; может рассмотреть данные более пристально, детализировав их, например, разложив на составляющие по времени, по регионам или по клиентам, или, наоборот, еще более обобщить представление информации, чтобы убрать отвлекающие подробности. После этого с помощью модуля статистического оценивания и имитационного моделирования строится несколько вариантов развития событий, и из них выбирается наиболее приемлемый вариант.
У управляющего компанией, например, может зародиться гипотеза о том, что разброс роста активов в различных филиалах компании зависит от соотношения в них специалистов с техническим и экономическим образованием. Для проверки этой гипотезы, менеджер запрашивает из хранилища и отображает на графике интересующее его соотношение. Для тех филиалов, у которых за текущий квартал рост активов снизился по сравнению с прошлым годом более чем на 10%, и для тех, у которых повысился более чем на 25%. Если полученные результаты ощутимо распадутся на две соответствующие группы, то это должно стать стимулом для дальнейшей проверки выдвинутой гипотезы.
OLAP применим везде, OLAP это инструмент эффективного анализа и генерации отчетов. В качестве примера применения OLAP-технологии рассмотрим исследование результатов процесса продаж.
Ключевые вопросы "Сколько продано?", "На какую сумму продано?" расширяются по мере усложнения бизнеса и накопления исторических данных до некоторого множества факторов, или разрезов: "..в Санкт-Петербурге, в Москве, на Урале, в Сибири…", "..в прошлом квартале, по сравнению с нынешним", "..от поставщика А по сравнению с поставщиком Б…" и т. д. Ответы на подобные вопросы необходимы для принятия управленческих решений: об изменении ассортимента, цен; о закрытии и открытии магазинов, филиалов; расторжении и подписании договоров с дилерами; проведения или прекращения рекламных кампаний и т. д.
Если попытаться выделить основные цифры (факты) и разрезы (аргументы измерений), которыми манипулирует аналитик, стараясь расширить или оптимизировать бизнес компании, то получится таблица, подходящая для анализа продаж как некий шаблон, требующий соответствующей корректировки для каждого конкретного предприятия. Поля таблицы: Время, Категория товара, Товар, Регион, Продавец, Покупатель, Сумма, Количество.
Время. Как правило, это несколько периодов: Год, Квартал, Месяц, Декада, Неделя, День. Многие OLAP-инструменты автоматически вычисляют старшие периоды из даты и вычисляют итоги по ним.
Категория товара. Категорий может быть несколько, они отличаются для каждого вида бизнеса: Сорт, Модель, Вид упаковки и пр. Если продается только один товар или ассортимент очень невелик, то категория не нужна.
Товар. Иногда применятся название товара (или услуги), его код или артикул. В тех случаях, когда ассортимент очень велик (а некоторые предприятия имеют десятки тысяч позиций в своем прайс-листе), первоначальный анализ по всем видам товаров может не проводиться, а обобщаться до некоторых согласованных категорий.
Регион. В зависимости от глобальности бизнеса можно иметь в виду Континент, Группа стран, Страна, Территория, Город, Район, Улица, Часть улицы. Конечно, если есть только одна торговая точка, то это измерение отсутствует.
Продавец. Это измерение тоже зависит от структуры и масштабов бизнеса. Здесь может быть: Филиал, Магазин, Дилер, Менеджер по продажам. В некоторых случаях измерение отсутствует, например, когда продавец не влияет на объемы сбыта, магазин только один и так далее.
Покупатель. В некоторых случаях, например, в розничной торговле, покупатель обезличен, и измерение отсутствует, в других случаях информация о покупателе есть, и она важна для продаж. Это измерение может содержать название фирмы-покупателя или множество группировок и характеристик клиентов: Отрасль, Группа предприятий, Владелец и так далее.
Важный вопрос – наличие данных. Если они есть в каком-либо виде (Excel- или Access-таблица, данные из базы учетной системы, в виде структурированных отчетов филиалов), ИТ специалист сможет передать их OLAP-системе напрямую или с промежуточным преобразованием. Для этого OLAP-системы имеют специальные инструменты конвертации данных. После настройки OLAP-системы на данные пользователь получит возможность быстро получать ответы на ключевые вопросы путем простых манипуляций мышью над OLAP-таблицей и соответствующими меню. При этом будут доступны некоторые стандартные методы анализа, логически следующие из природы OLAP-технологии.
Факторный (структурный) анализ. Анализ структуры продаж для выявления важнейших составляющих в интересующем разрезе. Для этого удобно использовать, например, диаграмму типа "Пирог" в сложных случаях, когда исследуется сразу 3 измерения – "Столбцы". Например, в магазине "Компьютерная техника" за квартал продажи компьютеров составили $100000, фототехники -$10000, расходных материалов – $4500. Вывод: оборот магазина зависит в большой степени от продажи компьютеров (на самом деле, быть может, расходные материалы необходимы для продажи компьютеров, но это уже анализ внутренних зависимостей).
Анализ динамики (регрессионный анализ – выявление трендов). Выявление тенденций, сезонных колебаний. Наглядно динамику отображает график типа "Линия". Например, объемы продаж продуктов компании Intel в течение года падали, а объемы продаж Microsoft росли. Возможно, улучшилось благосостояние среднего покупателя, или изменился имидж магазина, а с ним и состав покупателей. Требуется провести корректировку ассортимента. Другой пример: в течение 3 лет зимой снижается объем продаж видеокамер.
Анализ зависимостей (корреляционный анализ). Сравнение объемов продаж разных товаров во времени для выявления необходимого ассортимента – "корзины". Для этого также удобно использовать график типа "Линия". Например, при удалении из ассортимента принтеров в течение первых двух месяцев обнаружилось падение продаж картриджей с порошком.
Сопоставление (сравнительный анализ). Сравнение результатов продаж во времени, или за заданный период, или для заданной группы товаров. В зависимости от количества анализируемых факторов (от 1 до 3-х) используется диаграмма типа "Столбцы". Пример: сравнение результатов продаж однотипных магазинов для оценки качества работы менеджеров.
Для прогнозирования и оценки рисков применяется дисперсионный анализ (исследование распределения вероятностей и доверительных интервалов рассматриваемых показателей).
Этими видами анализа возможности OLAP не исчерпываются. Например, применяя в качестве алгоритма вычисления промежуточных и окончательных итогов функции статистического анализа – дисперсию, среднее отклонение, моды более высоких порядков, – можно получить самые изощренные виды аналитических отчетов.
OLAP-системы являются частью более общего понятия "интеллектуальные ресурсы предприятия" или "средства интеллектуального бизнес-анализа" (Business Intelligence – BI), которое включает в себя помимо традиционного OLAP-сервиса средства организации совместного использования данных и информации, возникающих в процессе работы пользователей хранилища. Технология Business Intelligence обеспечивает электронный обмен отчетными документами, разграничение прав пользователей, доступ к аналитической информации из Internet и Intranet.
Data Mining (DM) — технология поддержки процесса принятия решений, основанная на выявления скрытых закономерностей и систематических взаимосвязей между переменными внутри больших массивов информации, которые затем можно применить к новым совокупностям данных. При этом накопленные сведения автоматически обобщаются до информации, которая может быть охарактеризована как знания. Обнаружение новых знаний можно использовать для повышения эффективности бизнеса.
В связи с совершенствованием технологий записи и хранения данных на людей обрушились колоссальные потоки. Деятельность любого предприятия (коммерческого, производственного, медицинского, научного и т.д.) должна сопровождаться регистрацией и записью всей его деятельности. Многие компании годами накапливают бизнес-информацию, надеясь, что она поможет им в принятии решений.
Корпоративная база данных любого современного предприятия обычно содержит набор таблиц, хранящих записи о тех или иных фактах либо объектах (например, о товарах, их продажах, клиентах, счетах). Как правило, каждая запись в подобной таблице описывает какой-то конкретный объект или факт. Например, запись в таблице продаж отражает тот факт, что такой-то товар продан такому-то клиенту тогда-то таким-то менеджером, и по большому счету ничего, кроме этих сведений, не содержит.
Пример. C помощью средств DM менеджер по маркетингу может предлагать клиентам индивидуальные котировки акций, обновлять новости, проводить специальные кампании по продвижению и передавать другую индивидуальную информацию, которая может их заинтересовать. При этом существенно сокращаются средства на рекламу и повышаются доходы. Кроме того, процесс полностью автоматизирован, ПО моментально обнаруживает любые изменения в поведении клиента, в отличие от специальных сервисов, представленных на сегодняшний день в Web, которые требуют от пользователей заполнения различных опросных листов и анкет. Однако совокупность большого количества таких записей, накопленных за несколько лет, может стать источником дополнительной, гораздо более ценной информации, которую нельзя получить на основе одной конкретной записи, а именно — сведений о закономерностях, тенденциях или взаимозависимостях между какими-либо данными.
Пример. Сведения о том, как зависят продажи определенного товара от дня недели, времени суток, или времени года, какие категории покупателей чаще всего приобретают тот или иной товар, какая категория клиентов чаще всего вовремя не отдает предоставленный кредит, какая часть покупателей одного конкретного товара приобретают другой конкретный товар.
Подобного рода информация обычно используется при прогнозировании, стратегическом планировании, анализе рисков, и ценность ее для предприятия очень высока, поэтому процесс ее поиска и получил название Data Mining (mining по-английски означает «добыча полезных ископаемых», а поиск закономерностей в огромном наборе фактических данных действительно сродни этому).
Синонимами DM можно считать следующее:
- Обнаружение знаний в БД (Knowledge Discovery In Databases, KDD). Это процесс поиска полезных знаний в несистематизированных данных. KDD включает в себя вопросы подготовки данных, выбора информативных признаков, очистки данных, применения методов DM, а также обработки и интерпретации полученных результатов
- Интеллектуальный анализ данных (IAD). Концепция интеллектуального анализа данных определяет задачи поиска функциональных и логических закономерностей в накопленной информации, построение моделей и правил, которые объясняют найденные аномалии и/или прогнозируют развитие некоторых процессов.
Термин Data Mining обозначает не столько конкретную технологию, сколько сам процесс поиска корреляций, тенденций, взаимосвязей и закономерностей посредством различных математических и статистических алгоритмов: кластеризации, создания субвыборок, регрессионного и корреляционного анализа. Цель этого поиска — представить данные в виде, четко отражающем бизнес-процессы, а также построить модель, при помощи которой можно прогнозировать процессы, критичные для планирования бизнеса (например, динамику спроса на различные виды товаров или услуг, либо зависимость их приобретения от каких-то характеристик потребителя).
Пример. Анализ потребительской корзины, применяемый, чтобы выявить предпочтения потребителей и, соответственно, лучше удовлетворить спрос и повысить доход с клиентов. Однако характер покупательского поведения присутствует в данных неявно, и для его определения необходимо использовать именно Data Mining. И теперь можно выяснить, к примеру, что клиент, собирающийся купить товар X, будет не прочь приобрести заодно и товар Y. Эта информация ляжет в основу последующих решений: может быть, стоит располагать эти товары на витрине магазина рядом или, например, продвигать один из них, чтобы повысить продаж и обоих.
В отличие от оперативной аналитической обработки данных (OLAP) в DM задача формулировки гипотез и выявления необычных (unexpected) алгоритмов переложено с человека на компьютер. Если при статистическом анализе или при применении OLAP, обычно формулируется вопрос «Каково среднее число неоплаченных счетов заказчиками данной услуги?», то применение DM, как правило, подразумевает ответ на вопрос «Существует ли типичная категория клиентов, не оплачивающих счета?». При этом именно ответ на второй вопрос нередко обеспечивает более нетривиальный подход к маркетинговой политике и к организации работы с клиентами. Примеры заданий на такой поиск при использовании DM – Data Mining приведены в таблице 4.
Важное положение DM — нетривиальность (нестандартность и неочевидность) разыскиваемых алгоритмов (шаблонов). Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные (unexpected) регулярности в данных, составляющие, так называемые, скрытые знания (hidden knowledge). Иными словами, средства DM отличаются от инструментов статистической обработки данных и средств OLAP тем, что вместо проверки заранее предполагаемых пользователями взаимозависимостей они на основании имеющихся данных способны находить такие взаимозависимости самостоятельно и строить гипотезы об их характере.
Таблица 4.
Примеры задач использующих методы OLAP и DM – Data Mining
| OLAP | DM – Data Mining |
| Каковы средние показатели травматизма для курящих и некурящих людей? | Встречаются ли точные шаблоны в описаниях людей, подверженных повышенному травматизму? |
| Каковы средние размеры телефонных счетов существующих клиентов в сравнении со счетами бывших клиентов (отказавшихся от услуг телефонной компании)? | Имеются ли характерные портреты клиентов, которые, по всей вероятности, собираются отказаться от услуг телефонной компании? |
| Какова средняя величина ежедневных покупок по украденной и не украденной кредитной карточке? | Существуют ли стереотипные схемы покупок для случаев мошенничества с кредитными карточками? |
Применение средств DM не исключает использования статистических инструментов и OLAP-средств, поскольку результаты обработки данных с помощью последних, как правило, способствуют лучшему пониманию характера закономерностей, которые следует искать.
Применение DM оправданно при наличии достаточно большого количества данных, содержащихся в хранилищах данных (ХД). Сами ХД обычно создаются для решения задач анализа и прогнозирования, связанных с поддержкой принятия решений. Данные в ХД представляют собой пополняемый набор, единый для всего предприятия и позволяющий восстановить картину его деятельности на любой момент времени, а структура данных хранилища проектируется таким образом, чтобы выполнение запросов к нему осуществлялось максимально эффективно. Впрочем, существуют средства DM, способные выполнять поиск закономерностей, корреляций и тенденций не только в ХД, но и в OLAP-кубах, то есть в наборах предварительно обработанных статистических данных.
Эксперты считают, что в ближайшее десятилетие DM станет одним из перспективных направлений разработки ПО. За счет выявления содержательной структуры собранной информации, ее анализа в режиме реального времени данная технология станет ключевым методом разработки «индивидуальной Сети», приспособленной под конкретные нужды каждого пользователя. Области применения технологии Data Mining приведены на рис. 9.
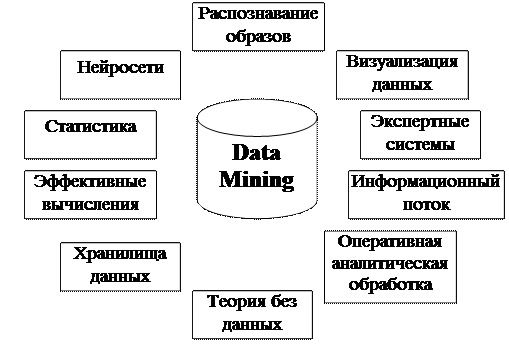
Рис. 9. Области применения технологии Data Mining
Последние версии почти всех известных статистических пакетов включают наряду с традиционными статистическими методами также элементы Data Mining. Но основное внимание в них уделяется классическим методикам – корреляционному, регрессионному, факторному анализу и другим. Недостатком систем этого класса считают требование к специальной подготовке пользователя. Также отмечают, что мощные современные статистические пакеты являются слишком "тяжеловесными" для массового применения в финансах и бизнесе.
Есть еще более серьезный принципиальный недостаток статистических пакетов, ограничивающий их применение в Data Mining. Большинство методов, входящих в состав пакетов, опираются на статистическую парадигму, в которой главными фигурантами служат усредненные характеристики выборки. А эти характеристики при исследовании реальных сложных жизненных феноменов часто являются фиктивными величинами. Это чрезвычайно важное обстоятельство следует обязательно учитывать при анализе многомерных данных.
В качестве примеров наиболее мощных и распространенных статистических пакетов можно назвать SAS (компания SAS Institute), SPSS (компания SPSS), STATGRAPHICS (компания Manugistics), STATISTICA для WINDOWS, STADIA и другие. Эти пакеты с успехом могут применять небольшие и средние предприятия, а большие многопрофильные компании могут интегрировать их в общую корпоративную сеть.
Нейронные сети и экспертные системы это большой класс систем, архитектура которых имеет аналогию с построением нервной ткани из нейронов.
Основным недостатком нейросетевой парадигмы является необходимость иметь очень большой объем обучающей выборки, хотя современные хранилища знаний относительно легко позволяют делать это. Другой существенный недостаток заключается в том, что даже натренированная нейронная сеть представляет собой черный ящик, обрабатывающий начальные условия и выдающий прогноз. Знания, зафиксированные как веса нескольких сотен межнейронных связей, совершенно не поддаются анализу и интерпретации человеком (известные попытки дать интерпретацию структуре настроенной нейросети выглядят пока неубедительно).
Примеры используемых нейросетевых систем – BrainMaker (CSS), NeuroShell (Ward Systems Group), OWL (HyperLogic).
В отличие от нейронных сетей, где прогноз формируется без участия человека, экспертные системы включают одного или нескольких специалистов высокого класса в качестве элемента.
Экспертная система имеет разветвленную сеть, позволяющую делать запросы и глубокий поиск в базах данных и хранилищах знаний. Нейронные сети работают на принципе передачи информации от одних слоев нейронов к другим, причем изменения информации, происходящие во время передачи, обусловлены заранее не оговоренными эвристическими правилами. Экспертные системы работают по заложенным в алгоритм правилам и используют параметры, вовлеченные в решение.
Ответ может быть известен заранее по результатам отзывов специалистов-экспертов; этот ответ сопоставляется с ответом системы, параметры изменяются, и проводится второй "прогон". В результате выдается экспертное заключение с вероятностной оценкой его надежности. Интерфейс допускает работу сразу нескольких пользователей.
Экспертные системы, которые являются узкоспециализированными (транспортные, медицинские, банковские, торговые, юридические и т. д.) широко применяются в бизнесе, часто работают независимо и не включаются в корпоративные информационные сети.
Системы поддержки выполнения решений (Executive Support Systems – ESS) появились в середине 1980-х годов в крупных корпорациях. ESS помогает принимать неструктурированные решения на стратегическом уровне управления компании и проводить системный анализ информации из внешней среды лучше, чем любые прикладные и специализированные ИС.
Система поставляет совокупность текущей информации – как правило, внешней: курсы акций, спрос и предложения по отрасли, политические новости, экономические обзоры, прогнозы динамики цен и выбора оптимальной структуры инвестиционного портфеля (основанные на различных эмпирических моделях динамики рынка), данные аналитического учета по предприятию из внутренних модулей MIS и DSS.
Она фильтрует, упорядочивает данные и выявляет критические параметры по заданным статистическим критериям, сокращая время и усилия для подготовки информации, необходимой для руководителя. В системах ESS используют самое "продвинутое" графическое программное обеспечение, которое может поставлять нужную графическую, аудио и видеоинформацию немедленно в офис руководителя или зал заседаний.
Системы ESS часто используют несложный статистический аппарат, но максимально учитывают сложившуюся специфику области бизнеса (профессиональный язык, системы различных индексов и пр.). На рынке имеется достаточно много программных модулей для встраивания в ESS. В настоящее время модули ESS в виде специализированных подсистем являются обязательной частью многих ERP-систем.
В отличие от других подсистем ИС (TPS, MIS, DSS), ESS не предназначены для решения какого-то определенного круга проблем. Системы этого типа работают с обобщенной неформализованной информацией и оперативно передают ее для оценки ситуаций с динамично изменяющимся набором проблем. Системы ESS используют более простой алгоритм оценивания, чем DSS, ее аналитические возможности позволяют строить относительно простые модели, которые можно сразу применять для предварительной оценки ситуации.
Пример. Изменилось налоговое законодательство или ставки таможенных пошлин – руководитель компании может быстро оценить, как это повлияет на его бизнес, и принять некоторые превентивные меры, а подсистема ESS помогает ему найти ответы на следующие вопросы:
- Какие изменения мы должны произвести в своем бизнесе, чтобы получить (вернуть) конкурентное преимущество?
- Какие новые приобретения, в том числе и в области ИТ, защитят нас от циклических колебаний в экономике?
- Что предпринимают наши конкуренты, чтобы обогнать нас, что должны сделать мы, чтобы обогнать их?
- Какие подразделения корпорации нужно закрыть, и какие акции продать в первую очередь, чтобы уменьшить влияние общего спада в отрасли на наш бизнес?
ESS формирует пакеты информации по заданным темам и представляет комфортный доступ для высших руководителей компаний и корпораций без посредников. Интерфейс ESS чрезвычайно дружелюбен, используется наглядная графика, аудио и видеосредства, мобильная связь, современные методы хранения и представления данных, а также проведения видеоконференций в распределенных компаниях.
В настоящее время с развитием технологий Internet/Intranet круг пользователей ESS значительно расширился – он, подобно MIS, охватывает практически все уровни управления, кроме эксплуатационного. Информационные базы ESS содержат большие объемы наглядной и "исторической" информации, которая может быть очень полезна на уровнях выполнения проектов. Современные ESS широко используют технологии географических информационных систем (Geographical Information System – GIS). GIS до последнего времени не получали достойного применения из-за высокой стоимости и необходимости дописывать необходимые программные модули и интерфейсы. Многопрофильные и многонациональные корпорации последней четверти конца ХХ века, связанные с нефтяным, геологоразведочным, авиатранспортным, рыболовным, туристическим бизнесом, сделали GIS необходимым приложением к информационной системе общего пользования.
Примером долгоживущей системы на рынке программных продуктов, реализующих ESS, может быть пакет Comshare's Commander Decision, выполненный по технологии "клиент-сервер". Пакет CDD работает с информацией любого вида, включая запросы, вычисления, несложный статистический анализ данных, работу с таблицами, гипертекстом. Этот универсальный инструмент может использоваться для разработки традиционных ESS-приложений для систем поддержки принятия решений на различных уровнях управления и исполнения. CDD обеспечивает выборочный контроль, распознавание информации по шаблонам, демонстрацию диаграмм по лучшим и худшим показателям, указывает на необходимость обновить информацию по текущим выборкам данных.

