2015-07-03
2015-07-03 400
400В системе DB2 индексы основываются на структуре, называемой В-деревом. B-дерево— это многоуровневый, имеющий древовидную структуру индекс, обладающий тем свойством, чтоэто дерево всегда сбалансировано. Это означает, что все вершины — листья в такой структуре—равноудалены от корня дерева, иэтосвойство сохраняется, когда в дерево вставляются новые вершины и удаляются существующие. В результате такой индекс обеспечивает постоянную и прогнозируемую производительность для операций поиска. Подробное обсуждение вопроса о том, каким образом достигается такой результат, выходит за рамки этой книги. Однако на рис. 13.3 приводится простой пример, показывающий, как мог бы выглядеть такой индекс.
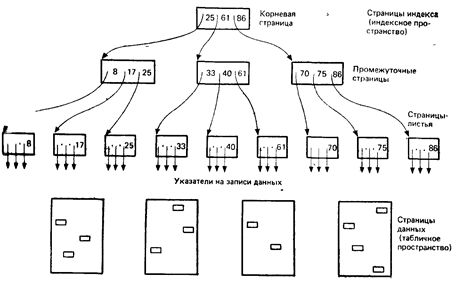
Рис. 13.3. Пример индекса
Как видно из рисунка, индекс состоит из корневой страницы, из нуля или более промежуточных страниц (образующих нуль или более промежуточных уровней, в примере имеется один такой промежуточный уровень), а также из некоторого множества страниц—листьев. На уровне листьев имеется по одной статье—значение индексируемого поля и указатель — для каждой записи в индексируемой таблице. Страницы — листья связываются между собой так, что они сами по себе могут использоваться для быстрого последовательного доступа к индексируемым данным в порядке, поддерживаемом индексом. Каждый уровень выше уровня листьев в свою очередь содержит по одной статье — наивысшее значение поля и указатель для каждой страницы статей более низкого уровня. Таким образом, корневая страница вместе с промежуточными страницами обеспечивают быстрый прямой доступ к страницам—листьям, а следовательно, быстрый прямой доступ также и к индексируемым данным.
Для заданной хранимой таблицы может иметься любое число связанных с нею индексов, и поэтому для нее может поддерживается любое число способов логического упорядочения. Конечно, всегда существует единственный способ физического упорядочения. Для того чтобы произвести полный просмотр таблицы в соответствии с заданным индексом, программа управления хранимыми данными будет обращаться ко всем записям в рассматриваемой таблице в последовательности, определяемой этим индексом. Поскольку такая последовательность может быть весьма отличной от физической последовательности, установленной для таблицы, обращение к любой странице данных может осуществляться много раз. (С другой стороны, вообще не будет обращений к страницам данных, не содержащих никаких записей таблицы.). Поэтому полный просмотр с помощью индекса потенциально может оказаться более медленным, чем полный просмотр в физической последовательности, если рассматриваемый индекс не является индексом кластеризации. Как уже указывалось ранее, индекс кластеризации—это такой индекс, для которого определяемая им последовательность совпадает с физической или близка к ней. Для каждой таблицы может быть создано не более одного индекса кластеризации. Этот индекс должен быть первым индексом, создаваемым для таблицы, и в идеальном случае должен создаваться прежде, чем в таблицу будут загружаться какие-либо данные. Индексы кластеризации имеют чрезвычайно важное значение с точки зрения оптимизации. Генератор планов прикладных задач всегда будет пытаться выбрать путь доступа, основанный на индексе кластеризации, если такой индекс имеется в распоряжении. На практике индекс кластеризации следует иметь для каждой таблицы, если только она не слишком мала, а возможно, даже и в этом случае.