2015-10-22
2015-10-22 251
251{
case'*':;
case'/':where=out;
default:where=in_com;
}
}
}
fclose(f_in);
fclose(f_out);
}
Розглянемо ще кілька прикладів.
1. Нехай необхідно зі вхідного файла виділити ідентифікатори, що містять цифри. Припустимо для простоти, що синтаксично ідентифікатори записані правильно.
Для класифікації послідовностей символів визначимо такі множини:
L – 'A'..'Z', 'a'..'z', '_';
D – '0'..'9';
R – роздільники ' ', '.', ',', ':', ';', '-', '+', EOL;
Визначимо стани, у яких знаходитиметься СА:
I – очікування появи ідентифікатора;
L – обробка ідентифікатора. Очікування появи цифри;
LD – обробка ідентифікатора з цифрою. Очікування кінця ідентифікатора.
Автомат має виконувати такі дії:
M – пропустити символ;
А – записати символ у буфер;
W – вивести буфер у вихідний файл і очистити;
С – очистити буфер.
Складемо діаграму станів СА (рис. 9.6).
 Рис. 9.6
Рис. 9.6
2. Нехай маємо послідовність символів x1...xn. Визначити, чи є в ній символи "abcd", що йдуть один за одним. Іншими словами, вимагається з'ясувати, чи міститься в слові Х підслово "abcd".
Проглядатимемо слово Х зліва направо в очікуванні появи символу 'a'. Як тільки він з'явиться, чекаємо появи за ним символу 'b', потім 'c' і, нарешті, 'd'.
Таким чином, ми в кожен момент знаходимося в одному з таких станів: початковий (0), очікування b після а (A), очікування с після ab (B), очікування d після abc (C) і вихід після abcd (D).
Складемо діаграму станів (рис. 9.7).
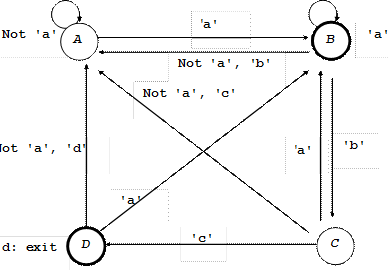 Рис. 9.7
Рис. 9.7
Стан Exit означає закінчення роботи. Напишемо відповідну програму:
enum states{A,B,C,D};
enum boolean{false,true};
char current;
boolean stop;
states where;
FILE*f_in;
main(){
where=A;
stop=false;
f_in=fopen("c:\\text_in.txt");
while(!feof(f)||stop)
{
current=getc(f_in);
Switch (where)
{