2018-01-08
2018-01-08 844
844Министерство образования и науки Донецкой Народной Республики
ГОУ ВПО Донецкий национальный университет
Распознавание речи
Методические указания к выполнению лабораторных работ для студентов магистратуры, обучающихся по направлению подготовки 09.001 – «Информатика и вычислительная техника»
Донецк – 2016
Лабораторнаяробота№1
Тема: разработка инструментария формирования набора признаков распознавания речи на основе различных способов параметризации речевого сигнала.
Цель: практическая реализация методов получения различных признаков для распознавания речевого сигнала, создание обучающей выборки по всем наборам признаков для дальнейшего распознавания.
Порядоквыполненияработы
1. Ознакомиться с теоретической частью.
2. Разработать интерфейс программы с возможностью
a. записи звука и графического вывода амплитудно-временного представления сигнала в отдельное окно, выделения в этом окне фрагмента сигнала для получения наборов признаков для его распознавания;
b. графического вывода в отдельное окно значений компонент вектора признаков для выделенного фрагмента сигнала;
c. создание/редактирование БД, в которую занесены признаки распознавания, полученные по реализациям речевых единиц;
d. визуальный анализ эффективности признаков в виде графиков значений признаков, выводимых в отдельное диалоговое окно, из указанного из списка набора для всех реализаций речевых единиц, принадлежащих выбранной паре фонетических классов (пары классов задает пользователь).
3. Реализовать в едином программном комплексес открытой архитектурой методыполучения наборов признаков на основе:
a. Фурье и вейвлет-преобразования Добеши2-го порядка;
b. кодирования с линейным предсказанием (порядок предсказания р выбирает пользователь);
c. MFCC.
4. Реализовать инструментарий для создания/редактирования БД, в которую занесены признаки распознавания, полученные по реализациям речевых единиц.
5. Создать БД наборов признаков для 10 различных фонем (см. табл. 1.2), которую в дальнейшем использовать для обучения классификатора, наполнить ее данными для этих фонем, представителей фонем каждого класса должно быть не менее 5, частота дискретизации записи звука 22050 Гц.
6. Оформить отчет по лабораторной работе.
Краткиетеоретическиесведения
Ниже будут рассмотрены две группы методов параметризации речевого сигнала(РС) для выделения акустических параметров речи. Одна группа базируется на физиологических и психофизических особенностях слушателя и синтезирует банки полосовых фильтров, создаваемых посредством быстрого преобразования Фурье (БПФ) и вейвлет-преобразования. Другая группа основана на акустической теории образования речи и включает в себя гомоморфную обработку речи и кодирование с линейным предсказанием (КЛП).
Частотно-временное представление речевого сигнала с помощью Фурье и вейвлет-преобразований
Прямое дискретное преобразование Фурье (ДПФ) дискретного сигнала длины N  , позволяет получить спектр в виде:
, позволяет получить спектр в виде:
 ,
,  .
.
Спектр Фурье дискретного сигнала представляет собой совокупность гармонических колебаний (гармоник), характеризующихся амплитудой (1.1), начальной фазой (1.2) и угловой частотой (1.3).
 , , , ,
| (1.1) |
 , , , ,
| (1.2) |
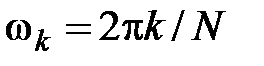 , , , ,
| (1.3) |
где  ,
,  – действительная и мнимая части коэффициентов ряда Фурье.
– действительная и мнимая части коэффициентов ряда Фурье.
Прямое ДПФ можно представить в более удобной форме в виде (1.4)
 , , , ,
| (1.4) |
где  .
.
Для более эффективного вычисления дискретного преобразования Фурье используются алгоритмы быстрого преобразования Фурье (БПФ).
Основная идея БПФ состоит в том, чтобы разбить исходную N -точечную последовательность x (n) на две более короткие последовательности, ДПФ которых могут быть скомбинированы таким образом, чтобы получилось ДПФ исходной N -точечной последовательности. Так, например, если N четное, а исходная N -точечная последовательность разбита на две N /2-точечные последовательности, то для вычисления искомого N -точечного ДПФ потребуется порядка 2(N /2)2= N 2/2 комплексных умножений, т.е. вдвое меньше по сравнению с прямым вычислением. Здесь множитель (N /2)2 дает число умножений, необходимое для прямого вычисления N /2-точечного ДПФ, а множитель 2 соответствует двум ДПФ, которые должны быть вычислены. Эту операцию можно повторить, вычисляя вместо N /2-точечного ДПФ два N /4-точечных ДПФ (предполагая, что N /2 четное) и сокращая тем самым объем вычислений еще в два раза.
Проиллюстрируем описанную методику для N -точечной последовательности { x (n)}, считая, что N равно степени 2. Введем две N /2-точечные последовательности { x 1(n) } и { x 2(n) } из четных и нечетных членов x (n) соответственно, т.е.
x 1(n) = x (2 n), n = 0,1,..., N /2 – 1,
x 2(n) = x (2 n +1), n = 0,1,..., N /2 – 1.
N -точечное ДПФ последовательности { x (n)} можно записать как

 , ,  . .
| (1.5) |

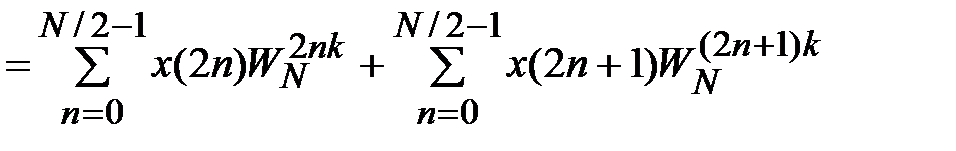 , . , .
|
С учетом того, что
 , ,
|
перепишем выражение (1.5) в виде
 , ,
| |
 , , , ,
| (1.6) |
где X 1(k) и X 2(k) – N /2-точечные ДПФ последовательности x 1(n) и x 2(n).
Из формулы (1.6) следует, что N -точечное ДПФ X (k) может быть разложен на два N /2-точечных ДПФ, результаты которых объединяются согласно (1.6). Таким образом, БПФ обеспечивает рекуррентное вычисление всех 2-точечных, затем 4-точечных, …, N -точечных ДПФ.
Итак, приведем описание рекурсивного алгоритма БПФ на С++
void FFT(vector<CComplexNumber>&vcSrc, vector<CComplexNumber>&vcRes, bool bForward)
{
intiSize=vcSrc.size();
vcRes.assign(iSize,CComplexNumber());
inti;
if(iSize==1) vcRes.front()=vcSrc.front();
else
{
vector<CComplexNumber> vcSrcEven(iSize/2,CComplexNumber()),
vcSrcOdd(iSize/2,CComplexNumber());
vector<CComplexNumber> vcEven, vcOdd;
for(i=0;i<iSize/2;i++)
{
vcSrcEven[i]=vcSrc[2*i];
vcSrcOdd[i]=vcSrc[2*i+1];
}
FFT(vcSrcEven,vcEven,bForward);
FFT(vcSrcOdd,vcOdd,bForward);
//А теперь нужно правильно обойти оба массива и получить нужный //результат
for(i=0; i<iSize; i++)
{
double A=2*PI/iSize*i;
if(bForward) A*=-1;
CComplexNumberWk(cos(A),sin(A));
if(i<iSize/2) vcRes[i]=vcEven[i]+vcOdd[i]*Wk;
else vcRes[i]=vcEven[i-iSize/2]+vcOdd[i-iSize/2]*Wk;
}
}
}
В отличие от Фурье-преобразования вейвлет-преобразование позволяет с большей чувствительностью идентифицировать и классифицировать локальные изменения (кратковременные переходные особенности нерегулярного вида) РС в условиях действия шумов на основе оценки распределения энергии РС в вейвлет-области при различных уровнях разрешения.
Дискретное вейвлет-преобразование (ДВП) заключается в представлении сигнала f в виде
 . .
| (1.7) |
При этом  является уровнем детализации,
является уровнем детализации,  - коэффициенты вейвлет-разложения,
- коэффициенты вейвлет-разложения, 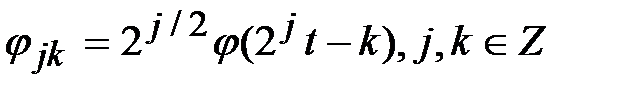 ,
,  – масштабная функция,
– масштабная функция,  ,
,  – базисный или «материнский» вейвлет.
– базисный или «материнский» вейвлет.
Если связать функцию j с ее сдвинутыми и сжатыми модификациями, то простейшее линейное соотношение с числом коэффициентов 2 M можно записать в виде
 .
.
Число M задает порядок вейвлета (количество его нулевых моментов), определяет число коэффициентов hk и длину области задания вейвлета. Если функция j (t) известна, тогда можно построить базисный вейвлет y (t)
 .
.
Свойства ортогональности масштабирующих функций, ортогональности вейвлетовмасштабирующим функциям, ортогональности вейвлетов полиномам до степени M -1 и условия нормировки задают полную систему вейвлетов данного порядка из известного семейства вейвлетовДобеши
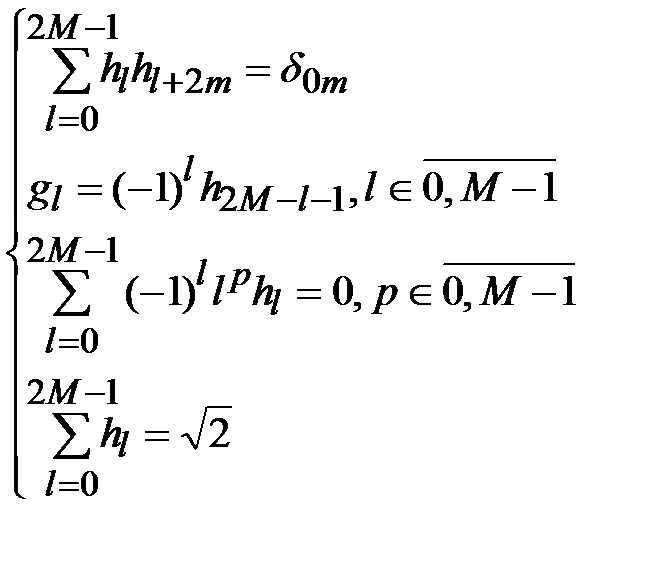
|
Общие свойства масштабирующих функций и вейвлетов однозначно определяют коэффициенты hk и gk, а также дают возможность быстрого преобразования, с помощью которого находятся коэффициенты sjk и djk из разложения (1.7). На основе ДВП строят двухканальный блок фильтров, который делит спектр сигнала на две субполосы – высокочастотную и низкочастотную. При этом коэффициенты hk и gk задают фильтры низких и высоких частот соответственно.
Таким образом, для нахождения значений коэффициентов вейвлет-фильтра длиной L =2 М =4 необходимо решить систему из четырех алгебраических уравнений: два уравнения, полученные из условия ортогональности, и два уравнения нулевых моментов.

Решением этой системы являются следующие значения:

h 0=0,4829629131445341; h 1=0,8365163037378097;
h 2=0,2241438680420134; h 3= – 0,129409522551260
Для сигнала f (n) вычисление коэффициентов sjk и djk разложения (1.7) по вейвлет-базису порядка M на j max уровней проводится итеративнобез непосредственного использования функций φ и y. При этом количество уровней разложения (итераций) равно 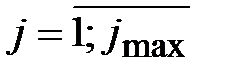 , количество коэффициентов sjk и djk на каждом уровне разложения одинаково и вдвое меньше количества соответствующих коэффициентов на предыдущем уровне. Поэтому для дерева глубиной d необходимо иметь исходный сигнал f (n) длины, кратной 2 d. В противном случае он удлиняется некоторым образом до этого размера. Периодическое и симметричное продолжения сигналов обеспечивают полное его восстановление. Метод периодического продолжения является наиболее часто используемым, так как он пригоден для любого типа фильтра, в частности для вейвлетаДобеши.
, количество коэффициентов sjk и djk на каждом уровне разложения одинаково и вдвое меньше количества соответствующих коэффициентов на предыдущем уровне. Поэтому для дерева глубиной d необходимо иметь исходный сигнал f (n) длины, кратной 2 d. В противном случае он удлиняется некоторым образом до этого размера. Периодическое и симметричное продолжения сигналов обеспечивают полное его восстановление. Метод периодического продолжения является наиболее часто используемым, так как он пригоден для любого типа фильтра, в частности для вейвлетаДобеши.
Продолжение сигнала до длины, кратной степени двойки, ведет к увеличению объема данных. Чтобы этого избежать, применяется эффективный метод продолжения сигнала на этапе фильтрации, суть которого в следующем. Полагая s 0 k = f (k), на j +1-ом уровне разложения выполняются такие итерации.
1. Периодическое продолжение последовательности коэффициентов аппроксимации { sjk }. Пусть Nj – длина { sjk }, дополненной до четной длины, т. е. в случае нечетной длины исходной последовательности { sjk } последний элемент получают из предыдущих экстраполяцией. Чтобы получить Nj /2 коэффициентов аппроксимации и детализации на следующем уровне разложения в результате свертки с фильтром длины 2 M (для вейвлета порядка M) необходимо продолжить { sjk } до длины Nj +2 M -2. Для периодического продолжения
 ,
, 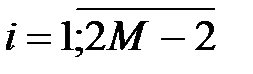 .
.
2. Свертка последовательности  с соответствующими фильтрами высоких и низких частот
с соответствующими фильтрами высоких и низких частот
 ,
,
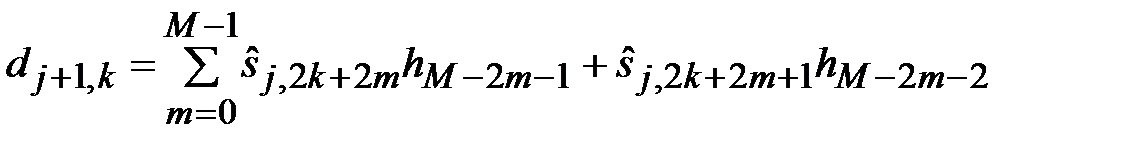 .
.
3. j = j +1; применение пункта 1 к последовательности коэффициентов { sj +1, k }.
Если на каждой j -ой итерации ( ) последовательность sj -1 k продолжать периодическим образом, то сохраняется свойство полного восстановления сигнала без увеличения количества отсчетов.
) последовательность sj -1 k продолжать периодическим образом, то сохраняется свойство полного восстановления сигнала без увеличения количества отсчетов.
Банки фильтров относятся к методам представления РС, основанным на психоакустических принципах восприятия речи. Вторая группа методов реализует подход, основанный на акустической теории образования речи, и включает в себя гомоморфную обработку речи и КЛП.