 2017-12-14
2017-12-14 1462
1462
Для того, чтобы произвести аутентификацию личности по подписи по алгоритму, обязательны следующие шаги:
1. получение данных подписей(-и) от устройства;
2. предварительная обработка подписей(-и);
3. выделение ключевых особенностей подписей(-и) и DTW особенностей;
4. cохранение шаблонов подписи (или сравнение подписи с шаблонами);
5. верификация (успешно или нет).
2.2.1 Предварительная обработка
Входной сигнал от планшета может быть очень неточным. Во-первых, используемое перо может влиять на плавность подписи. Самым распространенным методом для сглаживания подписи является использование фильтра Гаусса. Каждый участок между критическими точками должен быть сглажен отдельно для того, чтобы сохранить их абсолютные позиции.
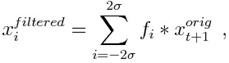 (2.1)
(2.1)
где
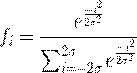 (2.2)
(2.2)
Так же подписи от одного и того же человека могут сильно отличаться по размеру, поэтому следует их нормализовать по размеру.
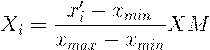
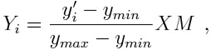 (2.3)
(2.3)
где 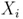 ,
, 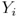 - координаты нормализованной подписи;
- координаты нормализованной подписи;
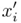 ,
, 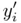 - координаты необработанной подписи;
- координаты необработанной подписи;
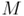 - одно из измерений (широта или высота) нормализованной подписи.
- одно из измерений (широта или высота) нормализованной подписи.
Для сравнения пространственных особенностей, временные зависимости следует исключить из представления, это достигается путем передискретизации. Временные характеристики должны быть извлечены, прежде чем проводить передискретизацию. Частота выборки: 100 образцов/сек.
Так же следует соединить все штрихи в один длинный штрих, или в одну длинную строку. Штрих - последовательность точек между опущенным и поднятым пером. Делается это для того, чтобы облегчить процедуру сравнения строк (см. рис. 3).

Рисунок 3 - Соединение штрихов
И еще один из важных пунктов в пред обработке подписи - выделение критических точек. Критические точки - точки которые несут больше информации, чем все остальные точки. Это точки где меняется направление движения штриха или конечные точки штриха (см. рис. 4).
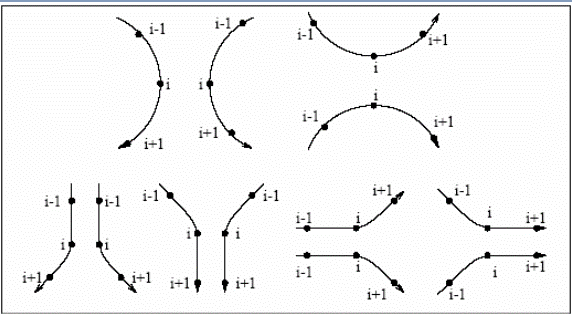
Рисунок 4 - Критические точки
На рис.5 можно видеть необработанный вариант подписи, а на рис.6 нормализованную подпись.
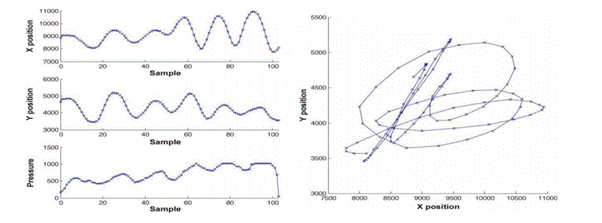
Рисунок 5 - Необработанная подпись
Рисунок 6 - Нормализованная подпись
2.2.2 Выделение ключевых особенностей
Ключевые особенности делят на глобальные и локальные. Глобальные особенности описывают всю подпись целиком, и в результате получается одно или несколько значений, представляющих определенную характеристику. Локальные извлекаются в локальной окрестности точки образца. Также можно выделить и пространственно-временные особенности, позволяющие уловить динамику процесса подписи.
Основными локальными особенностями являются:
- dx - разница по X-координате между соседними двумя точками;
- dy - разница по Y-координате между соседними двумя точками;
- dp - разница в давлении между соседними двумя точками;
- sin 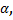 cos
cos 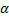 - синус и косинус углов с x-координатой;
- синус и косинус углов с x-координатой;
- absolute y - абсолютная Y-координата;
- curvature - кривизна штриха.
Временные особенности:
- абсолютная и относительная скорости между каждыми точками;
- velocity - абсолютная и относительная скорости между критическими точками.
Скорость определяется как расстояние за единицу времени. Прибор считывает данные с планшета 100раз/сек. Это уже обеспечивает равномерную единицу времени. Расстояние между двумя последовательными точками является мерой скорости письма между этими точками. Ресамплинг разрушает исходную информацию о скорости. Таким образом, скорость должна быть извлечена до или во время повторной выборки.
Нормализация локальной скорости в каждой точке выборки по средней скорости записи по всей подписи дает функцию скорости, которая не зависит от общей скорости. При этом принимается во внимание тот факт, что из-за
написания обстоятельств и из-за размера подписи, средняя скорость записи писателя может варьироваться. Относительная скорость в каждой точке внутри подписи, тем не менее должна быть стабильной.
Другой подход состоит в извлечении скорости только в критических точках и измерении средней скорости от одной критической точки к следующей. Это значение также может быть нормировано средней скоростью подписи. Несмотря на то, критические точки извлекаются и хранятся перед любой предварительной обработке, средняя скорость вычисляется перед предварительной обработки, так как длины дуг между двумя последовательными критическими точками могут быть изменены в процессе передискретизации и сглаживания.
Глобальные особенности учитывать не будем, но тем не менее они имеют место быть, так как несут информацию обо всей подписи целиком.
2.2.3 Регистрация шаблонов подписи
Для того, чтобы аутентифицировать пользователь, он должен предоставить несколько примеров, чтобы зарегистрироваться в системе. Количество подписей, как правило, колеблется в пределах от 5 до 10. Затем из этого набора подписей генерируется шаблон (эталон). Множество подписей обозначим знаком R.
Первый шаг здесь - сравнить все подписи попарно и найти расстояние между парами. Используя эти оценки, выбрать подпись с минимальными расстояниями до всех остальных подписей, эта подпись и будет эталонной.
Второй шаг - посчитать три средних величины для R:
1. 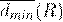 - среднее значение расстояние до ближайшего соседа;
- среднее значение расстояние до ближайшего соседа;
2. 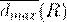 - среднее значение расстояние до дальнего соседа;
- среднее значение расстояние до дальнего соседа;
3. 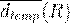 - среднее значение расстояние до эталонной подписи.
- среднее значение расстояние до эталонной подписи.
Средние значения выбраны не случайно, а для устранения погрешностей в написании подписи. А минимальное, максимальное и расстояние до эталона и описывают амплитуду расхождения подписей.
Для подсчета расстояния и используется алгоритм DTW.
2.2.3.1 Алгоритм алгоритм динамического трансформирования времени (DTW)
DTW вычисляет оптимальную последовательность трансформации (деформации) времени между двумя временными рядами. Алгоритм вычисляет оба значения деформации между двумя рядами и расстоянием между ними.
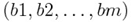
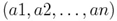 Предположим, что у нас есть две числовые последовательности ааааааааааа и. Как видим, длина двух последовательностей может быть различной. Алгоритм начинается с расчета локальных отклонений между элементами двух последовательностей, использующих различные типы отклонений. Самый распространенный способ для вычисления отклонений является метод, рассчитывающий абсолютное отклонение между значениями двух элементов (Евклидово расстояние). В результате получаем матрицу отклонений, имеющую n строк и m столбцов общих членов:
Предположим, что у нас есть две числовые последовательности ааааааааааа и. Как видим, длина двух последовательностей может быть различной. Алгоритм начинается с расчета локальных отклонений между элементами двух последовательностей, использующих различные типы отклонений. Самый распространенный способ для вычисления отклонений является метод, рассчитывающий абсолютное отклонение между значениями двух элементов (Евклидово расстояние). В результате получаем матрицу отклонений, имеющую n строк и m столбцов общих членов:
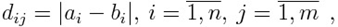 (2.4)
(2.4)
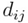 где - Евклидово расстояние.
где - Евклидово расстояние.
Минимальное расстояние в матрице между последовательностями определяется при помощи алгоритма динамического программирования и следующего критерия оптимизации:
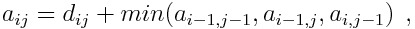 (2.5)
(2.5)
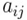
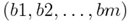 где - минимальное расстояние между последовательностями аааааааааааа и.
где - минимальное расстояние между последовательностями аааааааааааа и.
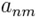
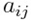
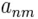
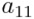 Путь деформации – это минимальное расстояние в матрице между элементами и, состоящими из тех элементами, которые выражают расстояние до.
Путь деформации – это минимальное расстояние в матрице между элементами и, состоящими из тех элементами, которые выражают расстояние до.
Глобальные деформации состоят из двух последовательностей и определяются по следующей формуле:
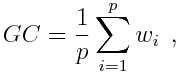 (2.6)
(2.6)
где 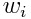 – элементы, которые принадлежать пути деформации;
– элементы, которые принадлежать пути деформации;
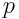 – их количество.
– их количество.
Существует три условия, налагаемых на DTW алгоритм для обеспечения быстрой конвергенции:
1) Монотонность – путь никогда не возвращается, то есть: оба индекса, i и j, которые используются в последовательности, никогда не уменьшаются.
2) Непрерывность – последовательность продвигается постепенно: за один шаг индексы, i и j, увеличиваются не более чем на 1.
3) Предельность – последовательность начинается в левом нижнем углу и заканчивается в правом верхнем.
Так как для определения основы последовательности в динамическом программировании оптимальным является использование метод обратного программирования, необходимо использовать определенный динамический тип структуры, который называется «стек». Подобно любому динамическому алгоритму программирования, DTW имеет полиномиальную сложность. Когда мы имеем дело с большими последовательностями, возникают два неудобства:
- запоминание больших числовых матриц;
- выполнение большого количества расчетов отклонений.
Существует улучшенная версия алгоритма, FastDWT, которая решает две вышеуказанные проблемы. Решение заключается в разбиении матрицы состояний на 2, 4, 8, 16 и т.д. меньших по размеру матриц, посредством повторяющегося процесса разбиения последовательности ввода на две части. Таким образом, расчеты отклонения производятся только на этих небольших матрицах, и путях деформации, рассчитанных для небольших матриц. С алгоритмической точки зрения, предлагаемое решение основано на методе “Divide et Impera” (прим. пер. от лат. «Разделяй и влавствуй»).
2.2.4 Классификация
Тренировочный набор будет состоять из 80% процентов подлинных подписей и 20% ошибочных на человека, для того чтобы обучить классификаторы, используемые в процессе проверки. Каждая подпись (Y) из тренировочного набора сравнивается с подписями из R набора и вычисляются 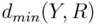 ,
, 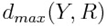 ,
, 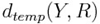 значения. Это процедура делается и для тренировочного набора, и для проверки подписи. Затем эти значения нормализуются и каждую подпись можно описать вектором признаков:
значения. Это процедура делается и для тренировочного набора, и для проверки подписи. Затем эти значения нормализуются и каждую подпись можно описать вектором признаков:
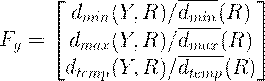 (2.7)
(2.7)
Для того, чтобы найти границу, разделяющую подлинными и фальшивые подписи, можно использовать следующие классификаторы: линейный дискриминантный анализ (LDA) или квадратичный дискриминантный анализ (QDA). Оба классифиратора являются классификаторами, где обучение “с учителем”.
2.2.4.1 Линейный дискриминантный анализ
Линейный дискриминантный анализ или LDA (Linear Discriminant Analysis)[8] это старейший из методов классификации, разработанный Р. Фишером. Метод предназначен для разделения на два класса.
Обучающий набор состоит из двух матриц X1 и X2, в которых имеется по I1 и I2 строк (образцов). Число переменных (столбцов) одинаково и равно J. Исходные предположения состоят в следующем:
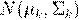 1. Каждый класс (k=1 или 2) представляется нормальным распределением 1. Каждый класс (k=1 или 2) представляется нормальным распределением 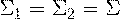 2. Ковариационные матрицы этих двух классов одинаковые 2. Ковариационные матрицы этих двух классов одинаковые |
Классификационное правило в LDA очень простое – новый образец x относится к тому классу, к которому он ближе в метрике Махаланобиса
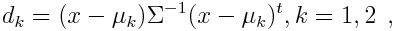 | (2.8) |
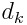
где - расстояние Махаланобиса.
На практике неизвестные математические ожидания и ковариационная матрица заменяются их оценками
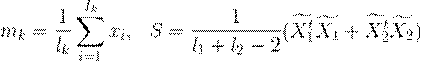 | (2.9) |
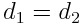 В формуле (2.9)
В формуле (2.9) 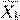 обозначает центрированную матрицу
обозначает центрированную матрицу 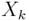 . Если приравнять расстояния в формуле (2.8), то можно найти уравнение кривой, которая разделяет классы. При этом квадратичные члены
. Если приравнять расстояния в формуле (2.8), то можно найти уравнение кривой, которая разделяет классы. При этом квадратичные члены 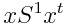 сокращаются, и уравнение становится линейным
сокращаются, и уравнение становится линейным
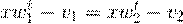 , , | (2.10) |
где
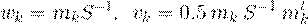 | (2.11) |
Величины, стоящие в разных частях уравнения (2.10) называются LDA-счетами, f1 и f2. Образец относится к классу 1, если f1 > f2, и, наоборот, к классу 2, если f1 < f2.
Главной проблемой в методе LDA является обращение матрицы S. Если она вырождена, то метод использовать нельзя. Поэтому часто, перед применением LDA, исходные данные X заменяют на матрицу PCA-счетов T, которая уже не вырождена.
Недостатки LDA:
1. не работает, когда матрица ковариаций вырождена, например, при большом числе переменных. Требуется регуляризация, например, PCA;
2. не пригоден, если ковариационные матрицы классов различны;
3. неявно использует предположение о нормальности распределения;
4. не позволяет менять уровни ошибок 1-го и 2-го родов.
Достоинства LDA:
1. прост в применении.
2.2.4.2 Метод главных компонент (PCA)
Пусть имеется матрица переменных X размерностью (I×J), где I - число образцов (строк), а J - это число независимых переменных (столбцов), которых, как правило, много (J>>1). В методе главных компонент используются новые, формальные переменные ta (a=1,…A), являющиеся линейной комбинацией исходных переменных xj (j=1,…J)
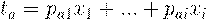 | (2.12) |
С помощью этих новых переменных матрица X разлагается в произведение двух матриц T и P:
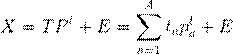 | (2.13) |
Матрица T называется матрицей счетов (scores). Ее размерность - (I×A).
Матрица P называется матрицей нагрузок (loadings). Ее размерность (A×J).
E - это матрица остатков, размерностью (I×J).

Рисунок 7 - Разложение по главным компонентам
Чаще всего для построения PCA счетов и нагрузок, используется рекуррентный алгоритм NIPALS[8], который на каждом шагу вычисляет одну компоненту. Сначала исходная матрица X преобразуется (как минимум – центрируется) и превращается в матрицу E0, a=0. Далее применяют следующий алгоритм.
1. Выбрать начальный вектор t
2. pt = tt Ea / ttt
3. p = p / (ptp)½
4. t = Ea p / ptp
5. Проверить сходимость, если нет, то идти на 2
После вычисления очередной (a-ой) компоненты, полагаем ta=t и pa=p. Для получения следующей компоненты надо вычислить остатки Ea+1 = Ea – t pt и применить к ним тот же алгоритм, заменив индекс a на a+1.
После того, как построено пространство из главных компонент, новые образцы Xnew могут быть на него спроецированы, иными словами – определены матрицы их счетов Tnew. В методе PCA это делается очень просто
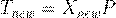 | (2.14) |
Во многих случаях, перед применением PCA, исходные данные нужно предварительно подготовить: отцентрировать и/или отнормировать. Эти преобразования проводятся по столбцам - переменным.
Центрирование - это вычитание из каждого столбца x j среднего (по столбцу) значения
 . (2.15)
. (2.15)
Центрирование необходимо потому, что оригинальная PCA модель не содержит свободного члена.
Второе простейшее преобразование данных - это нормирование. Это преобразование выравнивает вклад разных переменных в PCA модель. При этом преобразовании каждый столбец xj делится на свое стандартное отклонение.
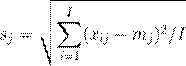 (2.16)
(2.16)
Комбинация центрирования и нормирования по столбцам называется автошкалированием.
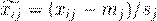 (2.17)
(2.17)
Любое преобразование данных - центрирование, нормирование, и т.п. - всегда делается сначала на обучающем наборе. По этому набору вычисляются значения mj и sj, которые затем применяются и к обучающему, и к проверочному набору.
2.2.4.3 Квадратичный дискриминантный анализ
Квадратичный дискриминантный анализ, QDA (Quadratic Discriminant Analysis) является естественным обобщением метода LDA. QDA– многоклассный метод и он может использоваться для одновременной классификации нескольких классов k=1,…, K.
Обучающий набор состоит из K матриц X1,…, XK, в которых имеется I1,…, IK строк (образцов). Число переменных (столбцов) одинаково и равно J. Ковариационные матрицы в каждом классе различны. Тогда QDA-счета вычисляются по формуле:
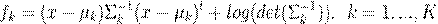 (2.18)
(2.18)
Классификационное правило QDA такое – новый образец x относится к тому классу, для которого QDA-счет наименьший.
На практике, также как и в LDA, неизвестные математические ожидания и ковариационные матрицы заменяются их оценками
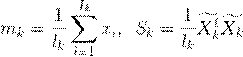 | (2.19) |
В этих формулах 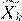 обозначает центрированную матрицу Xk. Поверхность, разделяющая классы k и l определяется квадратичным уравнением
обозначает центрированную матрицу Xk. Поверхность, разделяющая классы k и l определяется квадратичным уравнением
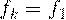 (2.20)
(2.20)
поэтому метод и называется квадратичным.
Квадратичный дискриминантный анализ сохраняет большинство недостатков LDA.
1. не работает, когда матрицы ковариаций вырождены, например, при большом числе переменных. Требуется регуляризация, например, PCA;
2. неявно использует предположение о нормальности распределения;
3. не позволяет менять уровни ошибок 1-го и 2-го родов.

