 2015-07-04
2015-07-04 888
888Реляционная база данных представляется пользователю как совокупность таблиц и ничего кроме таблиц. На рис.1.1 приведен пример реляционной базы данных ПАНСИОН. Этот простой пример используется для иллюстрации большинства вопросов, рассматриваемых в нашей книге. Поэтому советуем потратить немного времени, чтобы хорошо с ним разобраться*.
Кладовая пансионата периодически пополняется продуктами из списка, часть которого показана в таблице Продукты. Каждый продукт имеет кроме названия (столбец Продукт) уникальный номер этого продукта (столбец ПР). Химический состав продуктов приведен для 1 кг их съедобной части: основные пищевые вещества (белки, жиры и углеводы) даны в граммах, а минеральные вещества (калий, кальций, натрий) и витамины (B2, PP, C) - в миллиграммах.
В таблице Блюда представлены уникальные номера блюд (столбец БЛ), их названия, коды видов (см. таблицу Вид_блюд), основной продукт (столбец Основа), масса порции в граммах (столбец Выход) и приведенная стоимость в копейках приготовления одной порции (столбец Труд).
В таблице Рецепты приведена технология приготовления блюд. Их выделение в отдельную таблицу произведено потому, что одно и то же блюдо может иметь несколько разных рецептов.
Таблица Состав связывает между собой таблицы Блюда и Продукты, оговаривая, какая масса (в граммах) того или иного продукта (столбец Вес) должна входить в состав одной порции блюда. Так, порция блюда с номером 12 (Суп молочный) должна состоять из 350 г продукта с номером 7 (Молоко), 35 г продукта с номером 13 (Рис), 5 г продукта с номером 3 (Масло) и 5 г продукта с номером 16 (Сахар).
Шеф-повар ежедневно получает от завхоза сведения о количестве в килограммах имеющихся продуктов и их текущей стоимости (столбцы К_во и Стоимость таблицы Наличие). Используя эти сведения он определяет по таблице Состав перечень тех блюд, которые можно приготовить из этих продуктов, а также калорийность и стоимость таких блюд. При этом стоимость блюда складывается из стоимости и массы продуктов, необходимых для приготовления одной его порции, а также из трудозатрат на ее приготовление (см. таблицу Блюда). Калорийность же определяется по массе и калорийности каждого из продуктов блюда. (Для получения значения калорийности продукта исходят из того, что при окислении 1 г углеводов или белков в организме освобождается в среднем 4.1 ккал, а при окислении 1 г жиров - 9.3 ккал.)
Рис. 1.1. Основные таблицы базы данных ПАНСИОН Учитывая примерную стоимость и необходимую калорийность дневного рациона отдыхающих, шеф-повар составляет меню на следующий день. В этом меню (таблица Меню) предлагается по несколько альтернативных блюд каждого вида (таблица Вид_блюд) и для каждой трапезы (таблица Трапезы). Перед завтраком каждый отдыхающий вводит в ЭВМ номер закрепленного за ним места в столовой пансионата (столбец СМ в таблице Выбор) и желаемый набор блюд для каждой из трапез следующего дня (в примере таблица заполнялась отдыхающим, сидящим на месте с номером 2). Таблицы Выбор объединяются по мере их создания в общую таблицу Выбрано, по которой определяют, сколько порций того или иного блюда надо приготовить для каждой трапезы. Завхоз связан с поставщиками продуктов, сведения о которых хранятся в таблице Поставщики. Эта таблица содержит уникальный номер поставщика (столбец ПС), его название, статус, месторасположение и телефон. Таблица Поставки связывает между собой таблицы Продукты и Поставщики, оговаривая, какое количество продукта (столбец К_во) и по какой цене поставил тот или иной поставщик. Отсутствие в строке цены и количества говорит о том, что поставщик ПС может поставлять продукт ПР, но в данный момент не осуществил такой поставки. Легко заметить, что все таблицы примера (как и все таблицы любой реляционной базы данных) состоят из строки заголовков столбцов и одной или более строк значений данных под этими заголовками. Эти столбцы и строки должны иметь следующие свойства:
Почему же база данных, составленная из таких таблиц, называется реляционной? А потому, что отношение - relation - просто математический термин для обозначения неупорядоченной совокупности однотипных записей или таблиц определенного специфического вида, описанного выше. Таким образом, можно, например, сказать, что база данных ПАНСИОН состоит из одиннадцати отношений. Реляционные системы берут свое начало в математической теории множеств. Они были предложены в конце 1968 года доктором Э.Ф.Коддом из фирмы IBM, который первым осознал, что можно использовать математику для придания надежной основы и строгости области управления базами данных. Нечеткость многих терминов, используемых в сфере обработки данных, заставила Кодда отказаться от них и придумать новые или дать более точные определения существующим. Так, он не мог использовать широко распространенный термин "запись", который в различных ситуациях может означать экземпляр записи, либо тип записей, запись в стиле Кобола (которая допускает повторяющиеся группы) или плоскую запись (которая их не допускает), логическую запись или физическую запись, хранимую запись или виртуальную запись и т.д. Вместо этого он использовал термин "кортеж длины n" или просто "кортеж", которому дал точное определение. В литературе [2,3] можно подробно познакомиться с терминологией реляционных баз данных, а здесь мы будем использовать неформальные их эквиваленты:
Мы также принимаем, по определению, что "запись" означает "экземпляр записи", а "поле" означает "имя и тип поля". * Так как иллюстративная база данных создавалась для лекционного курса в 1988 году, когда существовали "смешные" цены, а также исчезнувшие названия статусов (коопторг) и городов (Ленинград), то автор пытался несколько раз ее модифицировать. Однако поняв, что изменение цен, статусов и названий идет быстрее, чем подготовка и, тем более, выпуск издания, он решил сохранить в книге старые цены и названия. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1.2 Почему SQL? Все языки манипулирования данными (ЯМД), созданные до появления реляционных баз данных и разработанные для многих систем управления базами данных (СУБД) персональных компьютеров, были ориентированы на операции с данными, представленными в виде логических записей файлов. Это требовало от пользователей детального знания организации хранения данных и достаточных усилий для указания не только того, какие данные нужны, но и того, где они размещены и как шаг за шагом получить их. Рассматриваемый же ниже непроцедурный язык SQL (Structured Query Language - структуризованный язык запросов) ориентирован на операции с данными, представленными в виде логически взаимосвязанных совокупностей таблиц. Особенность предложений этого языка состоит в том, что они ориентированы в большей степени на конечный результат обработки данных, чем на процедуру этой обработки. SQL сам определяет, где находятся данные, какие индексы и даже наиболее эффективные последовательности операций следует использовать для их получения: не надо указывать эти детали в запросе к базе данных. Для иллюстрации различий между ЯМД рассмотрим следующую ситуацию. Пусть, например, вы собираетесь посмотреть кинофильм и хотите воспользоваться для поездки в кинотеатр услугами такси. Одному шоферу такси достаточно сказать название фильма - и он сам найдет вам кинотеатр, в котором показывают нужный фильм. (Подобным же образом, самостоятельно, отыскивает запрошенные данные SQL.) Для другого шофера такси вам, возможно, потребуется самому узнать, где демонстрируется нужный фильм и назвать кинотеатр. Тогда водитель должен найти адрес этого кинотеатра. Может случиться и так, что вам придется самому узнать адрес кинотеатра и предложить водителю проехать к нему по таким-то и таким-то улицам. В самом худшем случае вам, может быть, даже придется по дороге давать указания: "Повернуть налево... проехать пять кварталов... повернуть направо...". (Аналогично больший или меньший уровень детализации запроса приходится создавать пользователю в разных СУБД, не имеющих языка SQL.) Появление теории реляционных баз данных и предложенного Коддом языка запросов "alpha", основанного на реляционном исчислении [2, 3], инициировало разработку ряда языков запросов, которые можно отнести к двум классам:
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1.3 Таблицы SQL. До сих пор понятие "таблица", как правило, связывалось с реальной или базовой таблицей, т.е. c таблицей, для каждой строки которой в действительности имеется некоторый двойник, хранящийся в физической памяти машины (рис.1.2). Однако SQL использует и создает ряд виртуальных (как будто существующих) таблиц: представлений, курсоров и неименованных рабочих таблиц, в которых формируются результаты запросов на получение данных из базовых таблиц и, возможно, представлений. Это таблицы, которые не существуют в базе данных, но как бы существуют с точки зрения пользователя. Базовые таблицы создаются с помощью предложения CREATE TABLE (создать таблицу), подробное описание которого приведено в главе 5. Здесь же приведем пример предложения для создания описания таблицы Блюда: 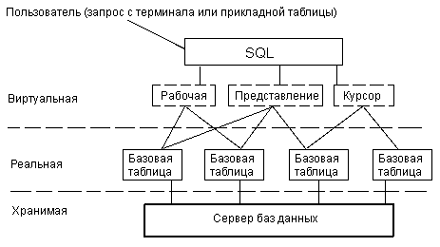 Рис. 1.2. База данных в восприятии пользователя Рис. 1.2. База данных в восприятии пользователя
Предложение CREAT TABLE специфицирует имя базовой таблицы, которая должна быть создана, имена ее столбцов и типы данных для этих столбцов (а также, возможно, некоторую дополнительную информацию, не иллюстрируемую данным примером). CREAT TABLE - выполняемое предложение. Если его ввести с терминала, система тотчас построит таблицу Блюда, которая сначала будет пустой: она будет содержать только строку заголовков столбцов, но не будет еще содержать никаких строк с данными. Однако можно немедленно приступить к вставке таких строк данных, возможно, с помощью предложения INSERT и создать таблицу, аналогичную таблице Блюда рис.1.1. Если теперь потребовалось узнать какие овощные блюда может приготовить повар пансионата, то можно набрать на терминале следующий текст запроса:
и мгновенно получить на экране следующий результат его реализации:
|
Для выполнения этого предложения SELECT (выбрать), подробное описание которого будет дано в главах 2 и 3, СУБД должна сначала сформировать пустую рабочую таблицу, состоящую из столбцов БЛ и Блюдо, тип данных которых должен совпадать с типом данных аналогичных столбцов базовой таблицы Блюда. Затем она должна выбрать из таблицы Блюда все строки, у которых в столбце Основа хранится слово Овощи, выделить из этих строк столбцы БЛ и Блюдо и загрузить укороченные строки в рабочую таблицу. Наконец, СУБД должна выполнить процедуры по организации вывода содержимого рабочей таблицы на экран терминала (при этом если в рабочей таблице содержится более 20-24 строк, она должна использовать процедуры постраничного вывода и т.п.). После выполнения запроса СУБД должна уничтожить рабочую таблицу.








