 2015-09-06
2015-09-06 989
989Исходная строка:
16) abaaabbccdabaacadb
Исходная строка будет закодирована следующим образом:
02ab3a2b2c03dab2a04cadb
Так как исходная строка занимала 18 байт, а кодированная – 23 байт, то достигается коэффициент сжатия Kсж = 18/23 = 0,783 < 1. Сжатие считается не эффективным.
Применение алгоритма LZW
a | b | a | aa | b | b | c | c | d | ab | aa | c | a | d | b
0 1 0 6 1 1 2 2 3 4 6 2 0 3 1
| Номер слова | Слово | Номер слова | Слово |
| a | bc | ||
| b | cc | ||
| c | cd | ||
| d | da | ||
| ab | aba | ||
| ba | aac | ||
| aa | ca | ||
| aab | ad | ||
| bb | db |
Сжатый поток состоит из ссылок:
0 1 0 6 1 1 2 2 3 4 6 2 0 3 1
Входной поток был байтовым, на каждую ссылку отводится тоже один байт, получаем коэффициент сжатия Ксж = 18/15 = 1,2 > 1. Сжатие считается эффективным.
Применение метода сжатия с использованием кода Хаффмана
Рассчитаем частоты появления символов алфавита:
a = 8/18 = 0,444
b = 5/18 = 0,278
c = 3/18 = 0,167
d = 2/18 = 0,111
Сформируем дерево:
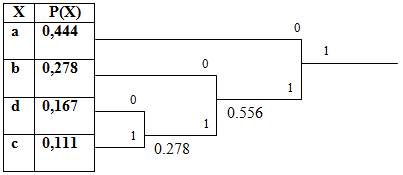
Код Хаффмана символов алфавита:
| X | Code |
| a | |
| b | |
| d | |
| c |
Предположим, что входной поток был байт ориентированным, тогда
Kсж = 8/ (0,444∙1 + 0,278∙2 + 0,167∙3 + 0,111∙3) = 8/ 1,723 = 4,362.
Сжатие считается эффективным.
Вывод: Для данного примера наиболее эффективным является сжатие с применением кода Хаффмана.








