 2017-10-25
2017-10-25 3559
3559Лабораторная работа № 5
Использование скриптовых сценариев VBS при разработке демонстрационной модели контроля информационного потока методом Хэмминга в браузере MS Internet Explorer.
 |
Ижевск 2015
СоставителИ:
в.п.Тарануха, канд.техн.наук, доцент
шАМСИАХМЕТОВ о.я.
Рецензенты - канд. физ.-мат. наук, доцент Клишин С.В.,
доктор техн. наук, профессор ушаков П.А.
МЕТОДИЧЕСКОЕ РУКОВОДСТВО к лабораторной работе №5“Использование скриптовых сценариев VBS при разработке демонстрационной модели контроля информационного потока методом Хэмминга в браузере MS Internet Explorer.
” пО курсу ” ИНФОРМАТИКА” профиля
”Проектирование и технология радиоэлектронных средств”/ Тарануха В.П.,ШАМСИАХМЕТОВ О.Я.-: Ижевск: Издательство ИжГТУ, 2015.- 78 c.
Настоящие методические указания определяют последовательность выполнения лабораторной работы по дисциплине «ИНФОРМАТИКА» и включают в себя рекомендации ПО СОЗДАНИЮ скриптовых сценариев на языке vbs для внедрения в качестве элементов управления в браузер internet explorer и разработке программной имитационной модели канала связи с коррекцией ошибок методом хэмминга.
© Тарануха В.П.,шамсиахметов О.Я.
© ИжГТУ, 2015
Лабораторная работа № 5
Использование скриптовых сценариев VBS при разработке демонстрационной модели контроля информационного потока методом Хэмминга в браузере MS Internet Explorer.
Краткая теория.
Код Хэмминга.
Код Хемминга – это блочный код, позволяющий исправлять одиночные и фиксировать двойные ошибки, разработанный Ричардом Хеммингом в сороковых годах прошлого столетия.
Коды Хэмминга — первые из самоконтролирующихся и самокорректирующихся кодов. Построены они применительно к двоичной системе счисления.
Это алгоритм, позволяющий закодировать какое-либо информационное сообщение и после передачи по каналу связи определить появилась ли какая-то ошибка в этом сообщении из-за помех и, при возможности, восстановить это сообщение.
Код Хэмминга состоит из двух частей. Первая часть кодирует исходное сообщение, вставляя в него в определённых местах контрольные биты, вычисленные особым образом. Вторая часть получает входящее сообщение и заново вычисляет контрольные биты по тому же алгоритму, что и первая часть. Если все вновь вычисленные контрольные биты совпадают с полученными, то сообщение получено без ошибок. В противном случае, выводится сообщение об ошибке и при возможности ошибка исправляется.
В то время Ричард Хемминг работал в лаборатории Белла на электромеханической счетной машине Bell Model V. Ввод данных в эту машину осуществлялся с помощью перфокарт. Это была самая ненадежная часть вычислительной машины. Перфокарты часто считывались неправильно. Исправление и обнаружение ошибок ввода данных отнимало огромное количество времени, а пропущенные ошибки могли привести к неверным результатам работы.
Желая застраховаться от возможных сбоев и ускорить процесс обработки данных, Хемминг много работал над построением эффективных алгоритмов, позволяющих быстро обнаруживать и исправлять ошибки, и в 1950 году опубликовал способ кодирования, являющийся одним из самых известных на сегодняшний день.
Идея кодов Хемминга заключается в разбиении данных на блоки фиксированной длины и вводе в эти блоки контрольных бит, дополняющих до четности несколько пересекающихся групп, охватывающих все биты блока.
Ричард Хемминг рассчитал минимальное количество проверочных бит, позволяющих однозначно исправлять однократные ошибки.
Если длина информационного блока, который требуется закодировать - m бит и количество контрольных бит, используемых для его кодирования, – k, то закодированный блок будет иметь длину: n = m+k бит.
Для каждого блока такой длины возможны n различных комбинаций, содержащих ошибку.
Таким образом, для каждого передаваемого информационного блока может существовать n–блоков, содержащих однократную ошибку, и один блок - без ошибок. Следовательно, максимальное количество различных закодированных блоков, содержащих не больше одной ошибки, будет: 2m(n+1), где n = m+k.
Если для информационных данных длиной m подобрать такое количество контрольных бит k, что максимально возможное количество различных последовательностей длиной m+k будет больше или равно максимальному количеству различных закодированных информационных блоков, содержащих не больше одной ошибки, то точно можно утверждать, что существует такой метод кодирования информационных данных с помощью k контрольных бит, который гарантирует исправление однократной ошибки.
Следовательно, минимальное количество контрольных бит, необходимых для исправления однократной ошибки, определяется из неравенства:
2m * (n+1) ≤ 2n
Учитывая, что n = m + k, получаем:
k ≤ 2k – m – 1
Так как количество бит должно быть целым числом, то k, вычисленное с помощью этого уравнения, необходимо округлить до ближайшего большего целого числа.
Например, для информационных данных длиной 8 необходимо 4 контрольных бита, чтобы обеспечить исправление однократных ошибок, а для данных длинной 128 бит необходимо 8 контрольных бит.
Мало определить минимальное количество контрольных бит, необходимых для исправления ошибки. Необходимо разработать алгоритм проверки данных с помощью этих контрольных разрядов. Ричард Хемминг предложил следующий алгоритм.
Все биты, порядковые номера которых являются степенью двойки, – это контрольные разряды. То есть если порядковый номер бита обозначить символом ‘ n ’, то для контрольных бит должно быть справедливо равенство: n=2k, где к – любое положительное целое число.
Например, для закодированной последовательности длиной 12 бит проверочными будут: 1, 2, 4 и 8 биты, так как 20 = 1, 21 = 2, 22 = 4, 23 = 8.
Каждый выбранный, таким образом, контрольный бит будет проверять определенную группу бит, т.е. в контрольный бит будет записана сумма по модулю два всех битов группы (дополнение до четного количества единиц), которую он проверяет.
Для того, чтобы определить какими контрольными битами контролируют бит, необходимо разложить его порядковый номер по степени 2. Таким образом, девятый бит будет контролироваться битами 1 и 8, так как 9 = 20 + 23 = 1 + 8.
Рассмотрим пример 1:
Допустим, у нас есть сообщение в виде одного символа, например “а”, которое необходимо передать без ошибок. Для этого сначала нужно наше сообщение закодировать при помощи Кода Хэмминга.Изначально символ “а” представляется кодом ANCII (числа от 0 до 255) в виде числа 97. Необходимо представить его в бинарном виде:
01100001
Необходимо определиться с длиной информационного слова, то есть длиной строки из нулей и единиц, которыми будем кодировать.Длину слова выберем равным байту(8 битам), исходя из общего количества возможных символов (у нас 256).
Так как один символ занимает в памяти 8 бит, то в одно кодируемое слово помещается ровно два ASCII символа.
1. Определим необходимое количество контрольных разрядов. Расчет будем вести по формуле: k ≤ 2k – m – 1
где k – количество контрольных разрядов, m – количество информационных разрядов. Так как количество бит должно быть целым числом, то k, вычисленное с помощью этого уравнения, необходимо округлить до ближайшего большего целого числа.
Подберем минимальное значение k,чтобы неравенство выполнялось:
4 ≤ 24 – 8 – 1
4 ≤ 7
Таким образом, число контрольных бит - 4.
2. Определим расположение проверочных бит в результирующей закодированной последовательности. Обозначим информационные биты символом И, а контрольные биты символом К. Индекс около этих символов будет означать их порядковый номер в закодированной последовательности.
Контрольные биты будут занимать четыре позиции с порядковыми номерами, равными степени двойки: 20, 21, 22, 23 => 1,2,4,8.
Размещение информационных в результирующей последовательности будет следующим:
| К1 | К2 | И3 | К4 | И5 | И6 | И7 | К8 | И9 | И10 | И11 | И12 |
Осталось определить значения проверочных бит.
3. Определим, какие группы контролируют проверочные биты. Для этого разложим порядковые номера информационных бит по степени двойки:
И3: 3 = 20 + 21 = 1 + 2=3 => Информационный бит И3 проверяется контрольными битами К1 и К2.
И5: 5 = 20 + 22 = 1 + 4=5 => Информационный бит И5 проверяется контрольными битами К1 и К4.
И6: 6 = 21 + 22 = 2 + 4=6 => Информационный бит И6 проверяется контрольными битами К2 и К4.
И7: 7 = 20 + 21 + 22 = 1 + 2 + 4=7 => Информационный бит И7 проверяется контрольными битами К1, К2 и К4.
И9: 9 = 20 + 23 = 1 + 8=9 => Информационный бит И9 проверяется контрольными битами К1 и К8.
И10: 10 = 22 + 23 = 2 + 8=10 => Информационный бит И10 проверяется контрольными битами К2 и К8.
И11: 11 = 20 + 21 + 23 = 1 + 2 + 8=11 => Информационный бит И11 проверяется контрольными битами К1, К2 и К8.
И12: 12 = 22 + 23 = 4 + 8=12 => Информационный бит И12 проверяется контрольными битами К4 и К8.
4. Рассчитаем значения контрольных бит. Для этого определим группы для всех контрольных бит, просуммируем их по модулю два (исключающее или), а результат запишем в соответствующие контрольные биты (дополним группы до четности, то есть до 0):
К1 = И3 + И5 + И7 + И9 + И11 = 0 + 1 + 0 + 0 + 0 = 1
К2 = И3 + И6 + И7 + И10 + И11= 0 + 1 + 0 + 0 + 0 = 1
К4 = И5 + И6 + И7+И12 = 1 + 1 + 0+1 = 1
К8 = И9 + И10 + И11+И12 = 0 + 0 + 0+1 =1
Таким образом, закодированная последовательность будет иметь следующий вид:
| К1 | К2 | И3 | К4 | И5 | И6 | И7 | К8 | И9 | И10 | И11 | И12 |
5. Проверим на четность единиц все группы, контролируемые проверочными разрядами:
К1 = К1+И3 + И5 + И7 + И9 + И11 =1+ 0 + 1 + 0 + 0 + 0 = 0
К2 = К2+И3 + И6 + И7 + И10 + И11= 1+0 + 1 + 0 + 0 + 0 = 0
К4 = К4+И5 + И6 + И7+И12 =1+ 1 + 1 + 0+1 = 0
К8 = К8+И9 + И10 + И11+И12 =1+ 0 + 0 + 0+1 =0
У нас все контрольные разряды равны 0, это значит что информация закодировано верно.
6. Введем искусственно ошибку в один из разрядов (ошибка может быть только в одном контрольном или информационном разряде), например в И11 (вместо 0 появилась 1)
7. Заново вычислим контрольные разряды:
Кновый 1 = И3 + И5 + И7 + И9 + И11 = 0 + 1 + 0 + 0 + 1 = 0
Кновый 2 = И3 + И6 + И7 + И10 + И11= 0 + 1 + 0 + 0 + 1 = 0
Кновый 4 = И5 + И6 + И7+И12 = 1 + 1 + 0+1 = 1
Кновый 8 = И9 + И10 + И11+И12 = 0 + 0 + 1+1 =0
8. Сложим новые контрольные разряды со старыми:
К1 = Кстарый 1+ Кновый 1=Кстарый 1+И3 + И5 + И7 + И9 + И11 = 1+0 + 1 + 0 + 0 + 1 = 1
К2 = Кстарый 2+ Кновый 2=Кстарый 2+И3 + И6 + И7 + И10 + И11= 1+0 + 1 + 0 + 0 + 1 = 1
К4 = Кстарый 4+ Кновый 4=Кстарый 4+И5 + И6 + И7+И12 = 1+1 + 1 + 0+1 = 0
К8 = Кстарый 8+ Кновый 8=Кстарый 8+И9 + И10 + И11+И12 = 1+0 + 0 + 1+1 =1
Получили номер ошибки в двочном коде К8 К4 К2 К1→1011.
Переведем в десятичный код номер ошибки 1*20+1*21+0*22+1*23=1+2+8=11 разряд
9. Инвертируем разряд И11 (с 1 на 0). Код восстановлен.
Можно доработать описанный выше алгоритм, и сделать так, чтобы он не только исправлял однократные ошибки, но и фиксировал двойные. Для этого, после того, как информационные данные закодированы, к полученному коду приписывается еще один разряд, дополняющий его до четности.
Если предположить, что количество ошибок - не более двух, то:
а. Данные верны, если во всех контрольных группах количество единиц - четное, и общее количество единиц - тоже четное.
б. Произошла однократная ошибка, если в некоторых контрольных группах количество единиц - нечетное, и общее количество единиц - нечетное.
в. Ошибка в дополнительном контрольном разряде, если во всех контрольных группах количество единиц - четное, а общее количество единиц - нечетное.
г. Двойная ошибка, если в некоторых контрольных группах количество единиц - нечетное, а общее количество единиц - четное.
Алгоритм коррекции ошибок Хемминга - достаточно прост и надежен. При этом эффективность кода растет при увеличении информационных блоков. Так, для кодирования 8 бит данных избыточность составляет чуть больше 57%, для кодирования 256 бит избыточность будет 3.5%, а для 1024 – 1%.
Алгоритм кодирования Хэмминга - очень популярен и позволяет значительно повысить надежность передачи и хранения информации. Особенно, он выгоден при кодировании больших блоков данных. Существует большое количество различных способов реализации этого алгоритма.
ASCII коды.
В практике создания веб приложений часто необходимо вставить спецсимвол (копирайт, авторское право, стрелку). Для этого используют ASCII коды, которые, вставляют в контекст кода HTML. При выводе они отображаются как обычные символы.
ASCII (англ. American Standard Code for Information Interchange) — американский стандартный код для обмена информацией. ASCII представляет собой кодировку для представления десятичных цифр, латинского и национального алфавитов, знаков препинания и управляющих символов.
Числа являются языком компьютера. В компьютере для связи с программами (и другими компьютерами) знаки и символы преобразуются в числовой вид.
В 1960-х годах необходимость стандартизации привела к появлению кодировки ASCII (произносится «аски»). Таблица набора ASCII состоит из 128 чисел, присвоенных соответствующим знакам. Кодировка ASCII обеспечивает способ хранения данных в компьютерах и обмена этими данными с другими компьютерами и программами.
Изначально разработанная как 7-битная, с широким распространением 8-битного байта ASCII стала восприниматься как половина 8-битной. В компьютерах обычно используют расширения ASCII с задействованной второй половиной байта.
Текст в кодировке ASCII не содержит информацию о форматировании, например о полужирном или наклонном начертании или о шрифтах. Кодировка ASCII используется при работе с программой «Блокнот» или при сохранении файла в виде обычного текста в приложении Microsoft Office Word. Тексты в формате ASCII хорошо подвергаются обработке программами оптического распознавания текста (OCR).
Помимо набора знака с клавиатуры и в тех случаях, когда символ отсутствует в раскладке клавиатуры, можно использовать код символа для его быстрого набора.
Первые таблицы кодировки, созданные в США, не использовали восьмой бит в байте. Текст представлялся как последовательность байт, но восьмой бит не учитывался (он применялся в служебных целях). Общепризнанным стандартом стала таблица ASCII (American Standard Code for Information Interchange).
Первые 32 символа таблицы ASCII (от 00 до 1F) (Таблица 1) использовались для непечатаемых символов. Они были предназначены для управления печатающим устройством и т.п. Остальная часть – от 20 до 7F – обычные (печатаемые) символы.
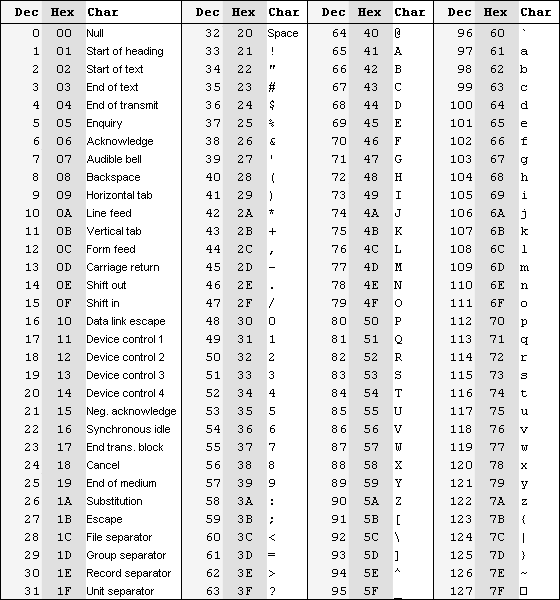
Таблица 1. Кодировка ASCII (American Standard Code for Information Interchange
В этой кодировке представлены только латинские буквы, используемые в английском языке. Есть также арифметические и другие служебные символы. Но нет русских букв или специальных латинских для немецкого или французского языка.
Это легко объяснить – кодировка разрабатывалась именно как американский стандарт. Когда компьютеры стали применяться во всём мире, потребовалось кодировать и другие символы.
Для этого было принято решение использовать восьмой бит в каждом байте. Тем самым оказались доступны ещё 128 значений (от 80 до FF), которые можно было использовать для кодирования символов.
Первая из восьмибитных таблиц – “расширенный ASCII” (Extended ASCII) (Таблица 2) – включала в себя различные варианты латинских символов, применяемые в некоторых языках Западной Европы. Также в ней были другие дополнительные символы, включая псевдографику.

Таблица 2. Расширенный ASCII (Extended ASCII).
Псевдографические символы позволяют, выводя на экран только текстовые символы, обеспечивать некоторое подобие графики.
Русских букв в таблице Extended ASCII не было. В России (ранее – СССР) и в других государствах создавались свои кодировки, позволяющие представлять в 8-битных текстовых файлах специфические “национальные” символы – латинские буквы польского и чешского языков, кириллицу (включая русские буквы) и другие алфавиты.
Во всех кодировках, получивших распространение, первые 127 символов (т.е. значения байта при восьмом бите, равном 0) совпадают с ASCII. Таким образом, файл в формате ASCII работает в любой из этих кодировок; буквы английского языка в них представлены одинаково.
Организация ISO (International Standardization Organization – Международная Организация по Стандартам) приняла группу стандартов ISO 8859. Она определяет 8-битные кодировки для разных групп языков.
Так, ISO 8859-1 – это Extended ASCII, таблица для США и Западной Европы. А ISO 8859-5 – таблица для кириллицы (включая русский язык).
Однако по историческим причинам кодировка ISO 8859-5 не прижилась. Реально для русского языка применяются следующие кодировки:
– Code Page 866 (CP866), она же “ DOS”. Широко применялась до середины 90-х годов; теперь используется ограниченно. Практически не применяется для распространения текстов в Интернете.
– КОИ-8(Код Обмена Информацией-8 бит). Разработана в 70-80-е годы. Является общепринятым стандартом для передачи почтовых сообщений в российском Интернете. Широко применяется также в операционных системах семейства Unix, включая Linux.
Вариант КОИ-8, рассчитанный на русский язык, называется КОИ-8R; существуют версии для иных кириллических языков (так, KOI8-U – вариант для украинского языка).
– Code Page 1251, CP1251, Windows-1251. Разработана компанией Microsoft для поддержки русского языка в системе Windows.
Основным достоинством CP866 было сохранение символов псевдографики на тех же местах, что и в Extended ASCII; поэтому могли без изменений работать зарубежные текстовые программы,. Ныне CP866 используется для программ под Windows, работающих в текстовых окнах или в полноэкранном текстовом режиме.
Тексты в CP866 в последние годы встречаются довольно редко.
Рассмотрим подробнее две другие кодировки – КОИ-8R (Таблица 3) и CP1251 (Таблица 4):

Таблица 3. Кодировка КОИ-8R (символы с 80 по FF):
В таблице кодировки CP1251 русские буквы расположены в алфавитном порядке (за исключением буквы Ё). Благодаря такому расположению компьютерным программам очень просто осуществлять сортировку по алфавиту.
А вот в КОИ-8R порядок русских букв кажется случайным. Но на самом деле это не так.
Во многих старых программах при обработке или передаче текста терялся 8-й бит. Чтобы получить из 8-битного значения 7-битное, достаточно отнять от старшей цифры 8; например, E1 превращается в 61 (E(14)-8=6).
А теперь сравните КОИ-8R с таблицей ASCII (табл.1). Вы обнаружите, что русские буквы поставлены в чёткое соответствие с латинскими. Если исчезнет восьмой бит, строчные русские буквы превращаются в заглавные латинские, а заглавные русские – в строчные латинские. Так, E1 в КОИ-8 – это русское “А”, тогда как 61 в ASCII – латинское “a”.
Итак, КОИ-8 позволяет сохранять читаемость русского текста при потере 8-го бита. “Привет всем” превращается в “pRIWET WSEM”.
В последнее время и алфавитный порядок расположения символов в таблице кодировки, и читаемость при потере 8-го бита потеряли решающее значение. Восьмой бит в современных компьютерах не теряется ни при передаче, ни при обработке. А сортировка по алфавиту производится с учётом кодировки, а не простым сравнением кодов.

Таблица 4. Кодировка CP1251 (символы с 80 по FF):
Из-за того, что распространённых кодировок оказалось две, при работе с Интернетом (почта, просмотр Web-сайтов) иногда можно вместо русского текста увидеть бессмысленный набор букв. Например, “Я СБЮФЕМХЕЛ”. Это всего лишь слова “с уважением”; но они были закодированы в кодировке CP1251, а компьютер декодировал текст по таблице КОИ-8. Если те же слова были, наоборот, закодированы в КОИ-8, а компьютер декодировал текст по таблице CP1251, результатом будет “У ХЧБЦЕОЙЕН”.
Иногда бывает, что компьютер расшифровывает русскоязычные письма и вовсе по таблице, не предназначенной для русского языка. Тогда вместо русских букв появляются бессмысленный набор символов (например, латинские буквы восточно-европейских языков); их часто называют “ крокозябрами ”.
В большинстве случаев современные программы справляются с определением кодировок документов Интернета (электронных писем и Web-страниц) самостоятельно. Но иногда они “дают осечку”, и тогда можно увидеть странные последовательности русских букв или же “крокозябры”. Как правило, чтобы в такой ситуации вывести на экран настоящий текст, достаточно выбрать кодировку вручную в меню программы.
Информацию о расширенном наборе знаков для определенного шрифта можно получить с помощью программы «Таблица символов» в ОС Microsoft Windows. Нажмите кнопку Пуск, а затем последовательно выберите команды Программы, Стандартные, Служебные и Таблица символов.
Расширенный набор знаков ASCII разработан для тех случаев, когда требуются дополнительные знаки. В расширенный набор ASCII включены все 128 знаков, имеющихся в наборе ASCII (знаки 0–32 представлены в одной из следующих таблиц), и добавлены еще 128 знаков — всего 256. Но даже с учетом этих дополнительных знаков алфавиты многих языков не удается охватить при помощи 256 знаков. По этой причине существуют различные варианты кодировки ASCII, включающие знаки для разных языков.
Числа 0–31 в таблице ASCII присвоены управляющим знакам, используемым для управления некоторыми периферийными устройствами, в частности принтерами. Например, число 12 представляет функцию перевода страницы. По этой команде на принтере выполняется переход к верхней части следующей страницы.
Таблица 5. Непечатаемые управляющие знаки ASCII.
| Десятичное число | Знак | Десятичное число | Знак | |
| отсутствие информации | смена канала данных | |||
| начало заголовка | Элемент управления устройством 1 | |||
| начало текста | элемент управления устройством 2 | |||
| конец текста | элемент управления устройством 3 | |||
| конец передачи | Элемент управления устройством 4 | |||
| запрос | отрицательное подтверждение | |||
| подтверждение | SYN | |||
| звуковой сигнал | конец блока передачи | |||
| возврат | отмена | |||
| горизонтальная табуляция | конец носителя | |||
| перевод строки/новая строка | замена | |||
| вертикальная табуляция | Esc | |||
| Перевод страницы/новая страница | разделитель файлов | |||
| возврат каретки | разделитель групп | |||
| сдвиг без сохранения разрядов | разделитель записей | |||
| сдвиг с сохранением разрядов | разделитель сегментов |
Более новая кодировка называется UNICOD (Юникод). Поскольку размеры таблицы Юникод намного больше,то в ней можно представить 65536 знаков в отличие от 128 знаков кодировки ASCII или 256 знаков расширенной кодировки ASCII. Благодаря увеличенной емкости таблицы удается включить в один набор большинство знаков для различных языков.
Язык текстовой разметки HTML.
HTML язык - это основа для начинающего веб-мастера. Этот язык в чистом виде достаточно простой, однако в тоже время он позволяет самостоятельно создавать полноценные страницы и сайты.
Откройте программу блокнот по адресу Windows →Пуск→ Стандартные→ Блокнот и напишите в нем следующий текст:
<html>
<head>
<title>Моя первая страничка </title>
</head> <body> Привет мир!!!
<br>
Меня зовут (здесь впишите Ваше имя), это моя первая страничка! </body>
</html>
Cохраните этот текст как html документ, название придумайте сами.
Далее открываем этот файл при помощи программы браузера Internet Explorerа (правой кнопкой по файлу.. " Открыть с помощью.." →Internet Explorer)
HTML язык по своей сути не является языком программирования. Он является языком разметки гипертекстовых документов,тоесть он отвечает за расположение в документе Ваших текстов, рисунков, таблиц, предназначенных для сети Интернет. Заставить его посчитать невозможно, в нем нет логических функций, зато можно красиво выложить любую информацию.
Читается этот язык при помощи программ, именуемых браузерами (обозревателями), которые "знают" стандартные команды html языка, и выводят их на монитор компьютера в виде документа.
Команды в html называют дескрипторами, но чаще - тегами.
Все, что написано между <…> - называют тегами. Они не видны читателю, заглянувшему на страницу в браузере, зато хорошо видны браузеру, который обнаружив тег <html>, понимает, что далее будет документ, который необходимо прочитать и вывести на монитор в нужном виде.
Тег </html> говорит о том что документ закончился.
Браузер не терпит двусмысленности, поэтому команды ему нужно подавать чёткие и ясные.
Надо помнить следующие вещи:
1) Если есть открывающий тег <…> то обязательно должен быть и закрывающий </…>.
Хотя есть и исключения (например тег <br>- означает, что надописать с новой строки).
2) Все документы должны иметь шаблон кода:
<html>- начало документа
<head>- начало головы
</head>- закрытие головы
<body>- начало тела
</body>- закрытие тела
</html>- конец документа
Данные теги являются обязательными! Писать их необходимо всегда для каждой новой странички, и только в таком порядке!
3) о порядке:
Открывающий и закрывающий тег по типу <…> </…> представляет собой своего рода ёмкость, ящик в который могут складываться другие теги - ящички поменьше.
Чётко структурируйте код странички, иначе ничего работать не будет.
Что можно сделать с текстом в Word, то же можно сделать и с текстом на страничке html.
Параграф -это кусочек текста, одно или несколько предложений, который в книгах печатается с новой строки, выделяя этот текст из основной массы.
Книгу, разбитую на параграфы, легко читать, потому что, одному параграфу соответствует одна мысль или логическая часть текста.
Чтобы на странице сайта разбить текст на параграфы, необходимо воспользоваться тегом <p>.
Параграф имеет атрибут align "выравнивание" который может быть равен значению.
С помощью параграфа можно расположить наш текст по центру:
<p align="center">Привет мир!!!</p>
По левому краю:
<p align="left">Привет мир!!!</p>
По правому краю:
<p align="right">Привет мир!!!</p>
Или же обоим краям документа:
<p align="justify">Привет мир!!! - здесь нужен текст подлинней чтобы эффект был хорошо виден при открытии документа</p>
Требуется помнить следующее:
1) Тег <p> не может содержать в себе других параграфов.
2) Нельзя писать пустые теги без текста или других тегов.
3) По умолчанию текст выравнивается браузером по левому краю, так что атрибут align="left" для параграфа можно не указывать.
4) Тег <p> подразумевает в себе перенос строки, если это Вам не нужно, используйте вместо тега <p> тег <div> данный тег является альтернативой тегу <p>
5) Еще одним способом выравнивания текста по центру является использование тега <center> любое содержание взятое в данный тег выравнивается по центру экрана:
<center>Привет мир!!!</center>
В наборе тегов html языка имеется шесть типов заголовков:
<h1> Привет мир!!! </h1>
<h2> Привет мир!!! </h2>
<h3> Привет мир!!! </h3>
<h4> Привет мир!!! </h4>
<h5> Привет мир!!! </h5>
<h6> Привет мир!!! </h6>
После использования того или иного заголовка происходит перенос строки.
Тег <font> -шрифт имеет атрибут size – размер:
<font size="+2">Привет мир!!!</font>
<font size="+0">Привет мир!!!</font>
<font size="-2">Привет мир!!!</font>
В html языке используется своя палитра красок. Основные цвета выглядят так (Таблица 6):
| #000000 black | #ffffff white | #ff0000 red |
| #ffa500 orange | #ffff00 yellow | #008000 green |
| #00ffff cyan | #0000ff blue | #800080 purple |
Таблица 6. Коды цветов html.
Один и тот же цвет можно задать двумя способами:
используя шестнадцатеричное значение цвета RGB - например #008000 - зелёный цвет, либо используя константы цвета – green.
У тега <font> есть атрибут - color.
<font color="#ff0000">Привет мир!!!</font> - То цвет шрифта станет красным.
Или так:
<font color="red">Привет мир!!!</font>
Тег <body> </body> "тело" - имеет атрибут text - "текст" если присудить этому атрибуту любой цвет из доступной палитры то весь текст в нашей странице окрасится, кроме тех мест, где указан другой цвет.
В строчке, где стоит открывающий тег <body>:
<body text="#ff8c40 ">
Теперь весь текст у нас стал оранжевым кроме заголовка "Привет мир!!!" который мы отдельно перекрасили в красный.
А вот атрибут тега <body> bgcolor и его значение задает цвет фона страницы
<body bgcolor="#40caff"> - залили всё голубым..
Если в теге присутствует два и более атрибута пишем их подряд через пробел, не разделяя никакими другими знаками.
Стиль текста:
| <b> </b> | - Полужирный текст |
| <i> </i> | - Наклонный текст |
| <u> </u> | - Подчеркнутый текст |
| <strike> </strike> | - Перечеркнутый |
| <s> </s> | - Перечеркнутый (второй вариант, от первого ничем не отличается) |
| <tt> </tt> | - моноширинный шрифт |
| <small> </small> | - Малый |
| <big> </big> | - Большой |
| <sup> </sup> | - Верхний индекс |
| <sub> </sub> | - Нижний индекс |
Текст заключённый между этими открывающими и закрывающими тегами приобретёт нужный нам стиль.
Для того чтобы изменить шрифт документа необходимо дать указание браузеру показывать текст таким шрифтом. Для этого используем тег <font> и его атрибут face:
<font face="arial">эта строчка будет написана с помощью шрифта Arial</font>
Браузер использует библиотеку шрифтов, установленную на компьютере пользователя, и если вдруг указанного шрифта в этой библиотеке не окажется, то он заменит его на тот, который присутствует.
В браузерах текст набранный с помощью текстовых редакторов проходит "обработку" перед выводом его на экран компьютера. Так в набранном тексте удаляются все переносы строк и лишние пробелы, пробелов между словами или просто символами может быть не более одного.
Проводится данная "обработка", для того чтобы на мониторах с разным расширением экрана текст переносился на следующую строку в тех местах, где это действительно необходимо, а не там где были раннее расставлены пробелы и переносы строк.
Однако такая политика браузеров, в ряде случаев, не всегда оправдана.
Поэтому используем тег <pre>, текст заключённый в данный тег выводится браузерами на экран в том виде в котором он был набран, т.е. со всеми пробелами и переносами строк.
Если необходимо вставить фотографию, для того чтобы вставить её в нашу страничку к ней нужно указать путь:
<img src="foto.jpg">
Где foto.jpg это название фотографии в данном случае, так как фото лежит рядом с html документом, путь к ней мы не указываем.
Тег <img> не требует закрывающего тега!
<img src="myfoto/foto.jpg"> -запись подразумевает, что в директории где расположен наш html документ есть папка myfoto в которой расположен файл foto.jpg
Как и другие теги <img> тоже имеет свои атрибуты.
Атрибут align "выравнивание " применим и к данному тегу
<img src="foto.jpg" align="left"> - фото слева от текста
<img src="foto.jpg" align="right"> - фото справа от текста
<img src="foto.jpg" align="top"> - текст выше фото
<img src="foto.jpg" align="bottom"> - текст ниже фото
<img src="foto.jpg" align="middle"> - текст посередине
Пиксель -это элементарная неделимая единица изображения. Каждый пиксель имеет свои координаты, например, самый верхний левый пиксель на мониторе имеет координаты x=1, y=1, а самый нижний правый в зависимости от разрешения монитора.
x=800, y=600 - будет при разрешении 800 на 600 точек. Все расстояния в графических изображениях измеряются пикселями.
<img src="foto.jpg" vspace="15"> - Атрибут vspace задаёт расстояние по вертикали от рисунка до текста в 15 пикселей
<img src="foto.jpg" hspace="25"> - Расстояние по горизонтали соответственно
<img src="foto.jpg" width="180"> - Ширина непосредственно самого изображения
<img src="foto.jpg" height="240"> - Высота изображения. Если атрибуты width и height не использовать, то ширина и высота изображения по умолчанию будет равна реальным её размерам, без каких либо искажений.
<img src="foto.jpg" border="5"> - Бордюр, рамка вокруг изображения и её толщина в пикселях.
<img src="foto.jpg" border="5" bordercolor="#008000 "> - bordercolor - это цвет рамки.
<img src="foto.jpg" alt="Это мое фото!!!"> -Атрибут alt - это описание изображения. Если навести курсор на наше фото и подержать его там несколько секунд, выскочит надпись -Это мое фото!!!
<img src="foto.jpg" title="Это мое фото!!!"> - альтернатива alt в данном случае.
Изображение можно сделать фоном страницы. Для этого используем атрибут background "фон" открывающего тега <body>: <body background="foto.jpg">
Чтобы разместить фотографию в нужном месте страницы теги применимы к выравниванию изображени такие же, как и к тексту.
В сайт можно вставить таблицы.
Тег <table> задаёт начало и конец таблицы, любая таблица, как известно, состоит из строк и столбцов, для этого есть ещё два тега:
<tr> - строка таблицы
<td> - столбец таблицы
Вместе эти теги пишутся так:
<table>
<tr>
<td>ячейка</td>
</tr>
</table>
Такая запись- это самая маленькая таблица, в ней всего одна строка, содержащая один столбец – ячейку.
Часто при работе с таблицами возникает необходимость объединить те или иные ячейки в одну.
Эту задачу решают атрибуты colspan и rowspan.
colspan - определяет какое количество столбцов будет занимать данная ячейка
rowspan - количество рядов занимаемое ячейкой
Размеры таблицы и ячеек по умолчанию ограничены вставленным в неё текстом.. и изменяются случайным образом. Применяем атрибуты width - ширина и height - высота, которые использовались для растягивания рисунков, они так же применимы к тегам <table>, <tr> и <td>.
Значения атрибутов width и height в таблице могут указываться не только в пикселях, но и в процентах.
Любая ячейка таблицы может служить самостоятельной ёмкостью для наполнения другими тегами и текстовым содержанием, а также иметь те или иные индивидуальные свойства - атрибуты.
Выровняем текст новым атрибутом valign - Вертикальное выравнивание. До этого момента нам был знаком атрибут align - горизонтальное выравнивание.
Cellspacing - задаёт расстояние в пикселях между ячейками таблицы. Задав значение cellspacing="0" можно избавиться от "зазора" между ячейками.
Атрибут cellpadding - в пикселях задаёт поля ячеек (отступ от границ ячеек до текста).
При создании больших сложных таблиц рекомендуют сначала рисовать их на бумаге. Так будет удобнее представить её общую картину, подсчитать количество строк и столбцов, увидеть с какой ячейки и на какое количество следует растягивать "объединять" те или иные ячейки.
При выборе будущих размеров Вашей страницы, особенно это касается её ширины (атрибут width), ориентируйтесь на стандартные разрешения мониторов 640 на 480, 800 на 600, 1024 на 768 и т.д.
Существует несколько видов ссылок, а так же "механизмов" перехода по ним.
Чтобы браузер не завис, ему необходимо знать: точное название документа, путь к документу, и место, где его открыть.
Текстовые ссылки - тег <a> (от anchor- якорь), в него можно заключить текст или рисунок, которые станут ссылкой на те или иные документы. Атрибут тега <a> href задаёт имя и путь к документу на который указывает ссылка:
<a href="primer.html">Здесь мое фото!!</a>
По аналогии с рисунками тег <img> путь ссылки к открываемому документу прописывается теми же способами.
Ссылки выделяются цветом, по умолчанию синим - ссылка, а красным - уже посещенная ссылка, эти цвета можно изменить с помощью открывающего
тега < body > и его атрибутов.
link - цвет ссылки.
alink - цвет нажатой, активной ссылки.
vlink - цвет посещенной ссылки:
<body link="#008000" alink="# ff0000 " vlink="# ffff00">
При необходимости можно принудительно выделять цветом как всю ссылку, так и отдельные её части (фразы слова буквы) знакомым тегом <font> </font> и его атрибутом color.
Манипуляции с цветом нужно проводить внутри тега <a>вот здесь</a> а не за бортом, иначе цвет ссылки будет либо по умолчанию, либо так как прописано в теге <body>
Ссылкой может являться не только текст, но и рисунок.. Здесь принцип такой же как и в текстовой ссылке, просто вместо текста заключаем рисунок который хотим сделать ссылкой:
<a href="primer3.html"><img src="knopa.gif"></a>
Если при переходе по ссылке надо открыть документ в новом окне браузера (он открывался в текущем), то надо применить атрибут target (цель) и его значение _blank:
<a href="primer3.html" target="_blank">открыть в новом окне</a>
Разные браузеры не всегда воспринимают те или иные теги и их атрибуты.
Для того что бы сделать текст или рисунок ссылкой на e-mail - почтовый ящик его нужно заключить в тег <a>, но не простой, а с использованием mailto:
<a href="mailto:nick@mail.ru"> Напишите мне письмо.. </a>
Эта непривычная запись будет говорить что, кликнув по тексту ссылке "Напишите мне письмо.." посетитель сайта попадет в свою почтовую программу, которая выдаст ему бланк для отправки письма, где в строчке Кому: уже будет указан нужный нам почтовый ящик nick@mail.ru
Закладки или якоря - это особый вид ссылок. Данные ссылки, как правило, не ведут к какому либо документу, а предназначены для навигации внутри страницы.
Предположим на странице в удобном месте находится некое содержание или меню.. по принципу:
Глава1
Глава2
Глава3
А далее идет большой текст с этими главами, так вот чтобы посетитель страницы нажав на одну из этих глав "перенёсся" в нужное место текста нам нужно сделать две вещи:
Присвоить индивидуальное имя каждой главе. Ищем, значит, в большом-большом тексте нужные главы и делаем их адресами ссылок закладок, присваиваем им имена.:
<а name="glava1">Глава1 </а>
<а name="glava2">Глава2 </а>
<а name="glava3">Глава3 </а>
Имя можно присвоить любое необязательно glava1
А потом прописываем на них ссылки в меню, содержании:
<a href="#glava1"> Глава1</a>
<a href="#glava2"> Глава3</a>
<a href="#glava3"> Глава3</a>
Перед каждым именем ставим знак решётки #.
Одна из страничек на сайте обязательно должна называться index.html. Именно файл с таким названием на сайте будет искать программа робот, когда человек введет имя сайта. Так как страница index.html будет открываться первой, делайте её главной. Остальные страницы можете называть, как угодно.
Прописывая путь и имена документов помните, что, к примеру: Page.html, page.html и PAGE.html это имена разных документов! Это же касается имен закладок и рисунков. Всегда учитывайте регистр при написании кода, есть большая вероятность, что такие имена не будут распознаны тем или иным браузером. Возьмите за правило все писать и обзывать маленькими латинскими буквами, тогда риск человеческого фактора и капризов программ сведется к нулю.
Иногда в тексте не обойтись без знаков -спецсимволов.
Так например спецсимвол < - будет значить что в этом месте текста нужно поставить знак < а спецсимвол > обозначит символ >.
Все спецсимволы начинают писаться со знака & - амперсант этот знак указывает браузеру, что далее будет идти имя спецсимвола и воспринимать его следует не как текст, а как команду.
Для знака & тоже есть свой спецсимвол - &
Такая вот путаница получается..
Спецсимвол - это неразрывный пробел. Дело в том, что когда Вы пишите текст в блокноте или html редакторе "простых" пробелов между словами можно поставить сколь угодно много, но вот при чтении страницы браузером все они "удаляются" и между словами на странице будет не более одного пробела. Отсюда часто возникают проблемы с оформлением текста, красную строку, например, никак не сделать... вот и придумали люди спецсимвол он воспринимается браузером не как пробел, а как знак, только невидимый человеческому глазу.
А неразрывным он называется по тому, что группа таких пробелов воспринимается как цельное слово, следовательно, не переносится на следующую строку, если предложение подходит к установленным рамкам или же к краю окна. Так что в окне может появиться горизонтальная полоса прокрутки, если Вам это ненужно, ставьте между ними обыкновенные пробелы
Пример в примере… навивает на философские мысли о бесконечности…
Если перед Вами встанет задача нарисовать ячейку таблицы без какого либо содержания, вставляйте в неё знак пробела .
Помните правило <тег>здесь что то обязательно должно быть</тег>? Спецсимвол пробела один из выходов в данном случае.
Кроме выше указанных есть еще целый ряд спецсимволов: знаки зодиака, карточные масти, палочки, точечки, ёлочки, кругляшки, дроби..
Простой новый тег <hr> рисует в окне горизонтальную линию, не требует закрывающего тега. Часто применяется при верстке страницы в качестве декоративного элемента.
Имеет ряд атрибутов, align -выравнивание с одним из трёх значений (center, left, right) может быть применен, если задана длина линии атрибут width в пикселях или процентах. Так же можно задать толщину линии атрибут - size, цвет атрибут - color, и при необходимости отключить тень линии noshade.
Тег <marquee> заставляет текст помещённый в него двигаться в том или ином направлении, проще говоря делает его бегущей строкой. Бегущая строка имеет ряд настроек скроллинга, которые задаются следующими атрибутами:
behavior - определяет тип скроллинга, может иметь следующие значения:
alternate - колебательные движения от края к краю
scroll - прокручивание текста. текст будет выходить за рамки экрана и снова появляться с противоположной его стороны
slide - прокручивание текста c остановкой.
scrollamount - скорость бегущей строки от 1 до 10.
loop задает количество прокруток бегущей строки.
direction - направление движения текста. значения:
up - вверх, down - вниз, left - влево, right - вправо.
bgcolor - цвет фона бегущей строки,
height - высота строки, width - ширина строки:
<html>
<head>
<title>Бегущая строка</title>
</head>
<body>
<div align="center"><h2>Бегающие строки</h2></div>
<marquee>Бегущая строка по умолчанию</marquee>
<marquee direction="right">Бегущая строка слева направо</marquee>
<marquee behavior="alternate">Бегущая строка бегает от края к краю</marquee>
<marquee scrollamount="10">Бегущая строка со скоростью 10</marquee>
<marquee scrollamount="1">Бегущая строка со скоростью 1</marquee>
<marquee direction="right" loop="2">Эта строка будет прокручиваться только два раза</marquee>
<marquee behavior="slide">Бегущая строка с остановкой</marquee>
<marquee bgcolor="#b40000">Бегущая строка с фоном</marquee>
<marquee width=400>Бегущая строка с ограничением ширены прокрутки</marquee>
<marquee direction="up">Бегущая строка снизу вверх</marquee>
<marquee hspace="300">Бегущая строка с отступами от границ</marquee>
</body>
</html>
Комментарии используются для того, чтобы облегчить свой собственный труд, а так же упростить понимание другим человеком кода странички. Пишутся они непосредственно в коде html документа, однако браузер не выводит эти "пометки" на экран. Для того чтобы заставить браузер игнорировать какой либо текст его необходимо заключить вот в такой набор символов:
<!-- -->
По принципу:
<!-- здесь может быть любой текст -->
Неупорядоченный список задаётся тегом <ul>. Любой список состоит из элементов, "пунктов", каждый элемент в свою очередь задаётся тегом <li> после которого собственно и идёт текст нужного нам "пункта". Для тега <li> закрывающий тег </li> необязателен.
Вместе данные теги приобретают следующий вид:
<ul>
<li> Пункт первый..
<li> Пункт второй..
<li> Пункт третий..
</ul>
Теги <li> и <ul> имеют атрибут type который присуждает элементу списка или же всему списку целиком определённый стиль.
Может иметь одно и трёх значений:
disk - кружок, диск (по умолчанию)
circle - полый круг
square - квадрат
Упорядоченный или нумерованный список задаётся тегом <ol>, так же как и в неупорядоченном списке, элемент списка присуждается тегом <li>.
Построение кода полностью схоже с неупорядоченным списком.
Атрибут type в сочетании с упорядоченным списком может иметь следующие значения:
А - Заглавные буквы
а - Строчные буквы
I - Заглавные римские цифры
i - Строчные римские цифры
1 - Арабские цифры (по умолчанию)
В упорядоченном списке есть атрибут start его числовое значение говорит о том, с какого номера следует строить упорядоченный список.
Список определений задаётся тегом <dl>. Пункты списка определений размечаются тегом <dt>, а определения этих пунктов тегом <dd>.
Всё вместе пишется по следующей схеме:
<dl>
<dt>
<dd>
</dl>
Пример:
<html>
<head>
<title>Список определений</title>
</head>
<body>
<dl>
<dt> Слово коса может иметь следующие определения:
<dd> сельскохозяйственный инструмент
<dd> хитрая девичья причёска
<dd> отмель реки
<dt> Слово ключ тоже имеет несколько значений:
<dd> гаечный
<dd> источник, родник
</dl>
</body>
</html>
Между тегами <body> </body> указывается информация предназначенная для вывода на экран в нужном нам виде, а между тегами <head> </head> исключительно служебная информация предназначенная для поисковых систем и браузеров тех или иных пользователей.
С тегом <title> указываем имя документа в заголовке страницы.
Тег <meta> (закрывающего тега не требует) указывает служебную информацию на нашей страничке.
<meta> имеет следующие атрибуты:
http-equiv - указывает браузеру как следует обработать основное содержание документа, точнее на основе каких данных.
name - информационное имя. (применяется в паре с атрибутом content)
content - информационное содержание, связанное с мета именем (name)
Пример (очень нужный и важный):
<meta http-equiv="Content-Type" Content="text/html; Charset=Windows-1251">
Данная запись указывает браузеру кодировку, в которой была написана данная страница - формат документа и раскладку клавиатуры, в данном случае это кириллица для Windows. Если эту строку не писать в заголовке страницы, то есть большая вероятность что весь текст на Вашей странице отобразится в виде непонятных человеку "иероглифов" у разных пользователей тех или иных браузеров. Конечно, пользователь может применить к такому документу команду в браузере Вид->Кодировка->Кириллица, но он может не знать о данной функции, да и зачем утруждать человека данным действием.
<meta http-equiv="Content-Type" - указываем, что в этом мета теге мы будем заниматься Content-Type - типом содержания
Content="text/html; - а именно его текстом
Charset=Windows-1251"> - документ для Windows - Кириллица, где 1251 кодировка раскладки клавиатуры, так например Английская клавиатура будет задаваться Charset=Windows-1252
В настоящее время рекомендуют использовать кодировку UTF 8
То есть писать в голове документа так:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
Пример:
<meta http-equiv="Content-Language" Content="ru">
В этой строчке говорится о том, что язык Language документа является русским Content="ru"
Неправильная установка языка и раскладки клавиатуры может привести к печальным последствиям.
Данные метаописатели предназначены для заявления об авторских правах непосредственно в заголовке html кода, так name="author" указывает имя автора страницы, а name="copyright" авторское право (копирайт) в котором может указываться фамилия, имя, отчество автора сайта, название фирмы, бренда.. и т. д.
Язык разметки гипертекстовых документов, точно также как и русский язык живёт во времени и тоже меняется.. появляются новые слова - теги например <footer>, <header>, <video>.., какие-то наоборот умирают, забывается и осуждаются в использовании, например теги: <center>, <font>, <frameset>.., тоже самое происходит с атрибутами, меняются правила синтаксиса..
Так вот чтобы различные браузеры отобразили документ правильно, не запутались в чтении Вашей страницы, необходимо указать в соответствии с какими стандартами он был написан.
Разработкой стандартов HTML языка (и не только HTML), иначе спецификаций, занимается организация World Wide Web Consortium, W3C - Консорциум Всемирной паутины, официальный сайт: (www.w3.org). Эта организация разработала несколько спецификаций HTML.
Именно этими документами должны руководствоваться как веб-мастера при создании сайтов, так и разработчики браузеров
Заголовок <!DOCTYPE> указывает на тип документа - DTD (document type definition - описание типа документа) для правильной его интерпретации браузерами, другими словами указывал браузерам, согласно каким стандартам следует обрабатывать ту или иную страницу.
Ниже перечислены основные варианты <!DOCTYPE>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
- Строгий DTD. Используя такой заголовок, веб-страница должна в точности следовать спецификации HTML 4.01 не использовать теги и атрибуты, обозначенные спецификацией как "нежелательные", а также не должна использовать фреймы.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
- Переходный синтаксис HTML. При таком заголовке допускаются "вольности" при составлении документа, страница может содержать теги и атрибуты, помеченные спецификацией HTML 4.01 как "нежелательные".
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Frameset//EN" "http://www.w3.org/TR/html4/frameset.dtd">
- Указывает, что в HTML-документе используются фреймы.
<!DOCTYPE html>
- А такой заголовок обозначает, что используется спецификация HTML 5.
Заголовок <!DOCTYPE> принято располагать в самом начале документа перед тегом <html>

