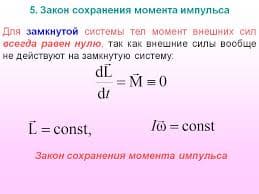2017-10-31
2017-10-31 280
280
In natural environment speech signals seldom occur in pure form. In most cases there is a superposition by acoustic ambient noise or echo. A human ignores sounds with low noise level; it is even possible to listen selectively to one dialogue partner in a voice mix-up (so-called cocktail party effect). However, an echo with a very long duration, like in telephone communications, is disturbing.

In automated speech processing, acoustic noise has a negative influence. The algorithms used for speaker localization and speech recognition today function well with noiseless voice signals; in reverberating and noisy environments in contrast, the recognition rate decreases significantly.
Besides the known single-channel techniques for acoustic noise suppression, sensor array processing becomes more and more important. The recording area of the sensor array consisting of several microphones is electronically steered to the speaker of interest or the sensor signals are used to separate individual signals (blind source separation). By the analysis of the voice signals recorded by the sensor
array, the speaker’s position can be estimated.
Compared to classical sensor array processing the basic conditions are significantly different in acoustics. The voice signal is a baseband signal, the localization and recording takes place in the nearfield of the sensors and the signal is not generated by a point source but at mouth, larynx and thorax.