 2015-10-22
2015-10-22 372
372Текущая точка = Началу области построения графика
Шаг = Начальное значение шага.
Номер точки разрыва = 0
Минимум = 0
Максимум = 0
Пока текущая точка не достигла конца области построения делать
Начало
Вычислить ординату текущей точки
Если ордината меньше минимума или больше максимума
То
Выполнить функцию поиска разрыва
Если разрыв найден
То
Прибавить к абсциссе текущей точки величину найденной окрестности точки разрыва.
Иначе
Если ордината больше максимума то максимум = ордината
Если ордината меньше минимума то минимум = ордината
Конец
Функция поиска точки разрыва
Шаг = Величина большая текущего шага.
Точка1 = текущая точка
Точка2 = Точка1+Шаг
Если Ордината1 > Ордината2 то Направление = вниз
Если Ордината1< Ордината2 то Направление = вверх
Есди Ордината1 = Ордината2
То результат функции = разрыв не найден, работу прекратить
Повторять
Точка1 = Точка2
Точка2 = Точка1 + Шаг
Если Ордината1 сильно отличается от ординаты2
То Результат функции = разрыв найден
Если Ордината1 > Ордината2 то Направление1 = вниз
Если Ордината1< Ордината2 то Направление1 = вверх
Если Направление1 <> Направление2
То Результат функции = разрыв найден
Конец цикла
Важное примечание
Точка разрыва это объект очень высокой степени сложности. Вряд ли можно построить алгоритм удовлетворительно работающий для любого случая. Данный алгоритм также необходимо рассматривать как общую схему, которую возможно придётся модифицировать для конкретных случаев.
Думаю, вы обратили внимание, что некоторые понятие здесь не вполне определены. Например не ясно что означает фраза “Ордината1 сильно отличается от ординаты2”
Алгоритм построения графика функции:
1. Ввести начало математической системы координат. Масштаб (количество пикселей в единичном отрезке).
2. Нарисовать оси координат и сделать разметку (это может быть либо сетка, либо просто насечки на осях). Сделать оцифровку.
3. Построить график. Для этого:
· Перебрать все экранные координаты х (от 0 до 639).
· Перевести каждый х – экранный в х – математический. (хэ=а+хм*m, откуда получаем хм=(хэ-а)/ m, где (а,в) – координаты точки начала математической системы координат, m – масштаб).
· Проверить входит ли найденное хм в область определения функции, график которой мы строим.
· Вычислить ум (ум=f(хм)).
· Перевести ум в уэ (уэ=round(b- ум)).
· Изобразить точку с координатами (хэ, уэ) на экране монитора.
Задачи: Построить графики функций: у=х2; у=sinx; у= 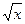 ; у=1/х.
; у=1/х.
Диаграммы.
Пусть нам дан массив из чисел, необходимо на экране изобразить столбчатую диаграмму так, чтобы каждому числу соответствовал свой столбик, причем пропорциональность столбцов и чисел должна соблюдаться. Все столбики должны быть разных цветов и рядом с ними должно стоять число им соответствующее, желательно около координатной прямой проставить порядковый номер каждого столбца.
Алгоритм построение столбчатой диаграммы:
1. Ввести массив из чисел.
2. В исходном массиве найти максимальный элемент, и для него определить масштаб для построения столбиков (например, l=round(450/max)).
3. По количеству элементов определить ширину каждого столбика диаграммы (например, m=round(600/n), где n – количество элементов массива).
4. Строить каждый столбик, для чего использовать процедуру изображения прямоугольника, размеры которого определяются следующим образом: ширина стандартна для всех – это m, высота определяется индивидуально для каждого числа, например h=l*a[i].
5. Возле каждого столбика проставлять его числовое значение и порядковый номер (пользоваться функцией str).
Задача: Построить столбчатую диаграмму, если в исходном массиве есть еще и отрицательные числа.
{Пример построения столбиковой диаграммы}
program BarDiagram;
uses crt,graph;
{N - количество элементов исходных данных}
{Name - наименования элементов исходных данных}
{Num - числовые значения элементов исходных данных}
const
N=6;
Name:array[1..N] of string=('1997','1998','1999','2000','2001','2002');
Num:array[1..N] of integer=(10,5,8,11,2,7);
var
Dr,Rg,MaxX,MaxY,X0,Y0,S,I,X1,Y1,X2,Y2,S1:integer;
M:real;
Nm:string;
begin
{Инициализация графического режима}
Dr:=detect;
initgraph(Dr,Rg,'');
{Определение начальных параметров}
cleardevice; {Очистка экрана}
MaxX:=getmaxx; {Определение максимальной координаты по X}
MaxY:=getmaxy; {Определение максимальной координаты по Y}
X0:=40; {Отступ от края экрана до рамки по вертикали}
Y0:=20; {Отступ от края экрана до рамки по горизонтали}
S:=round((MaxX-4*X0)/N); {Определение ширины одного столбца}
X1:=2*X0+2; {Начальная координата по X для первого столбца}
Y1:=MaxY-2*Y0+2; {Конечная координата по Y для всех столбцов}
X2:=X0+2; {Координата по X для вывода значений слева оси Y}
{Рисование рамки}
setfillstyle(1,1);
bar(X0,Y0,MaxX-X0,MaxY-Y0);
setcolor(14);
rectangle(X0,Y0,MaxX-X0,MaxY-Y0);
{Рисование осей}
line(2*X0,2*Y0,2*X0,MaxY-2*Y0); {Ось Y}
line(2*X0,MaxY-2*Y0,MaxX-2*X0,MaxY-2*Y0); {Ось X}
{Поиск наибольшего из значений элементов исходных данных в переменную M}
M:=Num[1];
for I:=2 to N do
if Num[I]>M then
M:=Num[I];
S1:=round((MaxY-4*Y0)/M); {Определение длины единичного отрезка на оси Y}
{Рисование диаграммы}
for I:=1 to N do
begin
Y2:=2*Y0+(MaxY-2*Y0-S1*Num[I]); {Начальная координата по Y}
str(Num[I]:4,Nm);
outtextxy(X2,Y2,Nm); {Вывод значения элемента данных слева оси Y}
line(2*X0-3,Y2-3,2*X0,Y2-3); {Рисование деления на оси Y}
outtextxy(X1,Y1,Name[I]); {Вывод названия элемента данных под осью X}
setfillstyle(1,I+1); {Определение типа заполнения столбца}
bar(X1-1,Y2-3,X1-1+S,Y1-3); {Рисование столбца}
X1:=X1+S; {Начальная координата по Х для очередного столбца}
end;
repeat
until keypressed;
closegraph {Выход из графического режима}
end.
{Пример построения линейной диаграммы}
program LineDiagram;
uses crt,graph;
{N - количество элементов исходных данных}
{Name - наименования элементов исходных данных}
{Num - числовые значения элементов исходных данных}
const
N=6;
Name:array[1..N] of string=('1997','1998','1999','2000','2001','2002');
Num:array[1..N] of integer=(10,5,8,11,2,7);
var
Dr,Rg,MaxX,MaxY,X0,Y0,S,I,X1,Y1,X2,Y2,S1,X3,Y3,X4,Y4:integer;
M:real;
Nm:string;
begin
{Инициализация графического режима}
Dr:=detect;
initgraph(Dr,Rg,'');
{Определение начальных параметров}
cleardevice; {Очистка экрана}
MaxX:=getmaxx; {Определение максимальной координаты по X}
MaxY:=getmaxy; {Определение максимальной координаты по Y}
X0:=40; {Отступ от края экрана до рамки по вертикали}
Y0:=20; {Отступ от края экрана до рамки по горизонтали}
S:=round((MaxX-4*X0)/N); {Определение интервала между точками по X}
X1:=2*X0+2; {Координата по X для первой точки диаграммы}
Y1:=MaxY-2*Y0+2; {Координата по Y для вывода названий под осью Y}
X2:=X0+2; {Координата по X для вывода значений слева от оси Y}
{Рисование рамки}
setfillstyle(1,1);
bar(X0,Y0,MaxX-X0,MaxY-Y0);
setcolor(14);
rectangle(X0,Y0,MaxX-X0,MaxY-Y0);
{Рисование осей}
line(2*X0,2*Y0,2*X0,MaxY-2*Y0); {Ось X}
line(2*X0,MaxY-2*Y0,MaxX-2*X0,MaxY-2*Y0); {Ось Y}
{Поиск наибольшего из значений элементов исходных данных в переменную M}
M:=Num[1];
for I:=2 to N do
if Num[I]>M then
M:=Num[I];
S1:=round((MaxY-4*Y0)/M); {Определение длины единичного отрезка на оси Y}
{Рисование диаграммы}
for I:=1 to N do
begin
Y2:=2*Y0+(MaxY-2*Y0-S1*round(Num[I])); {Координата точки по Y}
X4:=X1-1; {Конечная координата линии по X}
Y4:=Y2-3; {Конечная координата линии по Y}
str(Num[I]:4,Nm);
outtextxy(X2,Y2,Nm); {Вывод значения элемента данных слева оси Y}
line(2*X0-3,Y2,2*X0,Y2); {Рисование деления на оси Y}
outtextxy(X1,Y1,Name[I]); {Вывод названия элемента данных под осью X}
setlinestyle(0,1,1); {Определение типа линии диаграммы}
circle(X4,Y4,2); {Рисование узлов диаграммы}
if I<>1 then
line(X3,Y3,X4,Y4); {Рисование линии диаграммы}
X3:=X1-1; {Начальная координата линии по X}
Y3:=Y2-3; {Начальная координата линии по Y}
X1:=X1+S; {Координата по X для очередной точки}
end;
repeat
until keypressed;
closegraph {Выход из графического режима}
end.
Самостоятельная работа: Построить линейчатую диаграмму, в исходном массиве только положительные элементы.
Построение круговой диаграммы.
{Пример построения круговой диаграммы}
program RoundDiagram;
uses crt,graph;
{N - количество элементов исходных данных}
{Name - наименования элементов исходных данных}
{Num - числовые значения элементов исходных данных}
const
N=6;
Name:array[1..N] of string=('1997','1998','1999','2000','2001','2002');
Num:array[1..N] of integer=(10,5,8,11,2,7);
var
Dr,Rg,MaxX,MaxY,Y0,I,S1,Kg,Xc,Yc,R,Yk:integer;
M,S:real;
begin
{Инициализация графического режима}
Dr:=detect;
initgraph(Dr,Rg,'');
{Определение начальных параметров}
cleardevice; {Очистка экрана}
MaxX:=getmaxx; {Определение максимальной координаты по X}
MaxY:=getmaxy; {Определение максимальной координаты по Y}
Xc:=300; {Координата центра диаграммы по X}
Yc:=250; {Координата центра диаграммы по Y}
R:=150; {Радиус диаграммы}
{Рисование рамки}
setfillstyle(1,1);
bar(0,0,MaxX,MaxY);
setcolor(14);
rectangle(0,0,MaxX,MaxY);
{Определение суммы значений элементов исходных данных в переменную S}
S:=0;
for I:=1 to N do
S:=S+Num[I];
{Рисование диаграммы}
Y0:=0; {Начальный угол сектора}
for I:=1 to N do
begin
Kg:=round(360*(Num[I]/S)); {Определение кол-ва градусов в секторе}
Yk:=Y0+Kg; {Конечный угол сектора}
if Yk>360 then
Yk:=360;
setfillstyle(1,I+1); {Определение типа заполнения сектора}
pieslice(Xc,Yc,Y0,Yk,R); {Рисование сектора}
Y0:=Yk {Начальный угол сектора}
end;
repeat
until keypressed;
closegraph {Выход из графического режима}
end.
Работа с файлами.
В задачах, которые мы рассматривали, данные поступали с клавиатуры, а результаты выводились на экран дисплея. Поэтому ни исходные данные, ни результаты не сохранялись. Приходилось заново вводить данные всякий раз, когда запускали программу. А если их очень много? Тогда удобно оформить исходные данные и результаты в виде файлов, которые можно хранить на диске точно так же, как и программы.
Файл - это область памяти на внешнем носителе, в которой хранится некоторая информация. В языке Паскаль файл представляет собой последовательность элементов одного типа. Мы будем работать только с файлами последовательного доступа. В таких файлах, чтобы получить доступ к элементу, необходимо последовательно просмотреть все предыдущие.
Объявление файловой переменной в разделе описания переменных имеет вид:
var <имя файла>: File of <тип элементов>;
Например:
var Ft: File of integer;
M: File of char;
Type File_integer=File of integer
File_char=File of char;
Var F1: File_integer;
F2: File_char;
Так как в описании указывается тип элементов, такие файлы называются типизированными. Все элементы файла пронумерованы начиная с нуля.
С каждым файлом связан так называемый файловый указатель. Это неявно описанная переменная, которая указывает на некоторый элемент файла.
| (0) | (1) | ... | (к) | (к+1) | ... | |
| Ý |
файловый указатель
Все операции производятся с элементом, который определен файловым указателем.
Связь переменной файлового типа
с файлом на диске.
Процедура Assign(<имя файловой пер-ой>,’<имяфайла на диске>’);
Например:
Assign(F1,’A:INT.DAT’);
После установления такого соответствия все операции, выполняемые над переменной F1, будут выполнятся над файлом, хранящимся на диске А и имеющим имя INT.DAT
Файл в каждый момент времени может находиться в одном из двух состояний: либо он открыт только для записи, либо только для чтения.
Чтение из файла.
Под чтением из файла понимается пересылка данных из внешнего файла, находящегося на диске, в оперативную память.
Для чтения из файла необходимо открыть для чтения посредством процедуры
Reset(<имя файловой переменной>);
Собственно чтение данных из файла выполняется процедурой
Read(<имя файловой переменной>,<имя переменной>);
Переменная должна иметь тот же тип, что и компоненты файла. Отметим, что если оператор ввода имеет вид Read(<имя переменной>), то данные вводятся с клавиатурой, а если Read(<имя файловой переменной>,<имя переменной>); то данные вводятся из файла, хранящегося на диске.
Закрытие файла
После того как данные из файла прочитаны, его необходимо закрыть посредством процедуры
Close(< имя файловой переменной>)
Общая схема чтения данных из файла, таким образом, следующая:
Reset(<имя файловой переменной>);
.......
Read(<имя файловой переменной>,<имя переменной>);
...........
Close(<имя файловой переменной>);
Признак конца файла
Так как число элементов файла не известно заранее, необходимо уметь определять, что файл кончился. Для этого используется логическая функция Eof(<имя файловой переменной>) (Eof - End Of File). Она принимает истинное значение (Тrue), если достигнут конец файла, и ложное (False) - в противном случае.
Пример Прочитаем из файла целые числа и выведем их на экран:
Assign(F1,’A:INT.DAT’);
Reset(F1);
While Not Eof(F1) do
begin
read(f1,n); { считываем очередное число из файла}
write(n,’ ‘); { выводим его на экран}
end;
Close(F1);
Запись в файл
Под записью в файл понимается вывод результатов программы из оперативной памяти ЭВМ в файл на диске.
Для записи в файл необходимо открыть файл для записи посредством процедуры
Rewrite(< Имя файловой переменной >);
Собственно запись данных в файл выполняется процедурой:
Write(< имя файловой переменной >,< значение >);
Общая схема записи данных в файл, таким образом, следующая:
Rewrite(<>);
......
Write(<имя файловой переменной>,<значение>);
..........
Close(<имя файловой переменной>);
Прямой доступ к элементам файла
Несмотря на то, что в стандартном Паскале имеются лишь файлы последовательного доступа, Турбо Паскаль содержит процедуры и функции для более эффективной работы с файлами. В частности, имеется возможность осуществлять прямой доступ к элементам файла.
Установка указателя.
Процедура Seek(<имя файловой переменной>,N) устанавливает файловый указатель на N-й элемент. Например, Seek(F1,3). (на 4 элемент)
Определение номера элемента
Функция FilePos(<имя файловой переменной>) возвращает номер элемента, на который «смотрит» файловый указатель.
Определение количества элементов в файле
Функция FileSize(<имя файловой переменной>) возвращает количество элементов в файле.
Удаление и переименование файлов
Erase(<имя файловой переменной>) процедура удаления файла.
Rename(<имя файловой переменной>,’<новое имя на диске>’) переименование файла.
Пример: В файле DAT1.DAT записаны целые числа. Вычислить сумму элементов файла и результат вместе с исходными данными записать в файл DAN2.DAT
Program WW;
Var f1,f2: file of integer;
s, n: integer;
begin
Assign(f1,’DAT1.DAT’);
Reset(F1);
Assign(f2,’DAT2.DAT’);
Rewrite(f2);
s:=0;
While Not Eof(f1) do { проверка на конец файла}
begin
read(f1,n); {чтение элемента из файла F1}
write(f2,n); { запись элемента в файл F2}
s:=s+n;
end;
write(f2,s); {запись суммы элементов в конец файла F2}
write(‘Результат находится в файле DAT2.DAT’);
Close(f1);
Close(f2);
end.
Текстовые файлы
Текстовые файлы состоят из символьных строк. Строки могут иметь различную длину, и в конце каждой строки стоит признак конца строки. Для описания текстовых файлов используется служебное слово Text:
Var A: Text;
Для обработки текстовых файлов используются те же процедуры и функции, что и для обработки обычных типизированных файлов. Для связывания файловой переменной с файлом на диске употребляется процедура Assign. Текстовые файлы могут быть открыть для чтения процедурой Reset или для записи процедурой Rewrite.
Для чтения данных применяется процедура Read. Если необходимо после чтения данных перейти на следующую строку, то используется процедура Readln. Если необходимо просто перейти к следующей строке, то можно использовать процедуру Readln(<имя файловой переменной текстового файла>); которая устанавливает файловый указатель на первый элемент следующей строки.
Процедура Write записывает данные в текущую строку. Если надо записать данные и перейти к следующей строке, то можно использовать процедуру Writeln. Если требуется только перейти для записи на новую строку, то применяется процедура Writeln(<имя файловой переменной текстового файла>); которая записывает в файл признак конца строки и устанавливает файловый указатель на начало следующей строки.
Так как в строках может быть разное количество символов, имеется логическая функция Eoln(<имя файловой переменной текстового файла>), которая принимает значение True, если достигнут конец строки.
Процедура Append(<имя файловой переменной текстового файла>). Она открывает файл для «дозаписи», помещая файловый указатель в конец файла.
Пример: Дан текстовый файл, содержащий только целые числа, в каждой строке может быть несколько чисел, которые разделяются пробелами. Вывести на экран все числа с учетом разбиения на строки и подсчитать количество элементов в каждой строке.
Решение: Пусть в файле содержится следующая информация:
-32 16 0 8 7
4 5 9 13 11 -5 -8
6 -8 0 -12
5 4 3 2 1 12
1 2
Этот файл можно создать в среде Турбо Паскаль следующим образом:
· создайте новый файл посредством команды New меню File;
· запишите все числа, разделяя их пробелами, и разбейте на строки, как указано в задании;
· сохраните файл, например, под именем INT1.DAT
теперь напишем программу
program rrr;
var f: text;
x, k: integer;
begin
Assign(f,’int1.dat’);
Reset(f);
While Not Eof(f) do {пока не достигнут конец файла}
begin
k:=0;
While Not Eoln(f) do {пока не достигнут конец строки}
begin
read(f,x); {считываем очередное число}
write(x,’ ‘); {выводим его на экран}
Inc(k); {увеличиваем счетчик}
end;
writeln(‘в строке’, k, ‘ элементов’);
Readln(f) {переходим к следующей строке файла}
end;
Close(f);
end.
Пример. Записать двумерный массив вещественных чисел 5х4 в тестовый файл.
Program mas;
const m=5; n=4;
Var fil: text;
a: real;
s: char;
i,j: integer;
begin
Assign(fil,’massiv.txt’);
Rewrite(fil);
for i:=1 to m do
begin
for j:=1 to n do
begin
a:=random(100);
write(fil,a:5:3,’ ‘); {число записывается в файл в указанном формате, за ним пробел}
end;
writeln(fil); {переход в файле на новую строку}
end;
Close(fil);
{Чтение файла и вывод матрицы на экран по строкам}
Reset(fil); {открытие уже имеющегося файла}
while not Eof(fil) do
begin
while not Eoln(fil) do
begin
read(fil,a); {чтение числа}
write(a:5:3);
read(fil,s); { чтение пробела после числа}
write(s);
end;
writeln;
readln(fil);
end;
Close(fil);
end.
Пример. Дан текстовый файл f. Переписать в файл g все компоненты исходного файла f в обратном порядке.
program tofile;
var f, g: text;
n, i, j: integer;
s: string;
x: array [1..32000] of char;
begin
assign(f,’f.txt’); assign(g,’g.txt’);
rewrite(g); rewrite(f);
writeln(‘Введите число строк в создаваемом вами файле ‘);
readln(n);
writeln(‘вводите строки, после введения каждой нажмите Enter’);
for i:=1 to n do begin readln(s); write(f,s); end;
reset(f);
i:=0;
writeln(‘Исходный файл:’);
while(not eof(f)) and (i<32000) do
begin i:=i+1; read(f,x[i]); write(x[i]); end;
writeln;
writeln(‘Измененный файл:’);
for j:=i downto 1 do
begin write(g,x[j]); write(x[j]); end;
writeln;
close(f); close(g);
end.
Задача. Дан текстовый файл. Вставить в начало каждой строки ее номер и записать преобразованные строки в новый файл.
Задача. Даны два текстовых файла. Записать в третий файл только те строки, которые есть и в первом, и во втором файлах.
Запись.
При использовании массивов основное ограничение заключается в том, что все элементы должны иметь один и тот же тип. Но при решении многих задач возникает необходимость хранить и обрабатывать совокупность данных различного типа.
Пусть известны фамилии и оценки (в баллах) по пяти дисциплинам каждого из двадцати пяти учеников класса. Требуется вычислить среднюю оценку каждого из учеников и выбрать человека, имеющего максимальный средний балл.
В данном случае фамилия может быть представлена символьной строкой, оценки - это целые числа, а средний балл должен быть представлен вещественным числом. В Паскале для описания объектов, содержащих данные разных типов, используются записи.
Запись - это структурированный тип, описывающий набор данных разных типов. Составляющие запись объекты называются ее полями. Каждое поле имеет уникальное (в пределах записи) имя. Чтобы описать запись, необходимо указать ее имя, имена объектов, составляющих запись, и их типы.
Общий вид описания записи:
Type <имя записи> = Record
<поле 1>: <тип 1>;
<поле 2>: <тип 2>
<поле n>: <тип n>
End;
Применительно к рассматриваемой задаче запись можно описать так:
Type
pupil = Record
fam: string[15]; {поле фамилии}
b1,b2,b3,b4,b5: 2..5; {поля баллов}
sb: Real {средний бал}
End;
Чтобы хранить в памяти ЭВМ информацию обо всех 25 учениках класса, необходимо ввести массив klass - массив записей.
Var klass: array[1..25] Of pupil;
Доступ к полям записи можно осуществить двумя способами:
1. С указанием имени переменной и имени поля. Например, klass[2].fam, klass[3].sb, klass[1].b4
Ввод фамилий и оценок учащихся, т.е. элементов массива klass, можно записать так:
for i:=1 to 25 do
begin
readln(klass[i].fam);
readln(klass[i].b1);
readln(klass[i].b2);
readln(klass[i].b3);
readln(klass[i].b4);
readln(klass[i].b5);
end;
2. С использованием оператора присоединения.
Имеется возможность осуществлять доступ к полям записи таким образом, как если бы они были простыми переменными. Общий вид оператора присоединения:
With <имя записи> Do <оператор>;
Внутри оператора присоединения к компонентам записи можно обращаться только с помощью имени соответствующего поля.
Пример
for i:=1 to 25 do
With klass[i] do
begin
readln(fam);
readln(b1,b2,b3,b4,b5);
end;
Программа для решения рассматриваемой задачи может быть записана следующим образом:
program zap;
Type pupil = Record
fam: string[15]; {поле фамилии}
b1,b2,b3,b4,b5: 2..5; {поля баллов}
sb: Real {средний бал}
End;
Var klass: array[1..25] Of pupil;
p: pupl;
i,m: integer;
sbmax: real;
begin
for i:=1 to 25 do
with klass[i] do
begin
writeln(‘Введите фамилию и пять оценок’);
readln(fam);
readln(b1,b2,b3,b4,b5);
end;
for i:=1 to m do {вычисление среднего балла}
with klass[i] do sb:=(b1+b2+b3+b4+b5)/5;
sbmax:=0;
{ поиск максимального среднего балла}
for i:=1 to m do
if klass[i].sb>=sbmax then sbmax:=klass[i].sb;
for i:=1 to m do {печать результатов}
if klass[i].sb=sbmax
then with klass[i] do writeln(fam:20,’ - ‘, sb:6:3);
end.
Пример. Определите дату завтрашнего дня.
Чтобы определить дату завтрашнего дня, надо знать не только дату сегодняшнего дня, но и количество дней в данном месяце (так как если это последний день месяца, то завтра будет первый день следующего), кроме того, надо знать, какой год - високосный или нет.
Пусть дата вводится в формате число - месяц - год следующим образом:
1 2 1997
Опишем запись для хранения даты таким образом:
Type year=1500..2000;
month=1..12;
day=1..31;
data = Record
y: year;
m: month;
d: day;
end;
Заметим, что:
· если дата соответствует не последнему дню месяца, то год и месяц не изменяются, а число увеличивается на 1;
· если дата соответствует последнему дню месяца, то:
а) если месяц не декабрь, то год не изменяется, месяц увеличивается на 1, а число устанавливается в 1;
б) если месяц - декабрь, то год увеличивается на 1, а месяц и число устанавливаются в 1.
Program datanext;
Type year=1500..2000;
month=1..12;
day=1..31;
data = Record
y: year;
m: month;
d: day;
end;
Var dat, next: data;
Function leap(yy:year):boolean; {функция определяет
високосный ли год}
begin
leap:=(yy Mod 4=0) And (yy Mod 400 <>0);
end;
Function Dmonth(mm:month; yy: year): day; {функция определения
количества дней данного месяца в данном году}
begin
case mm of
1,3,5,7,8,10,12: Dmonth:=31;
4,6,9,11: Dmonth:=30;
2: if leap(yy) then Dmonth:=29 else Dmonth:=28;
end;
end;
procedure Tomorrow(td: data; var nd: data); {опр-ние завтрашней даты}
begin {если это не последний день месяца}
if td.d<> Dmonth(td.m, td.y) then
with nd do
begin
d:=td.d+1;
m:=td.m;
y:=td.y;
end;
else {если это последний день месяца}
if td.m=12 then {если это декабрь}
with nd do
begin
d:=1;
m:=1;
y:=td.y+1;
end;
else { если это не декабрь}
with nd do
begin
d:=1;
m:=td.m+1;
y:=td.y;
end;
end;
BEGIN
writeln(‘Введите сегодняшнее число, месяц и год’);
readln(dat.d, dat.m, dat.y);
Tomorrow(dat,next);
writeln(‘завтра будет’);
writeln(next.d, ‘.’, next.m, ‘.’, next.y);
END.
Задачи:
13.1 Фамилии и имена 25 учеников класса записаны в двух различных таблицах. Напечатать фамилию и имя каждого ученика на отдельной строке.
13.2 Названия 20 футбольных клубов и городов, которые они представляют, записаны в двух различных таблицах. Напечатать название и город каждого клуба на отдельной строке.
13.3 Даны названия 26 городов и стран, в которых они находятся. Среди них есть города, находящиеся в Италии. Напечатать их названия.
13.4 Известны данные о 16 сотрудниках фирмы: фамилия и отношение к воинской службе (военнообязанный или нет). Напечатать фамилии всех военнообязанных сотрудников.
13.5 Известны данные о мощности двигателя (в л.с.) и стоимость 30 легковых автомобилей. Определить общую стоимость автомобилей, у которых мощность двигателя превышает 100 л.с.
13.6 Известны данные о цене и тираже каждого из 15 журналов. Найти среднюю стоимость журналов, тираж которых меньше 10000 экземпл.
13.7 Известны данные о массе и объеме 30 чел, изготовленных из различных материалов. Определить максимальную плотность материала тел.
13.8 Известны вес, пол, рост каждого из 22 человек. Найти общую массу и средний рост мужчин.
13.9 Известно количество очков, набранных каждой из 20 команд - участниц первенства по футболу. Ни одна пара команд не набрала одинакового количества очков.
а) Определить название команды, ставшей чемпионом.
б) Определить названия команд, занявших второе и третье места.
в) Определить названия команд, занявших первое и второе места, не используя при этом двух операторов цикла (два прохода по массиву).
г) Вывести названия команд в соответствии с занятыми ими местами в чемпионате.
13.10 Известны оценки каждого из 25 учеников класса по десяти предметам. Найти фамилию одного из учеников:
а) имеющих наибольшую сумму оценок;
б) имеющих наименьшую сумму оценок.
13.11 Известны баллы, набранные каждым из 20 спортсменов-пятиборцев в каждом из пяти видов спорта. Определить фамилию спортсмена - победителя соревнований.
13.12 Известны данные о 20 учениках класса: фамилии, имена, отчества, даты рождения (год, номер месяца и число). Определить, есть ли в классе ученики, у которых сегодня день рождения, и если да, то напечатать имя и фамилию каждого.
Повторение: Решить следующую задачу: Существует фирма, которая организует работу на контрактной основе, то есть если для какого-либо специалиста есть работа он нанимается, по окончания работы он увольняется, причем буквально на следующий день его могут нанять снова. Дан файл в котором хранится вся информация по рабочим за год, причем общее количество рабочих неизвестно. Она выглядит следующим образом: в первой строке записана фамилия рабочего, на следующей строке день и месяц его найма, на третьей – день и месяц окончания работы. Необходимо:
а) вывести на экран список рабочих напротив каждой фамилии каждого указано количество дней его работы, причем если рабочий был нанят несколько раз, то и в списке его фамилия фигурирует несколько раз.
б) вывести на экран список рабочих и у каждого указать общее количество рабочих дней за год.
в) сформированный в предыдущем пункте список отсортировать по убыванию количества рабочих дней.
Двоичный и к-ичный перебор.
Метод двоичного перебора применяется в тех случаях, когда требуется организовать перебор всевозможных подмножеств данного множества (множество в Паскале представляет собой набор различных элементов одного типа). То есть если есть набор каких-либо элементов, то из него мы можем выбирать элементы в любых сочетаниях, и в любых количествах (например, группа людей в количестве ну для определенности пяти человек, собирается на прогулку, при этом они в итоге могут пойти все, а если вдруг испортилась погода, то может не пойти вообще никто, а могут собраться двое, трое и т.д.).
Очевидно, что каждый элемент из рассматриваемого множества может иметь только два состояния (включен или не включен, активен или не активен, есть или нет). Получаем, что каждый элемент может иметь только два значения именно поэтому данный метод, и является двоичным.
В качестве модели рассмотрим массив из n элементов, каждый из которых может принимать только два значения (каждый элемент массива соответствует какому-то одному объекту множества), следовательно, получаем, что элемент массива может принимать только два значения: 0 – не выбран или 1 - выбран, то есть данный объект множества включен в подмножество.
Задача сводится к тому, чтобы перебрать все возможные комбинации 0 и 1, в результате чего учитываются все варианты, при этом они не должны повторяться. Для определенности рассмотрим множество, состоящее из пяти элементов. Вначале в массив запишем пять нулей: (0, 0, 0, 0, 0). Эти нули соответствуют начальному состоянию множества, заключающееся в том, что выбранных объектов нет (то есть пустое множество).
На первом шаге обработки массива, увеличим на единицу последний элемент массива, то есть, получаем следующее подмножество (0, 0, 0, 0, 1). Тем самым мы получили новый возможный вариант комплектации массива, в котором выбран последний пятый элемент.
На втором шаге снова увеличиваем последний элемент массива на единицу, при этом получаем что он равняется двойке, что невозможно по условию формирования массива, следовательно последний элемент необходимо занулить, а на единицу увеличиваем предыдущий элемент, то есть четвертый, получаем (0, 0, 0, 1, 0). Этот вариант соответствует тому, что выбран только четвертый объект множества.
На третьем шаге снова увеличиваем последний элемент массива на единицу, получаем (0, 0, 0, 1, 1). Что соответствует тому, что выбраны уже четвертый и пятый объект некоторого множества.
На четвертом шаге снова увеличиваем последний элемент массива на единицу, и он у нас в итоге равняется двойке, что невозможно, поэтому мы его зануляем, а на единицу увеличиваем предыдущий разряд, при этом он так же обращается в двойку, необходимо и его занулить, а на единицу увеличить третий элемент массива, в результате получаем такой вариант (0, 0, 1, 0, 0). Следовательно, во множестве выбран только третий объект.
И таким образом происходит перебор всех возможных вариантов формирования множества состоящего из нулей и единиц. Последний возможный вариант для нашего множества, это все единицы (1, 1, 1, 1, 1). Что соответствует выбору всех объектов рассматриваемого множества. Предположим, что мы не остановились на этом этапе и продолжили увеличивать наш массив, то есть на единицу увеличиваем последний элемент массива, при этом он обращается в двойку, мы его зануляем и переносим единицу в предыдущий разряд, и в нем получаем двойку, снова зануляем и переносим, и это продолжается до тех пор, пока мы не оказываемся в позиции первого элемента, который также обращается в двойку, которую необходимо занулить а единицу перенести в предыдущий разряд, то есть в нулевой, который в обычном используемом нами массиве не фигурирует. Следовательно, в данном случае нам необходимо определить позицию нулевого элемента массива для определения окончания перебора всех возможных вариантов формирования массива из нулей и единиц. То есть в начале мы формирует массив из всех нулей, в том числе ноль находится и в нулевом разряде, после того как нами перебраны все варианты, и единицы находятся во всех позициях кроме нулевой мы делаем следующий шаг и получаем нули во всех позициях кроме нулевой, там находится единица, вот именно эта единица и будет служить для нас окончанием перебора всевозможных вариантов. В результате перебора мы должны получить 2n вариантов, где n – количество элементов массива. Для успешной работы программы n не может быть бесконечно, при n>20 на обработку данных программе требуется уже очень много времени.
Алгоритм решения задачи с использованием двоичного перебора:
1. Ввести исходные данные (если в этом есть необходимость).
2. Сформировать нулевой вектор с номерами элементов от 0 до n.
3. Обработать этот вектор.
4. Сформировать новый вектор.
5. Если нулевой разряд вектора равен 0, то повторить третий пункт, иначе закончить.
Задача 1: Вывести на экран всевозможные наборы 0 и 1 и их порядковые номера.
program primer;
uses crt;
var p: array [0..30] of byte;
n, i, k: integer;
procedure vector;
begin
i:=n;
while p[i]=1 do begin
p[i]:=0;
dec(i);
end;
p[i]:=1;
end;
procedure work;
begin
inc(k);
write (k:3,’: ‘);
for i:=1 to n do
write (p[i]);
writeln;
end;
begin
clrscr;
writeln (‘Введите n’);
readln (n);
k:=0;
for i:=0 to n do p[i]:=0;
repeat
work;
vector;
until p[0]=1;
readln;
end.
Задачи:
1. Даны n различных цифр, получить из них всевозможные числа, при условии, что в числе цифры не повторяются.
2. Даны n различных букв, получить все возможные слова из них при условии что буквы в словах не повторяются.
3. Имеется n монет разного достоинства, определить, можно ли получить задуманную сумму денег, данными монетами. Если вариантов несколько, то вывести их все на экран, а если их нет, то сообщить об этом.
4. Имеется n камней (известна их масса), разложить эти камни на две кучки так, чтобы массы этих кучек отличались друг от друга как можно меньше (в идеале совпадали).
5. Даны две строки, определить может ли первая строка быть получена путем зачеркивания элементов второй.
6. Известны массы n гирек. определить, можно ли заданный груз взвесить этими гирьками. Если можно, то указать наилучший (по числу используемых гирек) способ взвешивания. Задачу решить для двух случаев: а) груз на одной чаше весов, гирьки на другой; б) гирьки могут находиться на обеих чашках весов.
Контрольная работа:
1. Дан ряд цифр 1, 2, 3, 4, 5, 6, 7, 8, 9. Можно ли получить данное число s, расставляя между цифрами знаки + и -. Если можно то указать способ расстановки знаков. (Тесты: s=45 1+2+3+4+5+6+7+8+9; s=2 нельзя (любое четное нельзя); s=1 1-2-3-4+5-6-7+8+9 (12 вариантов); s=47 нельзя; s=31 1+2+3+4+5+6-7+8+9 (3 варианта).
2. Известно количество страниц в каждом из n произведений. определить можно ли распределить эти произведения на 3 тома так, чтобы все тома оказались одинаковыми. Если можно, то вывести один из вариантов распределения. (Тесты: n=6 (7, 10, 4, 8, 2, 5) можно (7+5, 8+4, 10+2); n=5 (5, 4, 6, 3, 8) нельзя; n=3 (5, 5, 5) можно (5, 5, 5); n=8 (5, 4, 3, 4, 2, 1, 6, 5) можно (по 10); n=6 (3, 3, 3, 3, 3, 5) нельзя).
3. Известны массы n камней. Распределить камни на три кучки так, чтобы массы самой легкой и самой тяжелой кучки отличались минимально. в идеале совпадали.
Генерация перестановок.
Предположим, что нам дана такая задача: Вывести на экран все перестановки чисел 1..n (то есть последовательности длины n, в каждую из которых каждое из чисел 1..n входит по одному разу).
Для определенности рассмотрим пример при n=5.
Изначально имеем такую расстановку чисел 1 2 3 4 5.
На первом шаге поменяем местами два последних элемента, получим 1 2 3 5 4.
Дальше начнем искать первый с конца элемент, который будет меньше следующего за ним (5>4, а вот 3<5). Следовательно, таким элементом будет тройка, стоящая на третьей позиции. Теперь необходимо найти самый правый элемент больший, чем этот (5>3, но правее стоит 4, и она тоже больше тройки), следовательно таким элементом будет четверка стоящая на пятой позиции. Меняем их местами. Получили такую перестановку: 1 2 4 5 3. при этом хвост массива, то есть элементы, стоящие на двух последних местах оказались упорядоченными по убыванию, поэтому если мы ничего не изменим, то они так и останутся навсегда на своих местах, и тем самым мы потеряем некоторые варианты, для того чтобы этого не произошло, переставим их в порядке возрастания, и только после этого будем считать, что мы нашли новый, третий по счету вариант перестановки: 1 2 4 3 5.
Теперь опять начинаем просматривать массив с конца в поисках первой пары элементов, из которых левый меньше правого, а также самый правый элемент больший этого левого (3<5, и при этом 5 самый правый), следовательно, необходимо поменять их местами
{Этот алгоритм хорошо известен и достаточно подробно изложен. Опишем его (при N=5), от чего рассуждения не утратят общности. Алгоритм составлен так, что в процессе его исполнения перестановки N чисел располагаются лексикографически (в словарном порядке). Это значит, что перестановки сравниваются слева направо поэлементно. Больше та, у которой раньше встретился элемент, больше соответствующего ему элемента во второй перестановке. (Например, если S=(3,5,4,6,7), а L=(3,5,6,4,7), то S<L).
Принцип работы алгоритма разъясним на примере. Допустим, необходимо воспроизвести все перестановки цифр 3,4,5,6,7. Первой перестановкой считаем перестановку (3,4,5,6,7). Последней воспроизводимой перестановкой будет (7,6,5,4,3). Предположим, что на некотором шаге работы алгоритма получена перестановка
P=(5,6,7,4,3).
Для того чтобы определить непосредственно следующую за ней перестановку, необходимо, пересматривая данную перестановку справа налево, следить за тем, чтобы каждое следующее число было больше предыдущего, и остановиться сразу же, как только это правило нарушится. Место останова указано стрелкой:
(5,6,7,4,3).
Затем вновь просматриваем пройденный путь (справа налево) до тех пор, пока не дойдем до первого числа, которое уже больше отмеченного. Ниже место второго останова отмечено двойной стрелкой.
(5,6,7,4,3).
Поменяем местами, отмеченные числа:
(5,7,6,4,3).
Теперь в зоне, расположенной справа от двойной стрелки, упорядочим все числа в порядке возрастания. Так как до сих пор они были упорядочены по убыванию, то это легко сделать, перевернув указанный отрезок. Получим: Q=(5,7,3,4,6).
Q и есть та перестановка, которая должна воспроизводиться непосредственно после P.
Действительно, P<Q, так как, пересматривая эти перестановки слева направо, (P(2)=6,Q(2)=7). Пусть существует такая перестановка R, что P<R<Q. Тогда P(1)=R(1)=Q(1). По построению же Q(2) – это наименьшее во множестве Q\Q(1)={3,4,6,7} число, такое, что Q(2)>P(2). Поэтому для R(2) верно одно из двух равенств: R(2)=Q(2) или R(2)=P(2). Но так как в P элементы, начиная с P(3), убывают, то из P<R следует, что если P(2)=R(2), то и P=R. Аналогично, так как в Q элементы, начиная с Q(3), возрастают, то из R<Q следует, что если R(2)=Q(2), то и R=Q.}
Алгоритм генерации перестановок:
1. Просматриваем a1,.., an с кона до тех пор, пока не попадется ai<ai+1. если таковых нет, значит, генерация закончена.
2. Рассматриваем ai+1, …, an. Находим первый с конца am>ai и меняем их местами.
3. ai+1, ai+2, …, an переставим в порядке возрастания.
4. Выводим найденную перестановку.
5. Возвращаемся к первому пункту.
В результате всех перестановок, всевозможных вариантов должно получиться n!, где n – количество элементов рассматриваемого массива.
Первой должна быть перестановка 1 2 3 …n, а последней n n-1…2 1.
program perest;
uses crt;
var
a: array [1..20] of byte;
i, j, k, n, kol, z: integer;
procedure form;
begin
i:=n-1;
while (i>0) and (a[i]>a[i+1]) do dec(i);
if i>0 then begin
j:=n;
while a[j]<a[i] do dec(j);
z:=a[i]; a[i]:=a[j]: a[j]:=z;
for k:=i+1 to (i+1+n) div 2 do begin
z:=a[k];
a[k]:=a[n-k+i+1];
a[n-k+i+1]:=z;
end;
end;
end;
procedure obr;
begin
for i:=1 to n do
write (a[i], ‘ ‘);
writeln;
inc(i);
end;
begin
clrscr;
writeln(‘Введите количество элементов');
readln(n);
for i:=1 to n do
a[i]:=i;
repeat
obr;
form;
until i=0;
writeln(‘Количство вариантов’, kol);
readln;
end.
Задачи:
1. Вывести на экран все перестановки последовательности n различных букв: абвгд…
2. Письма на удачу вкладываются в подписанные конверты. Определить количество раскладок, когда ни одно из n писем не попадает к своему адресату.
3. Вывести на экран все перестановки из n различных букв при условии, что гласные буквы не могут стоять рядом. Определить количество таких перестановок.
4. В ряд выкладываются b белых шаров, s синих шаров и k красных шаров. Определить количество расстоновок шаров, если шары одинакового цвета не могут стоять рядом. вывести эти расстановки на экран.
5. Расстаивть n ладей на поле размером n´n так, чтобы они не били друг друга. Определить количество таких расстановок.
6. Расставить n ферзей на шахматной доске размером n´n так, чтобы они не били друг друга. Определить количество таких расстановок.
7. Имеется n юношей и n девушек. Некоторые юноши знакомы с некотрыми девушками. Определить максимальное число возможных браков между ними, если известно, что браки могут заключаться только между знакомыми людьми, а многоженство и многомужество запрещены.
Поиск в графе.
Определим граф как конечное множество вершин V и набор E неупорядоченных и упорядоченных пар вершин и обозначим G=(V,E). Мощности множеств V и E будем обозначать буквами N и M. Неупорядоченная пара вершин называется ребром, а упорядоченная пара - дугой. Граф, содержащий только ребра, называется неориентированным; граф, содержащий только дуги, - ориентированным, или орграфом. Вершины, соединенные ребром, называются смежными. Ребра, имеющие общую вершину, также называются смежными. Ребро и любая из его двух вершин называются инцидентными. Говорят, что ребро (u, v) соединяет вершины u и v. Каждый граф можно представить на плоскости множеством точек, соответствующих вершинам, которые соединены линиями, соответствующими ребрам. В трехмерном пространстве любой граф можно представить таким образом, что линии (ребра) не будут пересекаться.
Способы описания. Выбор соответствующей структуры данных для представления графа имеет принципиальное значение при разработке эффективных алгоритмов. При решении задач используются следующие четыре основных способа описания графа: матрица инциденций; матрица смежности; списки связи и перечни ребер. Мы будем использовать только два: матрицу смежности и перечень ребер.
Матрица смежности - это двумерный массив размерности N*N.
A[i,j]= 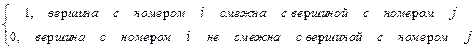
Для хранения перечня ребер необходим двумерный массив R
размерности M*2. Строка массива описывает ребро.
Множество алгоритмов на графах требует просмотра вершин графа. Рассмотрим их.
Поиск в глубину
Идея метода. Поиск начинается с некоторой фиксированной вершины v. Рассматривается вершина u, смежная с v. Она выбирается. Процесс повторяется с вершиной u. Если на очередном шаге мы работаем с вершиной q и нет вершин, смежных с q и не рассмотренных ранее (новых), то возвращаемся из вершины q к вершине, которая была до нее. В том случае, когда это вершина v, процесс просмотра закончен. Очевидно, что для фиксации признака, просмотрена вершина графа или нет, требуется структура данных типа:
Nnew: array[1..N] of boolean.
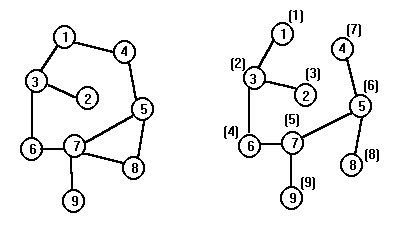
|
Пример. Пусть граф описан матрицей смежности A. Поиск начинается с первой вершины. На левом рисунке приведен исходный граф, а на правом рисунке у вершин в скобках указана та очередность, в которой вершины графа просматривались в процессе поиска в глубину.
Логика.
procedure Pg(v:integer);{Массивы Nnew и A глобальные}
var j:integer;
begin
Nnew[v]:=false; write(v:3);
for j:=1 to N do if (A[v,j]<>0) and Nnew[j] then Pg(j);
end;
Фрагмент основной логики.
...
FillChar(Nnew,SizeOf(Nnew),true);
for i:=1 to N do if Nnew[i] then Pg(i);
...
В силу важности данного алгоритма рассмотрим его нерекурсивную реализацию. Глобальные структуры данных прежние: A - матрица смежностей; Nnew - массив признаков. Номера просмотренных вершин графа запоминаются в стеке St, указатель стека - переменная yk.
procedure PG1(v:integer);
var St:array[1..N] of integer;yk:integer;t,j:integer;pp:boolean;
begin
FillChar(St,SizeOf(St),0); yk:=0;
Inc(yk);St[yk]:=v;Nnew[v]:=false;
while yk<>0 do begin {пока стек не пуст}
t:=St[yk]; {выбор “самой верхней“ вершины из стека}
j:=0;pp:=false;
repeat
if (A[t,j+1] <>0) and Nnew[j+1] then pp:=true
else Inc(j);
until pp or (j>=N); {найдена новая вершина или все вершины, связанные с данной вершиной, просмотрены}
if pp then begin
Inc(yk);St[yk]:=j+1;Nnew[j+1]:=false;{добавляем в стек}
end
else Dec(yk); {“убираем” вершину из стека}
end;
end;
Поиск в ширину
Идея метода. Суть (в сжатой формулировке) заключается в том, чтобы рассмотреть все вершины, связанные с текущей. Принцип выбора следующей вершины - выбирается та, которая была раньше рассмотрена. Для реализации данного принципа необходима структура данных “очередь”.
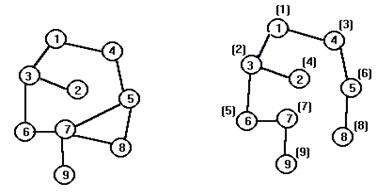
|
Пример. Исходный граф на левом рисунке. На правом рисунке рядом с вершинами в скобках указана очередность просмотра вершин графа.
Приведем процедуру реализации данного метода обхода вершин графа.
Логика просмотра вершин.
procedure PW(v:integer);
var Og:array[1..N] of 0..N; {очередь}
yk1,yk2:integer; {указатели очереди, yk1 - запись; yk2 - чтение}
j:integer;
begin
FillChar(Og,SizeOf(Og),0);yk1:=0;yk2:=0;{начальная инициализация}
Inc(yk1);Og[yk1]:=v;Nnew[v]:=false;{в очередь - вершину v}
while yk2<yk1 do begin {пока очередь не пуста}
Inc(yk2);v:=Og[yk2];write(v:3);{“берем” элемент из очереди}
for j:=1 to N do {просмотр всех вершин, связанных с вершиной v}
if (A[v,j]<>0) and Nnew[j] then begin{если вершина ранее не просмотрена}
Inc(yk1);Og[yk1]:=j;Nnew[j]:=false;{заносим ее в очередь}
end;
end;
end;
Решение комбинаторных задач.
Задачи дискретной математики, к которым относится большинство олимпиадных задач по информатике, часто сводятся к перебору различных комбинаторных конфигураций объектов и выбору среди них наилучшего, с точки зрения условия той или иной задачи. Поэтому знание алгоритмов генерации наиболее распространенных комбинаторных конфигураций является необходимым условием успешного решения олимпиадных задач в целом. Важно также знать количество различных вариантов для каждого типа комбинаторных конфигураций, так как это позволяет реально оценить вычислительную трудоемкость выбранного алгоритма решения той или иной задачи на перебор вариантов и, соответственно, его приемлемость для решения рассматриваемой задачи, с учетом ее размерности. Кроме того, при решении задач полезным оказывается умение для каждой из комбинаторных конфигураций выполнять следующие операции: по имеющейся конфигурации получать следующую за ней в лексикографическом порядке; определять номер данной конфигурации в лексикографической нумерации всех конфигураций; и, наоборот, по порядковому номеру выписывать соответствующую ему конфигурацию.
Перечисленные подзадачи в программировании обычно рассматривают для следующих комбинаторных конфигураций: перестановки элементов множества, подмножества множества, сочетания из n элементов множества по k элементов (k -элементные подмножества множества, состоящего из n ³ k элементов), размещения (упорядоченные подмножества множества, то есть отличающиеся не только составом элементов, но и порядком элементов в них), разбиения множества (множество разбивается на подмножества произвольного размера так, что каждый элемент исходного множества содержится ровно в одном подмножестве), разбиения натуральных чисел на слагаемые, правильные скобочные последовательности (различные правильные взаимные расположения n пар открывающихся и закрывающихся скобок).
Большинство указанных конфигураций были подробно рассмотрены в [1-3]. Однако при генерации различных конфигураций использовались в основном нерекурсивные алгоритмы. Опытные же участники олимпиад в подобных случаях при программировании используют в основном именно рекурсию, с помощью которой решение рассматриваемых задач зачастую можно записать более кратко и прозрачно. Поэтому для полноты изложения данной темы приведем ряд рекурсивных комбинаторных алгоритмов и рассмотрим особенности применения рекурсии в комбинаторике.








