 2018-01-21
2018-01-21 583
5831. При увеличении числа степеней свободы (n ® ¥) стремится к стандартизированному нормальному распределению:
а) распределение Стьюдента; б) c2–распределение; в) распределение Фишера.
| 1. Да, все эти распределения стремятся к стандартизированному нормальному распределению. 2. Только а). 3. Только б). | 4. Только а) и б). 5. Нет, ни одно из указанных распределений не стремиться к стандартизированному нормальному распределению. |
2. Ковариация является…
| 1. абсолютной мерой взаимосвязи переменных. 2. относительной мерой взаимосвязи переменных. 3. мерой тесноты зависимости между случайными величинами. | 4. смешанным моментом распределения порядка 1,1. 5. центральным моментом порядка 0,0. |
3. Верными являются следующие перечисленные свойства ковариации двух случайных величин:
а) sxy = syx;) sxx = D (X) =  ; в) sxy = 0; г) sxy £ sx ×sy; д) cov(a + bX, c + dY) = bdcov(X,Y).
; в) sxy = 0; г) sxy £ sx ×sy; д) cov(a + bX, c + dY) = bdcov(X,Y).
| 1. Да, все верные. 2. Только а) и б). 3. Только а), б) и в). | 4. Только а), б) и д). 5. Таких свойств у ковариации нет. |
4. Какие из перечисленных свойства коэффициента корреляции случайных величин X и Y являются верными?
а) rxx = 1; б) rxy = ryx; в) –1 £ rxy £ 1; г) rxy = 0, если СВ X и Y – независимы;
д) | rxy | = 1, если Y = a + bx, где a и b – некоторые константы.
| 1. Да, все являются верными. 2. Только а) и б). 3. Только а), б) и в). | 4. Только а), б) и д). 5. Таких свойств у коэффициента корреляции нет. |
5. Две СВ независимы, если…
| 1. они некоррелированы. 2. они коррелированы. 3. rxy = 0. 4. sxy = syx. | 5. выполнено любое из следующих соотношений: а) P(x; y) = P(x)× P(y), б) f(x; y) = f(x)× f(y), д) F(x; y) = F(x)× F(y). |
6. Какое из перечисленных утверждений верно?
| 1. Независимость СВ X и Y Û некоррелированность СВ X и Y. 2. Независимость СВ X и Y Þ некоррелированность СВ X и Y. 3. Некоррелированность СВ X и Y Þ независимость СВ X и Y. | 4. Независимость СВ X и Y  некоррелированность СВ X и Y.
5. Независимость СВ X и Y = некоррелированность СВ X и Y. некоррелированность СВ X и Y.
5. Независимость СВ X и Y = некоррелированность СВ X и Y.
|
7. Доход населения имеет нормальный закон распределения со средним значением 2000 руб. и средним квадратическим отклонением 962 руб. Обследуется 1000 человек. Какое количество из них будет иметь доход больше 3000 руб.?. Назовите наиболее вероятное количество.
| 1. 100. 2. 150. 3. 200. | 4. 250. 5. 300. |
8. Известно, что результат (балл) сдачи теста по эконометрике имеет нормальный закон распределения со средним значением 30. 20% студентов получили не менее 35 баллов. Можно ли сказать, чему равно среднее квадратическое отклонение указанной случайной величины?
| 1. 2. 2. 3. 3. 4. | 4. 5. 5. 6. |
9. Точечная оценка называется эффективной, если…
| 1. её математическое ожидание равно оцениваемому параметру. 2. систематическая ошибка оценивания равно нулю. 3. её дисперсия равна нулю. | 4. с увеличением объёма выборки дисперсия оценки стремится к нулю. 5. её дисперсия меньше дисперсии любой другой альтернативной оценки при фиксированном объёме выборки. |
10. Чем отличаются интервальные оценки для M(X) для нормальной случайной величины при известной и неизвестной дисперсии?
| 1. Размахом получаемого доверительного интервала. 2. Задаваемой доверительной вероятностью. 3. Точностью получаемых вычислений для границ доверительных интервалов. | 4. Для построения интервала используется статистика: в первом случае стандартизированная нормальная, а во втором – имеющая распределение Стьюдента. 5. Для этого используется статистика: в первом случае нормально распределённая, а во втором – F-распределение Фишера. |
11. Какие из перечисленных этапов входят в общую схему проверки статистических гипотез?
а) Формулировка проверяемой (нулевой) и альтернативной (конкурирующей) гипотез.
б) Выбор соответствующего уровня значимости.
в) Определение объёма выборки.
г) Выбор критерия для проверки нулевой гипотезы.
д) Определение критической области и области принятия гипотезы.
е) Вычисление по выборочным данным наблюдаемого значения статистического критерия.
ж) Принятие статистического решения.
з) Построение доверительного интервала.
| 1. Все входят в общую схему. 2. Все, кроме в). 3. Все, кроме в) и з). | 4. Все, кроме ж). 5. Все, кроме з). |
12. Ошибка второго рода при проверке статистических гипотез происходит, если…
| 1. будет отвергнута нулевая гипотеза. 2. будет принята нулевая гипотеза. 3. будет отвергнута правильная нулевая гипотеза. | 4. будет принята альтернативная гипотеза, в то время как верна нулевая. 5. будет принята нулевая гипотеза, в то время как верна альтернативная. |
13. Если a – уровень значимости, а (1 – b) – мощность критерия, то…
| 1. a – вероятность совершить ошибку I рода, а b – вероятность совершить ошибку II рода. 2. a – вероятность не совершить ошибку I рода, а b – вероятность не совершить ошибку II рода. 3. a – вероятность совершить ошибку I рода, а (1 – b) – вероятность совершить ошибку II рода. | 4. (1 – a) – вероятность совершить ошибку I рода, а (1 – b) – вероятность не совершить ошибку II рода. 5. (1 – a) – вероятность не совершить ошибку I рода, а b – вероятность совершить ошибку II рода. |
14. В Волгоградской академии государственной службы проведён анализ успеваемости среди студентов и студенток за последние 10 лет. СВ X и Y – соответственно их суммарный балл за всё время учёбы. Получены следующие результаты:  Можно ли утверждать, что девушки в среднем учатся лучше ребят? Принять a = 0,05.
Можно ли утверждать, что девушки в среднем учатся лучше ребят? Принять a = 0,05.
| 1. Да, девушки в среднем учатся лучше ребят. 2. Нет, девушки в среднем не учатся лучше ребят. 3. Проверяемая гипотеза M(X) = M(Y) была принята. | 4. Проверяемая гипотеза M(X) > M(Y) была отклонена. 5. Оснований для однозначного утверждения, что девушки в среднем учатся лучше ребят, нет. |
15. Определяется наличие линейной зависимости между уровнями инфляции (X) и (Y) безработицы в стране за 11 лет. По статистическим данным рассчитан выборочный (эмпирический) коэффициент корреляции rxy = rв = – 0,34. Существует ли значимая линейная связь между указанными показателями в данной стране на рассматриваемом временном интервале? Принять a = 0,02.
| 1. Проверяемая гипотеза rxy = 0 была принята. 2. Проверяемая гипотеза rxy ¹ 0 была отклонена. 3. rxy существенно не отличается от нуля, т.е. линейной зависимости между инфляцией (X) и безработицей (Y) не существует. | 4. rxy существенно отличается от нуля: между инфляцией (X) и безработицей (Y) существует определённая отрицательная линейная зависимость. 5. rxy существенно отличается от нуля: между инфляцией (X) и безработицей (Y) существует определённая положительная линейная зависимость. |
16. Основными этапами регрессионного анализа являются:
а) выбор вида связи, т.е. формулы уравнения регрессии (спецификация модели);
б) определение параметров выбранного уравнения (параметризация);
в) проверка тесноты линейной связи между показателями;
г) анализ качества уравнения (верификация);
д) улучшение, совершенствование полученного уравнения.
| 1. Это – не все этапы. 2. Все эти этапы, кроме в). 3. Все эти этапы, кроме г). | 4. Все эти этапы, кроме д). 5. Все эти этапы. |
17. Какие из приведённых уравнений являются теоретической линейной регрессионной моделью и эмпирическим уравнением регрессии:
а) M(Y|X = xi) = a + bxi;
б) Y = a + bX + e;
в) yi = a + bxi + ei;
г) 
| д)  е) yi = a + bxi + ei;
ж) yi = a + bxi;
е) yi = a + bxi + ei;
ж) yi = a + bxi;
|
| 1. а), б), в) и г), д), е), ж). 2. б), в) и г), е). 3. а), б), и д), е). | 4. а), б), в) и г), е). 5. а), б) и г), д), е). |
18. Коэффициенты a и b эмпирического уравнения регрессии могут быть оценены, исходя из условий минимизации следующих сумм:
а) 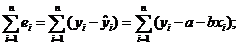
б) 
в) 
г) 
д) 
е) 
причём, это – отражение следующих методов:
| 1. а) и б) – метод моментов, в) – метод наименьших модулей, д) и е) – метод максимального правдоподобия; 2. а) – метод моментов, в) – метод наименьших модулей, е) – метод наименьших квадратов; 3. в) и г) – метод наименьших модулей, д) и е) – метод наименьших квадратов; | 4. в) – метод наименьших модулей, д) – метод наименьших квадратов; 5. а) – метод максимального правдоподобия, в) – метод наименьших модулей, д) – метод наименьших квадратов. |
19. Какого вида связь существует между эмпирическими коэффициентами линейной регрессии yi = a + bxi + ei и выборочным коэффициентом корреляции?
1.  ;
2. ;
2.  ;
3. ;
3.  ; ;
| 4.  ;
5. ;
5.  . .
|
20. Какие из ниже приведённых утверждений – истинны, и какие – ложны (или не определены)?
а) Случайная погрешность ei и отклонение ei совпадают.
б) В регрессионной модели объясняющая переменная является фактором изменения зависимой переменной.
в) Линейное уравнение регрессии является линейной функцией относительно входящих в него переменных.
г) Коэффициенты теоретического и эмпирического уравнений регрессии являются по сути СВ.
д) Значения объясняющей переменной парного линейного уравнения регрессии являются СВ.
е) Коэффициент b1 эмпирического парного линейного уравнения регрессии показывает процентное изменение зависимой переменной Y при однопроцентном изменении X.
ж) Коэффициент b1 регрессии Y на X имеет тот же знак, что и коэффициент корреляции rxy.
з) МНК удобен тем, что нахождение оценок коэффициентов регрессии сводится к решению системы линейных алгебраических уравнений.
и) Парная линейная регрессионная модель имеет слабую практическую значимость, так как любая экономическая переменная зависит не от одной, а от большого числа факторов.
| 1. а), в), д), е) – истинно, б), г), ж), з), и) – ложно или не определено. 2. б), в), ж), з) – истинно, а), г), д), е), и) – ложно или не определено. 3. а), б), в), г) – истинно, д), е), ж), з), и) – ложно или не определено. | 4. а), г), д), и) – истинно, б), в), е), ж), з) – ложно или не определено. 5. б), в), д), е), з) – истинно, а), г), ж), и) – ложно или не определено. |
21. Как Вы считаете, если по одной и той же выборке рассчитаны регрессии Y.
на X и X на Y, то совпадут ли в этом случае линии регрессии?
| 1. Нет, практически никогда. 2. Да, совпадут всегда. 3. Совпадут, если выборка большая. | 4. Совпадут, если выборка малая. 5. Совпадут, если данные несгруппированы. |
22. Суть МНК состоим в…
| 1. минимизации суммы квадратов коэффициентов регрессии. 2. минимизации суммы квадратов значений зависимой переменной. 3. минимизации суммы квадратов отклонений точек наблюдений от точек эмпирического уравнения регрессии. | 4. минимизации суммы квадратов отклонений точек эмпирического уравнения регрессии от точек теоретического уравнения регрессии. 5. минимизации суммы квадратов отклонений точек наблюдений от точек теоретического уравнения регрессии. |
23. Если переменная X принимает среднее по выборке значение  , то какие из. ниже приведённых утверждений – истинны?
, то какие из. ниже приведённых утверждений – истинны?
а) Наблюдаемая величина зависимой переменной Y равна среднему значению  .
.
б) Рассчитанное по уравнению регрессии Y = a + bx значение переменной Y.
в среднем равно , но не обязательно равно ему в каждом конкретном случае.
в) Рассчитанное по уравнению регрессии Y = a + bx значение переменной Y.
в среднем равно .
г) Отклонение значения Y(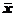 ) минимально среди всех других отклонений.
) минимально среди всех других отклонений.
д) Значение Y() обязательно равно .
| o а) и б). o а) и в). o б) и г). | o в) и г). o в) и д). |
24. По выборке объёма n = 10 получены следующие данные:

Рассчитайте оценки коэффициентов регрессии Y на X ( ) и X на Y (
) и X на Y ( ).
).
| o a = 0,066; b = – 8,523; c = – 353,487; d = 46,573. o a = 46,573; b = 0,066; c = – 353,487; d = 8,523. o a = 8,523; b = 46,573; c = – 0,066; d = 353,487. | o a = 353,487; b = 8,523; c = – 46,573; d = – 0,066. o a = – 0,066; b =– 353,487; c = – 8,523; d = 46,573. |
25. «Грубое» правило анализа статистической значимости коэффициентов регрессии заключается в том, что если t – статистика ( или
или  ) заключена в следующих пределах:
) заключена в следующих пределах:
а) | t | £ 1; б) 1 < | t | £ 2; в) 2 < | t | £ 3; г) | t | > 3, то…
| 1. а) коэффициент регрессии значим с a = 0,01; б) коэффициент регрессии значим с a = 0,02; в) коэффициент регрессии значим с a = 0,05; г) коэффициент регрессии значим с a = 0,1. 2. а) коэффициент регрессии значим с a = 0,1; б) коэффициент регрессии значим с a = 0,05; в) коэффициент регрессии значим с a = 0,02; г) коэффициент регрессии значим с a = 0,01. 3. а) коэффициент регрессии не может быть признан значимым; б) Коэффициент слабо значим (a = 0,01); в) коэффициент значим с вероятностью a = 0,05; г) почти гарантировано наличие линейной корреляционной связи (a @ 1). | 4. а) коэффициент регрессии не может быть признан значимым, доверительная вероятность составляет g < 0,7; б) Коэффициент слабо значим (0,7 £ g < 0,95); в) коэффициент значим 0,95 £ g < 0,99; г) почти гарантировано наличие линейной корреляционной связи (g @ 1). 5. а) коэффициент регрессии не может быть признан значимым, доверительная вероятность составляет a < 0,7; б) Коэффициент слабо значим (0,7 £ a < 0,95); в) коэффициент значим 0,95 £ a < 0,99; г) почти гарантировано наличие линейной корреляционной связи (a @ 1). |
26. В чём суть предсказания индивидуальных значений зависимой переменной?
| 1. В построении доверительного интервала, в котором оказываются 100a% всех точек наблюдения. 2. В построении доверительного интервала, за границами которого оказываются 100a% всех точек наблюдения. 3. В построении доверительного интервала, за границами которого могут оказаться не более 100a% всех точек наблюдения при каждом конкретном значении объясняющей переменной. | 4. В построении доверительного интервала, за границами которого могут оказаться не более 100a% всех точек наблюдения при каждом конкретном значении объясняемой переменной. 5. В построении доверительного интервала, за границами которого могут оказаться не более 100g% всех точек наблюдения при каждом конкретном значении объясняющей переменной. |
27. В каких пределах изменяется коэффициент детерминации R2?
| 1. От – 1 до + 1. 2. От 0 до +1. 3. От 0 до + ¥. | 4. От 1 до + ¥. 5. От – ¥ до + ¥. |
28. Явление гетeроскедастичности – это…
| 1. постоянство дисперсии. 2. постоянство дисперсии отклонений. 3. непостоянство дисперсии. | 4. непостоянство дисперсии отклонений ei. 5. явление, при котором вероятные распределения случайных отклонений ei при различных наблюдениях одинаковы. |
29. Что позволяет проверить статистика Дарбина–Уотсона DW?
| 1. Наличие или отсутствие гетероскедастичности. 2. Наличие корреляции переменных. 3. Отсутствие зависимости между переменными. | 4. Наличие или отсутствие автокорреляции между наблюдаемыми показателями. 5. Наличие нелинейной регрессии между переменными. |
30. Мультиколлинеарность – это…
| 1. взаимосвязь переменных. 2. линейная взаимосвязь переменных. 3. линейная взаимосвязь объясняющих переменных. | 4. сильная корреляционная зависимость между объясняемой и объясняющей переменными. 5. сильная корреляционная зависимость между объясняемыми переменными. |
31. Оценка значимости параметров уравнения регрессии осуществляется на основе:
а) t - критерия Стьюдента;
б) F - критерия Фишера – Снедекора;
в) средней квадратической ошибки;
г) средней ошибки аппроксимации.
32. Коэффициент регрессии в уравнении  , характеризующем связь между объемом реализованной продукции (млн. руб.) и прибылью предприятий автомобильной промышленности за год (млн. руб.) означает, что при увеличении объема реализованной продукции на 1 млн. руб. прибыль увеличивается на:
, характеризующем связь между объемом реализованной продукции (млн. руб.) и прибылью предприятий автомобильной промышленности за год (млн. руб.) означает, что при увеличении объема реализованной продукции на 1 млн. руб. прибыль увеличивается на:
а) 0,5 %;
г) 0,5 млн. руб.;
в) 500 тыс. руб.;
г) 1,5 млн. руб.
33. Корреляционное отношение (индекс корреляции) измеряет степень тесноты связи между Х и Y:
а) только при нелинейной форме зависимости;
б) при любой форме зависимости;
в) только при линейной зависимости.
34. По направлению связи бывают:
а) умеренные;
б) прямые;
в) прямолинейные.
35. По 17 наблюдениям построено уравнение регрессии:  . Для проверки значимости уравнения вычислено наблюдаемое значение t - статистики: 3.9. Вывод:
. Для проверки значимости уравнения вычислено наблюдаемое значение t - статистики: 3.9. Вывод:
а) Уравнение значимо при a = 0,05;
б) Уравнение незначимо при a = 0,01;
в) Уравнение незначимо при a = 0,05.
36. Каковы последствия нарушения допущения МНК «математическое ожидание регрессионных остатков равно нулю»?
а) Смещенные оценки коэффициентов регрессии;
б) Эффективные, но несостоятельные оценки коэффициентов регрессии;
в) Неэффективные оценки коэффициентов регрессии;
г) Несостоятельные оценки коэффициентов регрессии.
37. Какое из следующих утверждений верно в случае гетероскедастичности остатков?
а) Выводы по t и F- статистикам являются ненадежными;
б) Гетероскедастичность проявляется через низкое значение статистики Дарбина-Уотсона;
в) При гетероскедастичности оценки остаются эффективными;
г) Оценки параметров уравнения регрессии являются смещенными.
38. На чем основан тест ранговой корреляции Спирмена?
а) На использовании t – статистики;
б) На использовании F – статистики;
в) На использовании  ;
;
г) На графическом анализе остатков.
39. На чем основан тест Уайта?
а) На использовании t – статистики;
б) На использовании F – статистики;
в) На использовании ;
г) На графическом анализе остатков.
40. Каким методом можно воспользоваться для устранения автокорреляции?
а) Обобщенным методом наименьших квадратов;
б) Взвешенным методом наименьших квадратов;
в) Методом максимального правдоподобия;
г) Двухшаговым методом наименьших квадратов.
41. Как называется нарушение допущения о постоянстве дисперсии остатков?
а) Мультиколлинеарность;
б) Автокорреляция;
в) Гетероскедастичность;
г) Гомоскедастичность.
42. Фиктивные переменные вводятся в:
а) только в линейные модели;
б) только во множественную нелинейную регрессию;
в) только в нелинейные модели;
г) как в линейные, так и в нелинейные модели, приводимые к линейному виду.
43. Если в матрице парных коэффициентов корреляции встречаются  , то это сви детель ствует:
, то это сви детель ствует:
а) О наличии мультиколлинеарности;
б) Об отсутствии мультиколлинеарности;
в) О наличии автокорреляции;
г) Об отсутствии гетероскедастичности.
44. С помощью какой меры невозможно избавиться от мультиколлинеарности?
а) Увеличение объема выборки;
б) Исключения переменных высококоррелированных с остальными;
в) Изменение спецификации модели;
г) Преобразование случайной составляющей.
45. Если  и ранг матрицы А меньше (К-1) то уравнение:
и ранг матрицы А меньше (К-1) то уравнение:
а) сверхиденцифицировано;
б) неидентифицировано;
в) точно идентифицировано.
46.Уравнение регрессии имеет вид:
а)  ;
;
б)  ;
;
в)  .
.
47. В чем состоит проблема идентификации модели?
а) получение однозначно определенных параметров модели, заданной системой одновременных уравнений;
б) выбор и реализация методов статистического оценивания неизвестных параметров модели по исходным статистическим данным;
в) проверка адекватности модели.
48. Какой метод применяется для оценивания параметров сверхиденцифицированного уравнения?
а) Обобщенный МНК
б) ДМНК, КМНК;
в) КМНК;
г) ДМНК.
49. Если качественная переменная имеет k альтернативных значений, то при моделировании используются:
а) (k-1) фиктивная переменная;
б) k фиктивных переменных;
в) (k+1) фиктивная переменная;
г) 2k фиктивных переменных.
50. Анализ тесноты и направления связей двух признаков осуществляется на основе:
а) парного коэффициента корреляции;
б) коэффициента детерминации;
в) множественного коэффициента корреляции.
г) статистики Стьюдента.
51. В линейном уравнении  x=а0+a1х коэффициент регрессии показывает:
x=а0+a1х коэффициент регрессии показывает:
а) тесноту связи;
б) долю дисперсии "Y", зависимую от "X";
в) на сколько в среднем изменится "Y" при изменении "X" на одну единицу;
г) ошибку коэффициента корреляции.
52. Какой показатель используется для определения части вариации, обусловленной изменением величины изучаемого фактора?
а) коэффициент вариации;
б) коэффициент корреляции;
в) коэффициент детерминации;
г) коэффициент эластичности.
53. Коэффициент эластичности показывает:
а) на сколько % изменится значение y при изменении x на 1 %;
б) на сколько единиц своего измерения изменится значение y при изменении x на 1 %;
в) на сколько % изменится значение y при изменении x на ед. своего измерения.
г) на сколько единиц своего измерения изменится значение y при изменении x на ед. своего измерения.
54. Какие методы можно применить для обнаружения гетероскедастичности?
а) Тест Голфелда-Квандта;
б) Тест ранговой корреляции Спирмена;
в) Тест Дарбина- Уотсона.
г) Критерий Фишера.
55. На чем основан тест Голфельда -Квандта
а) На использовании t – статистики;
б) На использовании F – статистики;
в) На использовании ;
г) На графическом анализе остатков.








