 2015-10-22
2015-10-22 2172
2172Традиционные базы данных разрабатываются для обслуживания текущих записей. Например, традиционная инвентаризационная база данных используется для регистрации текущего списка предметов в целях поддержания надлежащего уровня запасов. В таких случаях записи о прошлых инвентаризациях можно найти только в архивных копиях базы данных или явно сохраняя дату инвентаризации как атрибут в базе данных. Существует множество приложений, в которых реализован более удобный доступ к данным и возможность записи данных в будущем. Этот пример иллюстрируется секретариатом университета, который должен планировать выполнение программы обучения, хранить составы групп, отслеживать назначение аудиторий, регистрировать выбор преподавателей и т. д., причем делать это не только для текущего семестра, но и для предыдущих и будущих семестров. Когда в хронологическую базу данных добавляются новые записи, старая информация не удаляется. Новые записи просто становятся последними в архиве, к любой части которого можно без труда обратиться,
В настоящее время ведутся активные исследования хронологических баз данных. Их цель — найти эффективные способы хранения и обработки прошлой, текущей и будущей информации, разработать способы для поиска необходимых данных в таких записях и создать языки запросов к хронологическим базам данных.
Другая, возможно, более серьезная проблема с расширенным отношением возникает, когда мы решаем удалить информацию из базы данных. Предположим, что Джо Е. Бэйкер — это единственный сотрудник, который занимал должность, обозначаемую D7. Если он уволится из компании и его запись будет удалена из базы данных, показанной на рис. 9.4, мы потеряем информацию о должности D7. Действительно, единственная строка, в которой указано, что для должности D7 требуется уровень квалификации К2, это строка, относящаяся к Джо Бэйкеру. То есть если мы удалим все упоминания о Джо Бэйкере и позже захотим получить из базы данных информацию о должности D7, то не найдем необходимых данных.
Вы можете возразить, что эту проблему можно решить, разрешив удалять только часть строки, но это, в свою очередь, приведет к новым сложностям. (Нужно ли оставлять информацию о должности F5 в частичной строке или она присутствует еще в каком-либо кортеже?) Кроме того, искушение использовать частичные строки явно указывает на то, что структуру базы данных можно улучшить.
Причина всех этих проблем в том, что мы объединили несколько представлений в одном отношении. Как уже говорилось, расширенное отношение на рис. 9.4 содержит информацию непосредственно о сотрудниках (имя, идентификационный номер, адрес, номер социального обеспечения), о должностях, существующих в компании (идентификатор должности, название должности, отдел, код
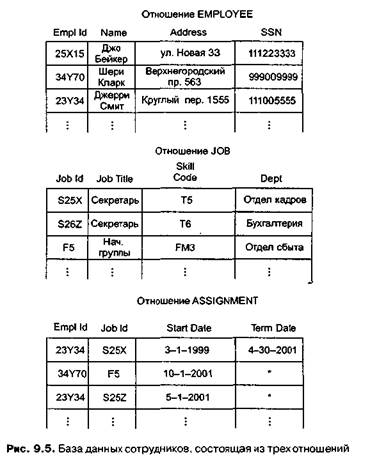
квалификации), и о связях между сотрудниками и должностями (дата начала, дата окончания). Основываясь на этом наблюдении, мы можем решить проблемы, перестроив систему с использованием трех отношений — по одному на каждую перечисленную выше совокупность информации. Мы сохраним отношение, показанное на рис. 9.3 (которое теперь назовем EMPLOYEE (служащий)), в исходном виде и введем дополнительную информацию в форме двух новых отношений JOB (должность) и ASSIGNMENT (назначение (на должность)), получив в итоге базу данных, представленную на рис. 9.5.
В базе данных, состоящей из этих трех отношений, вся информация о сотрудниках хранится в отношении EMPLOYEE, о должностях — в отношении JOB, и об истории этих должностей — в отношении ASSIGNMENT. Дополнительную информацию можно явно получить, совместив данные из разных отношений. Например, если мы знаем идентификационный номер сотрудника, то можем найти отделы, в которых он работал. Для этого сначала необходимо узнать все должности, которые занимал этот сотрудник, при помощи отношения ASSIGNMENT и затем найти отделы, с которыми связаны найденные должности, в отношении JOB (рис. 9.6).
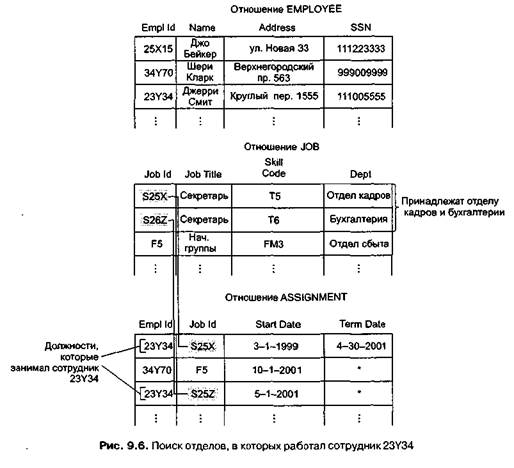
Выполняя подобные процедуры, любую информацию, которую можно было бы получить из одного большого отношения, мы можем теперь восстановить из трех небольших отношений, избежав при этом ранее перечисленных проблем.
К сожалению, разделение информации на разные отношения не всегда так просто, как в предыдущем примере. Например (рис. 9.7), сравните исходное отношение с атрибутами Empild, JobTitie и Oept с предлагаемым разбиением на два новых отношения. На первый взгляд, система с двумя отношениями содержит ту же информацию, что и система с одним отношением, но на самом деле это не так. Возьмем проблему поиска отдела, в котором работает определенный сотрудник. Это легко сделать в системе с одним отношением, опросив строку, содержащую идентификационный номер сотрудника, и выбрав соответствующий отдел. Но в системе с двумя отношениями нужная информация не так легко доступна. Мы можем найти должность нашего сотрудника и отдел, которому принадлежит эта должность, но это не означает, что данный сотрудник работает именно в этом отделе, так как одна и та же должность может присутствовать в различных отделах.
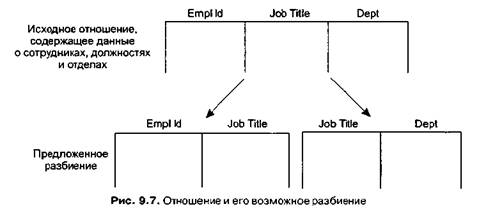
В некоторых случаях отношение можно разделить на более мелкие части без потери информации, в других случаях какие-то данные теряются. (Первый вариант называется разбиением без потерь, или беспроигрышным разбиением.) Изучение свойств отношений было и остается темой исследований вычислительной техники. Цель изысканий — указать свойства отношений, которые могут привести к возникновению проблем в разработке базы данных, и найти способы реорганизации отношений для их устранения.
Реляционные операции
Теперь, когда у вас есть базовое понимание структуры реляционной модели, настало время узнать, как с такой организацией можно работать с точки зрения программиста. Мы начнем с обзора некоторых операторов, которые можно выполнять на отношениях.
Иногда нам бывает необходимо выбрать определенные строки из отношения. Для получения информации о сотруднике нужно выбрать строку с соответствующим значением идентификационного атрибута из отношения EMPLOYEE. Чтобы получить список должностей в определенном отделе, из отношения JOB нужно выбрать строку, где нужный отдел хранится в соответствующем атрибуте. Результат выбора — это еще одно отношение (или таблица), состоящее из строк, выбранных из родительского отношения. Выбирая информацию об определенном сотруднике, мы получим отношение с единственной строкой, производное от отношения EMPLOYEE. При выборе данных, связанных с определенным отделом, мы, вероятно, получим несколько строк из отношения JOB.
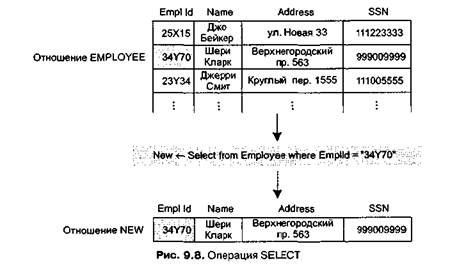
Одна из операций, которые мы могли бы произвести на отношении, — это выбор строк, обладающих определенными свойствами, и размещение этих строк в новом отношении. Для выражения этой операции мы принимаем синтаксис NEW <- SELECT from EMPLOYEE where Emplld = "34Y70"
Семантика этого оператора — создать новое отношение с именем NEW, содержащее такие строки (в данном случае строка одна) из отношения EMPLOYEE, для которых значение атрибута Empl Id равно 34Y70 (рис. 9.8).
В противоположность операции SELECT, которая выбирает строки из отношения, операция PROJECT выбирает столбцы. Предположим, например, что в процессе поиска названий должностей в определенном отделе мы уже применили операцию SELECT и выбрали из отношения JOB строки, относящиеся к данному отделу, а затем поместили эти строки в новое отношение с именем NEW1. Нужный нам список — это столбец JobTitle из нового отношения. При помощи операции PROJECT мы сможем получить этот столбец (или несколько столбцов, если необходимо) и поместить его в новое отношение. Это выражается так: NEW2 <- PROJECT JobTitle from NEW1
Результатом будет создание еще одного нового отношения (с именем NEW2), содержащего один столбец со значениями из столбца JobTitle отношения NEW1.
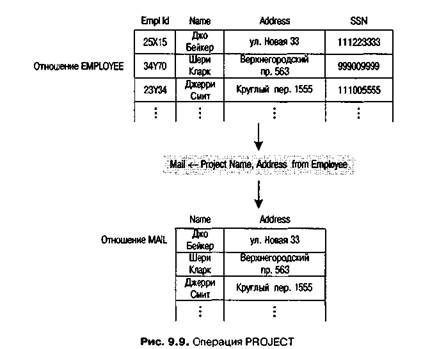
Еще один пример использования операции PROJECT — оператор МЛН <- PROJECT Name. Address from EMPLOYEE который можно применять для получения списка имен и адресов сотрудников. Этот список является заново созданным отношением (с двумя столбцами) с именем MAIL (рис. 9.9).
Третья операция, с которой мы познакомимся, — это JOIN. Она используется для объединения нескольких отношений в одном. Применение JOIN к двум отношениям приведет к появлению нового отношения, атрибуты которого будут содержать атрибуты исходных отношений (рис. 9.10). Названия атрибутов сохраняются, но к каждому присоединяется префикс — имя исходного отношения. (Если отношение А с атрибутами V и W соединить при помощи JOIN с отношением В с атрибутами X, Y и Z, в результате мы получим пять атрибутов: A.V, A.W, В.Х, В. Y и B.Z.) Эти соглашения именования гарантируют, что у атрибутов в новом отношении будут уникальные имена, даже если в исходных отношениях названия атрибутов совпадали.
Строки нового отношения конструируются путем слияния строк из двух исходных отношений (см. рис. 9.10). Какие именно строки соединяются для образования строк нового отношения, определяется условием оператора JOIN. Пример условия — указанные атрибуты должны иметь одинаковые значения. Именно такое условие используется на рис. 9.10, где демонстрируется результат оператора С <- JOIN A and В where A.W = В.Х
В этом примере строка из отношения А должна быть соединена со строкой из отношения В, только если атрибуты W и X этих отношений имеют одинаковые значения. Именно поэтому результат слияния строки (г. 2) из отношения А со строкой (2, m. q) из отношения В появляется в итоговом отношении. С другой

стороны, результат слияния строки (г, 2) из отношения А и строки (5. д. р) из отношения В не присутствует в новом отношении, так как в этих строках значения атрибутов Ми Хне равны.
В качестве другого примера на рис. 9.11 представлен результат выполнения оператора С <_ JOIN A and В where A.W < В.Х
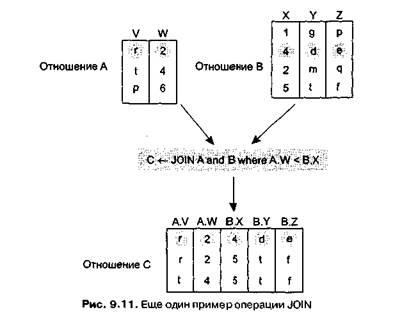
Обратите внимание, что в итоговом отношении появляются только те строки, для которых значение атрибута W в отношении А меньше значения атрибута X в отношении В.
Теперь посмотрим, как операцию JOIN можно применить к базе данных на рис. 9.5 для получения списка идентификационных номеров всех сотрудников и названий отделов, где они работают. Мы сразу же видим, что нужная информация распределена по нескольким отношениям, и поэтому процесс ее восстановления потребует применения дополнительно операций SELECT и PROJECT. Нам необходим оператор
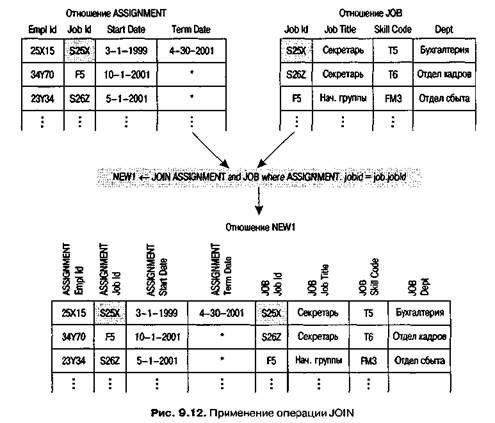
NEW1 <- JOIN ASSIGNMENT and JOB where ASSIGNMENT.Jobld = JOB.Jobld
который создаст отношение NEW1 (рис. 9.12). Из этого отношения нужно сначала выбрать оператором SELECT строки, в которых значение ASSIGNMENT.TermDate равно «*» (что означает «все еще работает»), и затем применить оператор PROJECT для получения атрибутов ASSIGNMENT. Empl Id и JOB.Dept. Таким образом, необходимую информацию из базы данных на рис. 9.5 можно получить, выполнив операции
NEW1 <- JOIN ASSIGNMENT and JOB where ASSIGNMENT.Jobld = JOB.Jobld NEW2 «- SELECT from NEW1 where ASSIGNMENT.TermDate = "*" LIST <- PROJECT ASSIGNMENT.EmplId. JOB.Dept from NEW2
Вопросы реализации
Теперь, когда мы познакомились с основными реляционными операциями, рассмотрим заново общую структуру системы базы данных. Вспомните, что данные базы в действительности хранятся на запоминающем устройстве. Чтобы освободить программиста от подробностей фактической реализации хранения, предусмотрена система управления базой данных, которая позволяет писать приложения в терминах модели базы данных, такой как рассмотренная реляционная модель. В обязанности СУБД входит получение команд в терминах реляционной модели и преобразование их в действия, проводимые в действительной структуре хранения. Это делается за счет предоставления набора процедур, которые приложение может использовать как абстрактные инструменты. Таким образом, СУБД, основанная на реляционной модели, будет включать процедуры для выполнения операций SELECT, PROJECT и JOIN, которые можно вызвать из приложения при помощи синтаксической структуры, совместимой с базовым языком. В этом смысле приложения можно создавать, считая, что данные хранятся в простой табличной форме реляционной модели.
Полезно представить, как система управления базой данных могла бы записывать данные в базу и как устройство хранения могло бы воздействовать на работу СУБД. Например, простейший способ, при помощи которого СУБД может реализовать отношение — записать его в виде последовательного файла, в котором каждая строка является логической записью. Однако эта стратегия подразумевает, что выполнение операции SELECT потребует последовательного поиска в файле, а этот процесс в больших отношениях занимает много времени. Поэтому СУБД, вероятнее, будет хранить отношения как индексированный файл или применять методы хэширования для обеспечения быстрого доступа к данным. Например, если индексировать отношение EMPLOYEE из рис. 9.5 по идентификационному номеру сотрудника, то информацию об определенном сотруднике можно будет быстро разыскать оператором SELECT, зная его идентификационный номер. Эти вопросы очень важны при разработке, и решение часто зависит от того, как будет использоваться база данных. Дело в том, что основные структуры данных и файловые структуры являются строительными блоками, из которых создаются системы управления базами данных.
И, наконец, необходимо заметить, что в современных системах управления базами данных операции SELECT, PROJECT и JOIN не обязательно присутствуют в своей первоначальной форме. Чаще они образуют операции, которые являются комбинациями этих базовых шагов. Пример тому — язык SQL.
Язык SQL
Язык под названием SQL (Structured Query Language — язык структурированных запросов) широко используется программистами, создающими приложения для работы с базами данных в терминах реляционной модели. Одна из причин его популярности состоит в том, что он стандартизирован Национальным институтом стандартизации США. Другая причина — этот язык был создан и распространен компанией IBM, что гарантирует всестороннюю проверку и испытание.
В этом разделе мы узнаем, как запросы к реляционным базам данных выражаются на SQL.
Начнем с того, что запросы, включающие комбинации операций SELECT, PROJECT и JOIN, можно выразить одним оператором языка SQL. Кроме того, хотя кажется, что запрос на SQL выражается в императивной форме, в действительности он является описательным оператором. Вы должны читать оператор SQL как описание нужной информации, а не как последовательность действий. Важность этого подхода состоит в том, что SQL освобождает программистов от сложностей разработки алгоритмов для управления отношениями — им нужно просто описать желаемую информацию.
В качестве примера оператора SQL возьмем наш последний запрос, то есть состоящий из трех шагов алгоритм, для получения всех идентификационных номеров и соответствующих отделов. На SQL весь запрос можно выразить одним оператором:
select Emplld. Dept from ASSIGNMENT, JOB where ASSIGNMENT.Jobld = JOB.Jobld and ASSIGNMENT.TermDate = '*'
Как показывает этот пример, в каждом операторе SQL может быть три предложения: select, from и where. Грубо говоря, такой оператор — это запрос на применение операции JOIN ко всем отношениям, перечисленным в предложении from, выбор операцией SELECT тех строк, которые удовлетворяют условиям в предложении where, и последующий выбор при помощи операции PROJECT строк в предложении select. (Обратите внимание, что терминология в некотором смысле перевернута, то есть предложение select в операторе SQL идентифицирует атрибуты, используемые в операции PROJECT.) Приведем несколько простых примеров.
Оператор
select Name. Address from EMPLOYEE
получает список имен и адресов всех сотрудников, присутствующих в отношении EMPLOYEE. Заметьте, что это простая операция PROJECT. Оператор
select Emplld, Name. Address, SSN
from EMPLOYEE
where Name = 'Мери Кларк'
получает всю информацию из строки, относящейся к Шери Кларк в отношении EMPLOYEE. В действительности это операция SELECT. Оператор
select Name, Address
from EMPLOYEE
where Name = 'Шери Кларк'
получает имя и адрес Шери Кларк из отношения EMPLOYEE. Это комбинация операций SELECT и PROJECT. Оператор
select EMPLOYEE.Name. ASSIGNMENT.StartDate
from EMPLOYEE. ASSIGNMENT
where EMPLOYEE.EmplId = ASSIGNMENT.EmplId
получает список имен всех сотрудников и даты начала их работы. Обратите внимание, что это результат применения операции JOIN к отношениям EMPLOYEE и ASSIGNMENT и последующего выбора операциями SELECT и PROJECT подходящих строк и атрибутов, что указано предложениями where и select.
Завершим раздел обзором операторов SQL, которые помимо выполнения запросов позволяют определять структуру отношений, создавать отношения и модифицировать их содержимое. Далее приведены примеры операторов insert into, delete from и update.
Оператор
insert into EMPLOYEE
values C42Z12'. 'Сью Барт', 'ул. Красивая. 33'.
444 661 111')
добавляет в отношение EMPLOYEE строку с данными значениями;
delete from EMPLOYEE where Name = 'Джерри Смит'
удаляет строку, относящуюся к Джерри Смит, из отношения EMPLOYEE; a
update EMPLOYEE
set Address = 'пр. Наполеона. 1812'
where Name = 'Джо Бейкер'
изменяет адрес в строке, связанной с Джо Бейкером, в отношении EMPLOYEE.

