 2018-01-08
2018-01-08 781
781
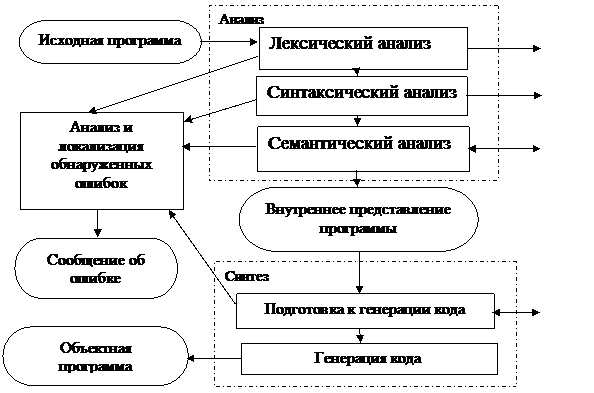
Рисунок 3.1 – Общая схема работы компилятора
На фазе лексического анализа начинается формирование таблицы идентификаторов. Синтаксический анализ. Работает с контекстом. Определяет общую структуру конструкций языка. Например, может проверить соответствие скобок, корректность структур if –then-else, while- do, и т.д. Результатом синтаксического анализа является представление программы в виде синтаксического дерева, листья которого соответствуют символам входной строки. На этом этапе продолжает формироваться таблица идентификаторов.Семантический анализ. Выполняет проверку соответствия типов данных в исходной программе, отлавливает бесконечные рекурсии, деление на ноль и другие недопустимые действия. На этапе анализа ведущей фазой является синтаксический анализ. Обычно разработанная программа – это программа синтаксического анализатора, по необходимости вызывающая модули лексического и семантического анализа. На этапе синтеза не все фазы являются обязательными. Например, можно не строить промежуточный (машинно-независимый) код, можно обойтись без фазы оптимизации на уровне машинно-независимого кода, на уровне машинно-зависимого кода или на обоих. Но есть ряд причин, по которым эти фазы присутствуют в процессе компиляции. Рассмотрим эти причины.Генерация машинно-независимого (промежуточного) кода. Включение этой фазы в процесс компиляции позволяет:‑ обеспечить переносимость компилятора на другие машины, поскольку позволяет обособить компилятор от целевого языка и конкретной машины;‑ облегчить процесс построения целевого кода, т.к. строить машинно-зависимый код гораздо удобнее по промежуточному коду;‑ обеспечить дополнительный уровень оптимизации синтезируемого кода.В качестве промежуточного представления могут использоваться следующие средства: синтаксическое дерево разбора, полученное в результате синтаксического анализа; ПОЛИЗ (польская инверсная запись), представление кода в виде триад и т.д.Оптимизация. Потребность в оптимизации может быть различной. Если требуется очень эффективный код, то компилятор должен обеспечить значительную оптимизацию. В то же время, во многих средах скорость работы ПО не является критическим параметром, следовательно, достаточно лишь незначительной оптимизации. Поскольку многие типы оптимизации трудоемки и требуют значительных затрат, то выбор уровня оптимизации является серьезной задачей. В некоторых компиляторах пользователь сам может выбрать уровень оптимизации. Распределение памяти. На этой фазе каждая константа и переменная, используемые в программе получают зарезервированное место в памяти для хранения своего значения. Данная область памяти может иметь один из следующих типов:1). Статическая память, если время жизни переменной равно времени жизни программы. Не может быть освобождена до завершения выполнения программы.2). Динамическая память, если время жизни переменной равно времени жизни определенного блока, функции или процедуры. Может быть освобождена после выполнения данного фрагмента, до завершения выполнения программы. 3). Глобальная матрица, если время жизни переменной в момент компиляции неизвестно, а память должна освобождаться и выделяться в процессе выполнения по необходимости. От эффективности распределение памяти во многом зависит эффективность работы компилятора.3.3 Хранение и поиск данных в таблицах[4,7]
Главной характеристикой любого элемента исходной программы является его имя. Задачей любого транслятора является необходимость хранения и доступа к информации, связанной с каждым элементом исходной программы. Для решения этой задачи транслятор организует специальные хранилища данных, называемые таблицами идентификаторов или таблицами символов. Количество элементов в таблицах велико и поэтому время поиска информации в них существенно влияет на общее время трансляции. Поэтому таблицы идентификаторов должны быть организованы таким образом, чтобы транслятор выполнял операции поиска информации в таблицах с максимальной эффективностью. Для этого используются следующие способы организации таблиц [4,7]:
‑ бинарные деревья;
‑ хеш-адресация с открытым(случайным) перемешиванием;
‑ хеш-адресация с цепочками переполнения;
‑ упорядоченные списки.
Древовидные таблицы являются улучшенным вариантом неупорядоченных таблиц. Новые записи в древовидную таблицу по-прежнему поступают неупорядоченно. Но на этот раз место, занимаемое этими записями среди других записей в таблице, определяется значением ключевого поля. Принцип здесь такой же, как и в сортировке с помощью дерева. В общем случае каждая запись в древовидной таблице сопровождается двумя указателями:
‑один указатель хранит адрес записи с меньшим значением ключа (адрес узла-предка);
‑второй указатель хранит адрес записи с большим значением ключа (адрес узла-сына).
Процесс добавления нового элемента в древовидную таблицу производится следующим образом. Значение ключа нового элемента сравнивается со значением ключа первого элемента дерева. По результатам сравнения ключей новый элемент «поступает» в левое или правое поддерево первого элемента дерева. Далее процесс сравнения и поступления в левое или правое поддерево очередного узла продолжается аналогичным образом и до тех пор, пока не будет найден пустой элемент в нужном направлении просмотра.
Новая запись помещается в данный пустой элемент, при этом настраивается указатель с адресом узла-предка. Преимущества древовидной структуры таблицы проявляются на этапе поиска нужного элемента. Поиск прекращается либо при совпадении ключевого поля, либо при обнаружении пустого указателя.
Таблицы с вычисляемыми входами (хеш-таблицы) подробно рассмотрены в [7] на страницах 47-53.
3.4 Упорядочивание данных в таблицах
Упорядочивание данных в таблицах производится с использованием одного из алгоритмов сортировки. В трансляторах наиболее широко применяются алгоритмы Шелла и Хоара [8,9]. Алгоритм Шелла – сортировка с убывающим шагом. При сортировке Шелла сначала сравниваются и сортируются между собой значения, отстоящие один от другого на некотором расстоянии 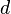 . После этого процедура повторяется для некоторых меньших значений , пока не станет отрицательным. Структурная диаграмма (диаграмма Несси-Шнейдермана) для алгоритма Шелла представлена на рис. 3.2. Алгоритм Хоара подробно рассмотрен в [8] на страницах 114 – 124.
. После этого процедура повторяется для некоторых меньших значений , пока не станет отрицательным. Структурная диаграмма (диаграмма Несси-Шнейдермана) для алгоритма Шелла представлена на рис. 3.2. Алгоритм Хоара подробно рассмотрен в [8] на страницах 114 – 124.

Рисунок 3.2 – Структурная диаграмма для алгоритма Шелла
Трансляция выражений
Польская инверсная запись (ПОЛИЗ) названа в честь польского математика Яна Лукашевича, который впервые использовал эту форму для представления выражений в математической логике. Она обладает следующими свойствами:‑ операнды располагаются в том же порядке, что в исходном выражении;‑ знаки операций располагаются в том порядке, в котором вычисляется выражение;‑ знак каждой операции записывается после соответствующих операндов.
Для построенияПОЛИЗ можно использовать приведенные выше свойства. На практике широко используется метод, который предложен в 1960 году голландским ученым Е.В.Дейкстрой [7]. Этот метод основан на использовании стека с приоритетами, позволяющего изменить порядок следования знаков операций в выражении так, что получается ПОЛИЗ. Простейший вариант этого метода применим только к простым арифметическим и логическим выражениям, содержащим простые переменные, знаки арифметических и логических операций, знаки операций отношения и круглые скобки. Каждому ограничителю, входящему в выражение, присваивается приоритет. Для знаков операции приоритеты возрастают в порядке, обратном старшинству операций. Скобки имеют низший приоритет. Арифметическое или логическое выражение рассматривается как входная строка символов. Входная строка рассматривается слева направо. Операнды переписываются в выходную строку, а знаки операций помещаются вначале в стек операций. Если приоритет входного знака равен нулю или больше приоритета знака, находящегося в вершине стека, то новый знак добавляется к вершине стека. В противном случае из стека "выталкивается" и переписывается в выходную строку знак, находящийся в вершине, а также следующие за ним знаки с приоритетами большими или равными приоритету входного знака. После этого входной знак добавляется к вершине стека.
Особенности имеет лишь обработка скобок. Открывающаяся круглая скобка, имеющая "особый" приоритет нуль, просто записывается в вершину стека и не выталкивает ни одного знака. В то же время ее не может вытолкнуть ни один знак, кроме закрывающей скобки.
Закрывающая скобка имеет приоритет 1, не превосходящий приоритет любой операции. Поэтому появление закрывающей скобки вызывает выталкивание всех знаков до ближайшей открывающей скобки включительно. В стек закрывающая скобка не записывается. Открывающая и закрывающая скобки как бы взаимно уничтожаются и в выходную строку не переносятся.
После просмотра всех символов входной cтроки происходит выталкивание всех оставшихся в стеке символов и дописывание их к выходной строке.
В контрольной работе в вариантах заданий в выражениях используются переменные с индексами и указатели функций.
Для перевода выражений, содержащих переменные с индексами, также применим стек с приоритетами. Индексные скобки [ и ] в некотором смысле играют ту же роль, что и круглые скобки. Действие этих скобок на стек, как и действие круглых скобок, состоит прежде всего в следующем. Открывающая индексная скобка всегда записывается в вершину стека, а закрывающая индексная скобка выталкивает из стека все знаки до ближайшей открывающей индексной скобки включительно.
Однако в отличие от круглых скобок одновременно с записью в стек открывающей индексной скобки туда записывается также начальное (минимальное) значение счетчика операндов операции адрес элемента массива (АЭМ), равное 2. Кроме того, после выталкивания из стека знаков закрывающей индексной скобкой и переписи их в выходную строку туда же переписывается значение счетчика операндов, а затем и сама закрывающая скобка.
Запятая, разделяющая индексные выражения, играет одновременно роль закрывающей скобки для предыдущего индексного выражения и роль открывающей скобки ‑ для последующего. Поэтому запятой можно назначить приоритет 1 как закрывающей скобке, дополнив алгоритм условием, что запятая выталкивает из стека все знаки операции до ближайшей открывающей индексной скобки исключительно. Сама запятая, как и любая закрывающая скобка, в стек не записывается. Появление запятой равносильно появлению еще одного индекса, поэтому каждая запятая добавляет в счетчик операндов операции АЭМ единицу.
Алгоритм перевода в ПОЛИЗ функции, имеющий не менее одного параметра, тот же, что для переменной с индексом. Различие состоит лишь в том, что в момент прихода закрывающей круглой скобки в выходную строку записывается символ Ф. Чтобы отличить открывающую круглую скобку в начале списка фактических параметров от открывающей круглой скобки в начале выражения, можно использовать переменную состояния F (признак функции). Эта переменная обычно имеет значение нуль. В момент появления идентификатора функции она принимает значение 1, а после занесения в стек круглой скобки и начального значения счетчика операндов, равного 2, вновь принимает значение 0. Закрывающая скобка, встретив в стеке открывающую круглую, записанную вместе со значением счетчика операндов, занесет это значение в выходную строку, запишет туда знак Ф и уничтожит в стеке круглую скобку и значение счетчика операндов.
Примеры перевода арифметических выражений рассмотрены в [7] на страницах 130 – 144.








