 2015-10-22
2015-10-22 2790
2790Одной из наиболее трудных задач, возникающих в процессе моделирования, является определение значений показателей: цены информации, уровня угрозы и вероятности ее реализации, затрат на предотвращение угроз. Такая проблема возникает при решении любых слабоформализуемых задач. Поэтому ей уделяется постоянное внимание, хотя до ее решения еще далеко. Отсутствие однозначной зависимости результата решения слабоформализуемой задачи от исходных данных, их неопределенность и недостоверность существенно затрудняют использование традиционного математического аппарата. Более того, часто этого не следует делать, так как при недостоверных исходных данных можно получить результат, далекий от реального.
Так как люди в повседневной жизни решают слабоформализуемые задачи чаще, чем точные, то в процессе эволюции создан механизм их решения с приемлемой для выживания homo sapies точностью. Алгоритм их решения на бессознательном уровне пока не известен, но получены полезные эвристические рекомендации.
Так как решение слабоформализуемых задач производит человек, в дальнейшем — лицо, принимающее решение (ЛПР), то используемые методы объективно должны основываться на способностях и возможностях ЛПР по решению таких задач. Они учитывают следующие эмпирические положения:
• точность решения ЛПР слабоформализуемых задач обратно пропорциональна их сложности, причем ЛПР может в среднем оперировать одновременно с 5-9 понятиями;
• объективность оценок ЛПР показателей процедур решения слабоформализуемых задач в условиях недостаточной и недостоверной информации выше при использования им качественных шкал, чем количественных;
• при ограниченности ресурса его целесообразно использовать, прежде всего, для предотвращения угроз с максимальным ущербом;
• эффективность использования ресурса выше при его комплексном применении, когда одни и те же меры предотвращают несколько угроз.
Из этих достаточно общих положений следует, что для повышения точности и объективности ЛПР выбора, целесообразно:
•детализировать алгоритм решения слабоформализуемой задачи, разбивая его на этапы и процедуры, при определении показателя которых возникает меньше ошибок;
•при оценке показателей отдельных этапов и процедур использовать качественные шкалы с числом градаций (значений) в пределах 5-9;
•проранжировать угрозы безопасности информации по потенциальному ущербу и расходование ресурса на предотвращение угроз производить последовательно, начиная с мер предотвращения угрозы с максимальным ущербом;
• при разработке мер защиты учитывать влияние предыдущих мер на снижение ущерба рассматриваемой угрозы.
Действительно, если человек не знает точного количественного значения какого-либо показателя, он заменяет его качественной мерой: высокий человек, большая цена, длинный путь, малая вероятность и др. При этом его качественные оценки могут весьма точными и однозначными.
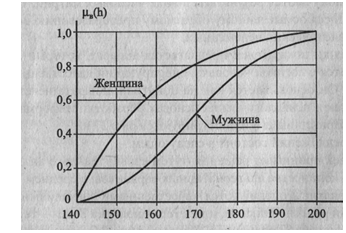 |
В настоящее время предпринимаются многочисленные попытки использовать для обработки нечетко определенной информации аппарат нечетких множеств Заде [5]. Суть подхода Заде состоит в замене качественных понятий, например, таких как «цена информации, «угроза безопасности информации» и др., названных лингвистическими переменными, на количественные аналоги и последующей обработке числовой информации с помощью предложенного Заде математического аппарата. С этой целью вводятся функции принадлежности или совместимости количественных значений лингвистической переменной. На рис. 27.9 в графической форме представлены функции принадлежности UB(h) лингвистических переменных «высокая женщина» и «высокий мужчина».
Рис. 27.9. Графическое представление функции принадлежности
На этом рисунке по оси абсцисс указаны значения роста человека в см, а по оси ординат— числа в интервале [0-1], соответс-. твующие степени принадлежности значения роста женщины или мужчины лингвистической переменной «высокий(ая)».
Функции принадлежности могут быть определены в графической или табличной форме, а также в виде алгебраической суммы значений цв(Ь). Например, функция принадлежности лингвистической переменной «высокий мужчина», графическое представление которой приведено на рис. 27.9, имеет вид:
UnM = 0/140 + 0,1 /150 + 0,3/160 + 0,53/170 + 0,75/190 + 0,95/200.
Каждое слагаемое этой функции соответствует значению функции принадлежности для определенного значения роста человека.
Предложенный в теории нечетких множеств математический аппарат в виде операций сложения, объединения, умножения позволяет производить обработку цифрового массива функций принадлежности. Несмотря на привлекательность аппарата нечетких множеств при его применении возникают проблемы, прежде всего, психологического плана, которые сдерживают его внедрение. Суть этих проблем состоит в том, что в ходе обработки функций принадлежности получаются результаты в виде числовых матриц, трудно поддающиеся осмысленному обратному преобразованию в значения лингвистических переменных.
Для оценки показателей предлагается аппарат, который лучше согласуется с логикой человека, оперирующий качественными понятиями. Он основывается как на понятиях аппарата нечетких множеств, так и психологических основах обработки информации человеком. Принципы его иллюстрируются рис. 27.10. Суть предложений состоит в следующем. 1. Человек принимает решения путем сравнительного анализа небольшого количества альтернативных вариантов, в среднем около 7. Альтернативы оцениваются качественными значениями порядковой или ранговой шкалы, или в терминологии Заде — термами лингвистической переменной. Учитывая способность человека одновременно оперировать в среднем 5-9 словами и числами, количество градаций лингвистической шкалы следует выбирать такого же порядка.
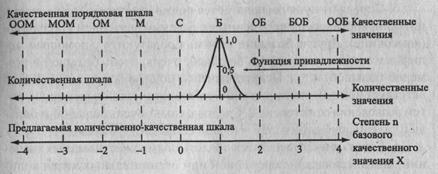
Рис. 27.10. Шкалы для оценки показателей в области информационной безопасности
Обозначения: ООМ — очень, очень малый(ая); MOM — менее чем очень малый; ОМ — очень малый; М — малый; С — средний; Б — большой; ОБ — очень большой; БОБ — более чем очень большой; ООБ -— очень, очень большой.
2.Значения лингвистических переменных «цена информации», «риск угрозы», «ущерб от реализации угрозы»: очень очень большая, очень большая, большая, средняя, малая, очень малая, очень очень малая лингвистических переменных образуют качественную шкалу с 7 градациями. Для других лингвистических переменных градации шкалы будут характеризоваться другими понятиями. Но общими для них являются базовые значения «болыиой(ая)»,
«малый(ая)» и модификаторы «очень».
3.Над качественной шкалой располагается количественная шкала, значения которой соответствуют значениям показателя качественной шкалы. Значения «большой» или «малый» идентичны этим значения в первой степени, т. е. большой = большой1, а малый = малый1.
4.Учитывая способность человека к дихотомии (разбиению линейного размера пополам), точка отсчета (условный нуль) соответствует значению «средний (средняя)» лингвистической nej
ременной качественной шкалы или 0 количественной шкалы.
Значение «средний» можно интерпретировать как «не большой и не малый», «не высокий и не низкий». Примем, что средний соответствует большому или малому в нулевой степени, т. е. средний = большой0 = малый0.
5.Справа от нуля располагается подмножество больших значений лингвистических переменных с базовым значением «большой»(«высокий»). Другие большие значения образуются с помощью модификаторов «очень»: очень большой, очень, очень большой (чрезмерно большой) и т. д. Психологически модификатор «очень» соответствует концентрации значения лингвистической переменной путем возведения ее в степень 2. Следовательно, очень большой = боль
шой2; очень, очень большой '= (очень большой)2 = большой4.
6.Слева от нуля находится область подмножества малых значений лингвистической переменной или отрицательных чисел количественной шкалы. Значения лингвистической переменной, мень
шие «среднего», соответствуют «малый», «очень малый» и т. д. Или «низкий», «очень низкий» и т. д. Учитывая, что психологически произведение «большой» на «малый» воспринимается как «средний»,
то малый = средний / большой» = болшой0 / большой1 = большой"1, очень малый = большой ~2 и т. д.
Следовательно, все значения лингвистической переменной можно выразить через одно базовое значение «большой», «малый», «высокий», «низкий» в соответствующей степени.
С учетом введенных обозначений любая лингвистическая переменная может быть записана в виде алгебраического выражения: ух", где у — наименование лингвистической переменной (цена, вероятность, риск, ущерб и др.), х— базовое значение лингвистической переменной, п — положительные или отрицательные натуральные числа. Например, показатель «очень большая цена информации» = х2у, где х — большая, у — цена информации.
Для повышения объективности оценки показателей необходимо выявить факторы, влияющие на их величину, и установить связи между значениями этих факторов и показателей. Основные из этих факторов указаны в табл. 27.11.
Таблица 27.11
| № п/п | Лингвистическая переменная (показатель процедур оптимизации) | Условные обозначения показателя | Факторы, учитываемые при оценке показателя | |||||
| 1 | 2 | 3 | 4 | |||||
| Цена информации i-ro источника | CHi | Гриф секретности | ||||||
| Вероятность k-й угрозы информации i-ro источника | ру. | Р = р(пу). р(->У). р(»У) yki yki yki yki | ||||||
| Ущерб от k-й угрозы информации 1-го источника | Г = Г • Р Ski Sii ryki | |||||||
| Затраты на предотвращение k-й угрозы информации i-ro источника | c3ki | Затраты на проектирова- ' ние, закупку, установку и эксплуатацию технических средств и реализацию организационных мер | ||||||
| Эффективность меры на предотвращение k-й угрозы информации i-ro источника | wki | W = Г /Г W3ki Ski ' Чы | ||||||
Примечание. Р(пу) и, Р(эу) ki, Р(ву) k. — вероятности выполнения пространственного, энергетического и временного условий разведывательного контакта.
На цену защищаемой информации влияют собственные затраты организации при ее получении, ожидаемая прибыль от применения информации, ущерб при попадании этой информации к злоумышленнику. В первом приближении цена защищаемой информации пропорциональна грифу ее секретности. Но значения грифа секретности образуют порядковую шкалу. У каждого человека формируется собственное опорное представление о количественной мере качественного значения лингвистической переменной. Например, для одного человека цена одного и того же товара очень малая, для другого — очень большая. Учитывая, что задача оптимизации системы защиты решается в конкретной организации для уменьшения субъективизма, в качестве опорной меры целесообразно использовать экспертную оценку в организации количественной меры базового значения «большая» цена или «большие» расходы.
Попадание к противнику информации, составляющей тайну организации, может нанести ей ущерб, который в общем случае оценивается в зависимости от мощности организации как средний или большой. Например, если грифу «секретно» можно сопоставить значение (х) цены информации как большая — х1, то «совершенно секретно» •— чрезвычайно (очень, очень) большая — х2, «особой важности» — (очень, очень большая)2 -— х4.
Еще большая неопределенность возникает при определении значений вероятности угрозы. Единственная возможность повысит достоверность оценки — расчленение этого показателя на составляющие и определение значений этих составляющих, что сделать обычно проще, чем оценить значение интегрального показателя. Для получения информации злоумышленником необходимо выполнить ряд этапов и процессов, которые можно свести к трем условиям разведывательного контакта злоумышленника с источником информации:
- поиск и обнаружение источника информации; — размещение технического средства добывания на удалении от источника, при котором обеспечивается приемлемое отношение сигнал/шум на входе средства;
— совпадение времени и проявления демаскирующих признаков объекта защиты или передачи семантической информации и работы средства добывания.
Угроза реализуется при одновременном выполнении этих условий, а вероятность ее равна произведению соответствующих вероятностей.
С учетом рассмотренных предложений значения показателей алгоритма проектирования системы защиты информации указаны в табл. 27.12.
Таблица 27.12
| № п/п | Лингвистические переменные | Значения: показателей | Алгебраические выражения для вычисления значений показателей | ||
| 1 | 2 | 3 | 4 | ||
| Цена информации | х"у J И | ||||
| 1 | Вероятность выполнения пространственного условия | хру Jay | |||
| Вероятность выполнения энергетического условия | хгу •'эу | ||||
| Вероятность выполнения временного условия | *% | ||||
| Вероятность угрозы | хгаУу | my =xp + r+g/ у V) Л Jy Л \.3 ъуЗ -у} уу) | |||
| Ущерб от угрозы | ХХ | xsy = хп + т(у у) J yy ^»в* у* | |||
| Затраты на меру защиты | Х'У, | ||||
| Эффективность меры по защите | Аэ | xhy =xs j(y /у) уз уу J v | |||
Примечание. 1. В выражениях табл. 27.12 опущены для упрощения записи индексы i и k обозначения i-ro источника и k-й угрозы;
Пример. 1. Исходные данные:
•цена информации — очень большая (х2уи);
•вероятность выполнения пространственного условия —малая (х-'упу);
•вероятность выполнения энергетического условия — малая (хчуэу);
•вероятность выполнения временного условия— средняязатраты на меру защиты — малые (х~'уз).
2. Производные показатели:
•вероятность угрозы — х~м+0у = х~2у — очень малая угроза;
•ущерб от угрозы —- х2~~2ууу = х°ууу — средний;
•эффективность меры защиты — х°+1уэ — высокая.
Для цены информации «большая» при тех же остальных исходных данных:
•ущерб от угрозы — х'~2у = х~'у — малый;
•эффективность меры защиты — х~|+1уэ = х°уэ — средняя.
Таким образом, рассмотренный аппарат позволяет производить простейшие операции непосредственно со значениями лингвистических переменных без промежуточного перевода их в числовые значения. Для одинакового восприятия значений лингвистических переменных разными людьми необходимо базовое значение прокомментировать соответствующим по мнению лица, производящего оптимизацию, числовым значением.
Рассмотренный аппарат может найти применение не только для решения задач защиты информации, но и любых других слабоформализуемых задач, при решении которых применяются качественные шкалы.
1.Этапы алгоритма проектирования (модернизации) системы защиты информации.
2.Условия завершения оптимизации и функции обратной связи в алгоритме проектирования (модернизации) системы защиты информации.
3.Виды моделей, применяемые при проектировании системы защиты информации.
4.Основные процессы, выполняемые при моделировании объектов защиты.
5.Основные процессы моделирования угроз информации.
6.Типы злоумышленников, проникающих в организацию.
7.Математический аппарат, применяемый для моделирования каналов несанкционированного доступа к информации.
8.Основные процедуры и показатели моделирования каналов утечки информации.
9.Рекомендации по оценке риска утечки информации по оптическому каналу утечки.
10.Рекомендации по оценке риска утечки информации по акустическому каналу.
11.Рекомендации по оценке риска утечки информации по радио электронному каналу.
12.Основные положения математического аппарата, рекомендуемого для оценки показателей моделирования системы инженерно-технической защиты информации.

