2018-01-08
2018-01-08 398
398У комплексних завданнях ідентифікації часто виникає проблема розпізнавання образів. Зокрема, програми, які можуть читати символи, у цілому ряді випадків вважаються дуже ефективными. Машина, що читає банківські чеки, може обробляти набагато більше чеків, чим людина в один і той ж час. Це заощаджує час і гроші, і відстороняє людину від виконання такої рутинної роботи. Програма appcr1 демонструє, яким образом визначення символу може бути виконано backpropagation - мережею.
Постановка завдання. Мережа повинна бути розроблена й навчена, так щоб визначити 26 літер абетки. Система відображення, переводить кожний символ (літеру) у бінарну матрицю. Результат - кожний символ представлений як сітка з булєвими змінними розмірністю 5х7. Наприклад, літера A (Рис.4.1). Однак, система відображення - не досконала, і символи можуть бути загамовані (Рис.4.2)
Необхідно виконати класифікацію ідеальних (незагамованих) векторів входу, і точно (розумно) класифікувати загамовані вектори. Двадцять шість векторів входу з 35-ма елементами, визначені у функції prprob як матриця векторів входу, називають абеткою. Цільові вектори також визначені в цьому файлі в змінних, які називають цілями. Кожний цільовий вектор - вектор з 26-ма елементами з «1» у положенні літерии, що він представляє, і 0 в інших позиціях. Наприклад, літера А повинна бути представлена 1 у першому елементі (оскільки - перша літера абетки), і 0 в елементах від другого по двадцять шостий.
Нейронна Мережа. Мережа одержує 35 значень(0, 1) як вектор входу з 35 елементами. Це потрібно, щоб ідентифікувати літеру, відповідаючи векторам виходу з 26 елементами. 26 елементний вектор виходу повинен представлять будь-яку літеру. Щоб працювати правильно, мережа повинна відповісти 1 у положенні літери, що представляється мережі. Всі інші величини у векторі виходу повинні бути 0. Крім того, мережа повинна вміти працювати із шумом. Практично мережа не одержує ідеальний (сформований) бінарний вектор як вхід. Отже, мережа може (зробити) таку кількість помилок, наскільки це припустимо при класифікації векторів із шумом із середнім рівним 0 і стандартним відхиленням 0.2 чи менше.
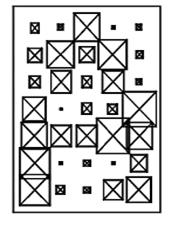 Рис.4.2 Реальне («загамоване») зображення символу (букви) А як бінарної матриці
Рис.4.2 Реальне («загамоване») зображення символу (букви) А як бінарної матриці
| 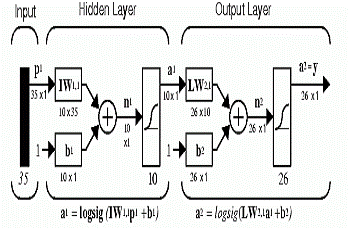 Рис.4.3. Двошарова мережа з функціями активації log-sigmoid / log-sigmoid.
Рис.4.3. Двошарова мережа з функціями активації log-sigmoid / log-sigmoid.
|
Архітектура мережі. Неиронна мережа повинна мати 35-ти елементний вхід і 26 нейронів у шарі виходу, щоб ідентифікувати символи (літери) - рис.2.43. Мережа працює із двома шарами й функціями активації log-sigmoid / log-sigmoid. Функція передачі sigmoid була обрана з тієї причини, що її діапазон виходу (від 0 до 1) є достатній для вивчення виходу (0, 1).
Перший схований шар має 10 нейронів. Це число обране методом проб і помилок. Якщо мережа повинна враховувати перешкоди, то нейрони можуть бути додані до цього шару. Навчена мережа повинна мати на виході 1 у правильному положенні вектора виходу й заповнювати нулями всі елементи виходу 0, однак, загамовані вектори входу можуть давати мережі такі виходи, які не створюють чистих 1 і 0. Після того, як мережа навчена, продукцію (результати пар «вхід-вихід») пропускають через конкурентноспроможну функцію передачі compet. Це дозволяє переконатися, що вихід, що відповідає літеріі й більше схожий на загамований вектор входу бере значення 1, і всі інші мають 0. Результат цієї постобробки - вихід, що фактично використовується.
Ініціалізація. Мережа із двома шарами, створена за допомогою функції newff.
S1 = 10;
[R,Q] = size(alphabet);
[S2,Q] = size(targets);
P = alphabet;
net = newff(minmax(P),[S1 S2],{'logsig' 'logsig'},'traingdx');
Навчання. Щоб створювати мережу, що може працювати з загамованими векторами входу, необхідно попередньо навчити мережу на ідеальних й загамованих векторах. Для цього, мережу спочатку навчають на ідеальних векторах доти, поки не одержують найнижчу середньо-квадратичну сумарну похибку. Припустимо, що мережа навчена на 10 наборах ідеальних і загамованих векторів. Мережа навчена на двох копіях абетки без гаму й у той же самий час навчена на загамованих векторах. Дві копії абетки у використовуються, щоб підтримати здатність мережі ідеально класифікувати вектори входу.
На жаль, після того, як навчання описаної вище мережі виконано, можливо, необхідно вчити класифікувати деякі важко загамовані вектори за рахунок належної класифікації вектора без гаму. Тому мережу знову навчають на ідеальних векторах. Це гарантує, що мережа відповідає абсолютно точно (однозначно), якщо представлено ідеальну букву. Все навчання виконане, використовуючи backpropagation-мережу з адаптивною нормою вивчення й імпульсної функції trainbpx.
Навчання без гаму. Мережа спочатку навчена без гаму для максимуму в 5000 епох з зменшенням похибки середньоквадратичної суми мережі нижче 0.01.
P = alphabet;
T = targets;
net.performFcn = 'sse';
net.trainParam.goal = 0.1;
net.trainParam.show = 20;
net.trainParam.epochs = 5000;
net.trainParam.mc = 0.95
[net,tr] = train(net,P,T);
Навчання із гамом. Щоб одержати мережу нечутливу до гаму, її навчають із двома ідеальними копіями й двома загамованими копіями векторів в абетці. Цільові вектори складаються із чотирьох копій векторів мети. Загамовані вектори мають гам із середнім 0.1 і 0.2, доданий до ідеального. Це змушує нейрон визначати своє поводження таким чином, щоб належним чином ідентифікувати загамовані символи, у той час як вимога правильних відповідей на ідеальні вектори залишається незмінною.
Щоб виконати навчання із гамом, максимальна кількість епох зменшене до 300, і помилка мети збільшена до 0.6, з огляду на ту можливу більше високу помилку, що очікується, тому що представляється більша кількість векторів (включаючи деякі з гамом).
netn = net;
netn.trainParam.goal = 0.6;
netn.trainParam.epochs = 300;
T = [targets targets targets targets];
for pass = 1:10
P = [alphabet, alphabet,...
(alphabet + randn(R,Q)*0.1),...
(alphabet + randn(R,Q)*0.2)];
[netn,tr] = train(netn,P,T);
end
Повторне навчання без гаму. Як тільки мережа навчена з гамом, має сенс повторно навчити її ще раз без гаму, щоб гарантувати, що ідеальні вектори входу завжди класифікуються правильно. Тому мережу знову навчають.
Виконання Системи. Вимірюють надійність нейросистеми з погляду правильного визначення символу мережі, перевіряючи мережу із сотнями векторів входу зі змінюваними значеннями гаму Файл appcr1 перевіряє мережу на різних рівнях шуму й потім графічно відтворить відсоток помилок мережі а залежності від рівня гаму. Гам із середнім рівним 0 і стандартним відхиленням від 0 до 0.5 додається до векторів входу. На будь-якому рівні загамованості мало місце 100 подань різних загамованих версій кожної літери й визначався вихід мережі. Вихід пропускають через конкурентоспроможну функцію передачі так, щоб тільки одна із цих 26 продукцій (букви абетки), має значення 1.Враховують кількість помилкових класифікацій і обчислюють відсоток правильної роботи - рис.4.5.
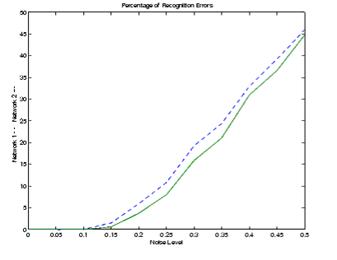 Рис.4.5 Надійність мережі, навченої із гамом і без гаму (суцільна лінія), надійність мережі за умови, що вона навчена без гаму - штрихова лінія.
Рис.4.5 Надійність мережі, навченої із гамом і без гаму (суцільна лінія), надійність мережі за умови, що вона навчена без гаму - штрихова лінія.
| 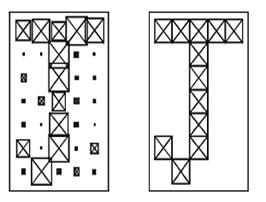 Рис.4.6. Приклад загамованого символу й символ, виданий мережею
Рис.4.6. Приклад загамованого символу й символ, виданий мережею
|
Суцільна лінія на малюнку показує надійність мережі, навченої із намом і без гаму. Надійність тієї ж самої мережі, навченої без гаму, зображується штриховою лінією. Таким чином, на мережі, навченої на загамованих векторах входу існує можливість істотного зменшення помилки, якщо необхідно класифікувати загамовані вектори. Мережа не зробила ніяких помилок для векторів із гамом із середнім 0.00 або 0.05. Якщо гам із середнім 0.2 був доданий до векторів, обидві мережі почали робити помилки. Якщо необхідно більш високу точність, мережа може бути навчена протягом більше тривалого часу або повторно навчена з більшою кількістю нейронів у його схованому шарі. Рішенням також може бути збільшення векторів входу з 10 до14 у сітці.
Зрештою, мережа могла бути навчена на векторах входу з більшими рівнями гаму, якщо особливо більша надійність була б необхідна. Щоб перевіряти систему, формують літеру із гамом шляхом створення й представлена мережі.
noisy = alphabet(:,10)+randn(35,1) * 0.2;
plotchar(noisy);
A2 = sim(net,noisy);
A2 = compet(A2);
answer = find(compet(A2) == 1);
plotchar(alphabet(:,answer));
Нижче приводиться приклад загамованого символу (Рис.4.4) і символу, ідентифікованого мережею (правильно). Цей приклад демонструє, яким образом може бути розроблена проста система розпізнавання символів.. Варто звернути увагу на те, що процес навчання не складався з єдиного запиту до функції, що виконує навчання. Замість цього, мережа була навчена кілька разів на різних векторах входу. Навчаючи мережу на різних наборах загамованих векторів, змушують мережа навчитися працювати із шумом.
1. [1] Demuth & M. Beale: «Neural Network Toolbox», The MathWorks Inc., 1993.
2. Hertz, A. Krogh & R.G. Palmer (1991): «Introduction to the Theory of Neural Computa-tion»,Addison-Wesley, 1991.
[2] Тест, также другие алгоритмы, которые реализуют РБФ или аналогичные сети - NEWRBE, NEWGRNN, NEWPNN.