 2014-01-31
2014-01-31 772
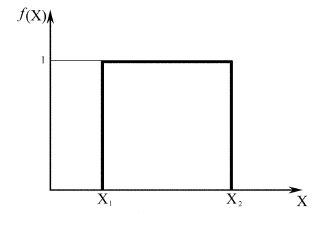
772Рис. 2.3. Равномерное (равновероятное) распределение
Рис. 2.1. Интегральный и дифференциальный законы распределения
Одно из нарушений нормального закона распределения погрешностей при соблюдении аксиом состоит в появлении плосковершинности и островершинности, как показано на рис. 2.2.
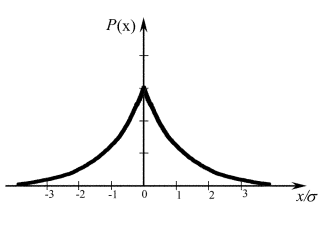
Рис. 2.2. Островершинное распределение
В пределе для плосковершинного распределения, когда уже аксиома не соблюдается, оно превращается в равномерное.
Нарушение аксиомы распределения может привести к тому, что малые погрешности встречаются реже, чем большие. В этом случае середина кривой распределения плотности вероятностей оказывается прогнутой вниз и распределение становится "двугорбым" - так называемым двухмодальным.
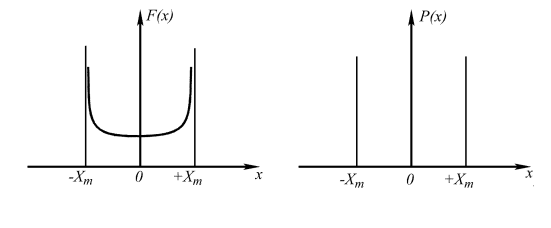
Рис. 2.4. Двухмодальное распределение
Модой дискретной случайной величины называют ее наиболее вероятное значение, а для непрерывной случайной величины модой является то значение, при котором плотность вероятности достигает максимума. В пределе такое двухмодальное распределение может превратиться в распределение, когда единственно наблюдаемыми погрешностями будут только погрешности ±XmaX (см. рис. 2.4). Например, погрешность от люфта в кинетической цепи, погрешность от гистерезиса имеют вид двухзначной дискретной погрешности.
5.3.1. Числовые характеристики законов распределения
Статистическое описание случайной величины полным указанием законов распределения слишком громоздка. На практике достаточно указать только отдельные числовые характеристики закона распределения случайной величины. Для оценки того или иного свойства законов распределения случайной величины в теории вероятностей используют числовые характеристики, называемые моментами.
Прежде всего нас интересует положение случайной величины на числовой оси, т.е. ее систематическая составляющая - ее среднее значение, определяющее положение области, в которой группируется значения случайной величины.
Такое среднее значение случайной величины называется ее первым моментом или ее математическим ожиданием.
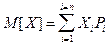 , (2.4)
, (2.4)
т.е. определяется как сумма произведений всех возможных значений дискретной случайной величины Х на вероятность этих значений Р.
Для непрерывной случайной величины выражение для математического ожидания можно записать
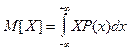 , (2.5)
, (2.5)
где ×P(X) - плотность распределения вероятностей случайной величины Х.
В отличие от среднего арифметического значения, которое само является случайной величиной, т.к. зависит от испытаний, математическое ожидание является числом, которое связано только с законом распределения случайной величины.
Начальный момент s-го порядка дискретной случайной величины запишется:
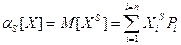
Для непрерывной случайной величины:
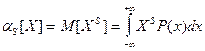
Иначе, математическое ожидание - это начальный момент первого порядка. Случайная погрешность (случайное отклонение) определяется зависимостью:
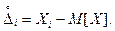
Центральным моментом S-го порядка случайной величины называется математическое ожидание S степени соответствующей центрированной величины.
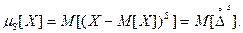
Из определения следует, что m1 = 0, т.е. математическое ожидание первой степени центрированной случайной величины всегда = 0.
Второй центральный момент называется дисперсией случайной величины и характеризуется рассеяние значений случайной величины вокруг математического ожидания.
m2[X] = D[X] = M[(X - M[X])2],
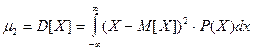
Так как дисперсия имеет разность квадрата случайной величины, то она выражает как бы мощность ее рассеяния. Для наглядной характеристики самой величины рассеяния пользуются среднеквадратическим отклонением случайной величины Х, которое равно 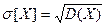 и имеет размерность самой случайной величины.
и имеет размерность самой случайной величины.
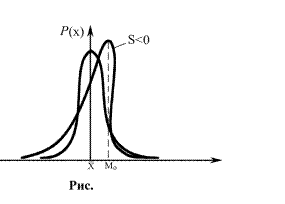
Третий центральный момент характеризует асимметрию, или скошенность (рис. 2.5.) распределения (медиана распределения). Для всех симметричных относительно математического ожидания законов распределения этот момент равен нулю.
|
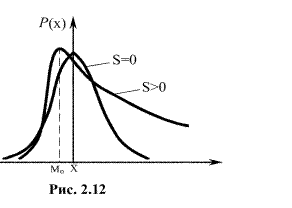
Рис. 2.5. Иллюстрация «скошенности» закона распределения
Медианой непрерывной случайной величины называется такое значение Х, что в этой точке функция распределения F(X) случайной величины Х равна ½.
Для относительной характеристики асимметрии обычно пользуются коэффициентом асимметрии: S = m3/s3
Четвертый центральный момент служит для описания островершинности или плосковершинности распределения (мода). Мода - для дискретной случайной величины - наиболее вероятное значение случайной величины. Мода - для непрерывной - точка максимума плотности распределения ее вероятностей.
Эти свойства описываются с помощью относительного значения четвертого момента, равного m4/s4, или так называемого эксцесса, который находится как:
Ex = m4/s4 -3
Для нормального закона распределения величина m4/s4 =3, Ex = 0, остальные распределения сравниваются с нормальными, поэтому вычитается тройка. Для нормального закона Ех = 0. Кривые более островершинные по сравнению с нормальным законом, обладают положительным эксцессом, а плосковершинные кривые - отрицательным эксцессом. Точкой перегиба кривой имеют абсциссы
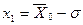 , .
, .
Асимметрия, вычисленная по формуле S = m3/s3 = 0. Этот результат характеризует симметричную форму кривой относительно среднего значения Хо, совпадающее с модой Мо и Мс. Эксцесс найденный по формуле Ex= m4/s4-3 = 0.
Функция нормального распределения определяется интегралом
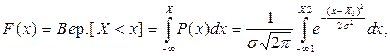
Вероятность нахождения случайной величины Х между X1 и X2 определяется разностью соответствующих значений функции распределения
Вер.[X1 < X < X2 ] = F(X2) - F (X1) = 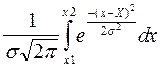 .
.
Графически эта вероятность представлена площадью под кривой, изображающей плотность вероятности между ординатами, соответствующими абсциссам X1 и X2.
Если X1 = - ¥, а X2 = + ¥, то вероятность, определенная по этой формуле обратится в 1 и выразит всю площадь под кривой.
Для облегчения пользования функцией нормального распределения применяют нормированную функцию Лапласа, называемую также интегралом вероятностей
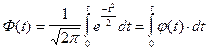 .
.
Тогда формула запишется
Вер [a1 < X < a2] = Ф (t2) - Ф (t1) = 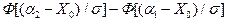
Точность измерения величины x будут определять границы, внутри которых может находится действительное число Х, т.е.
Xo - a < X < Xo + a,
Где Xo - результат измерения, a - границы интервала
Вероятность того, что действительное значение измеряемой величины Х лежит внутри доверительного интервала (Xo - a, Xo + a) называется надежностью b при заданной точности. При уменьшении доверительного интервала до величины a < 2s, надежность результата резко падает. Величину a = 3s, имеющую надежность 99,73%, (доверительная вероятность 0,997) называют предельной погрешностью.
Оценка результатов измерений. Результат всякого измерения содержит в себе случайную погрешность. Поэтому при всех точных измерениях необходимо не только указывать полученный результат, но и делать оценку качества данного измерения, степени достоверности результата или, как говорят, указывать точность измерения.
При оценке точности надо указать границы интервала (доверительного интервала) в который с определенной вероятностью, (доверительной вероятностью) находится результат измерения.
5.3.2. Точечные оценки числовых характеристик результатов измерений
Основными точечными характеристиками погрешностей измерений являются математическое ожидание и дисперсия (или среднее квадратическое отклонение).
Математическое ожидание погрешности измерений М(Х) есть неслучайная величина, относительно которой рассеиваются другие значения погрешностей при повторных измерениях. Как числовая характеристика погрешности М (Х) показывает на смещенность результатов измерения относительно истинного значения измеряемой величины.
+ ¥
М (Х) = ò х j (х) d (х),
- ¥
где j (х) - плотность распределения вероятности погрешности х.
Дисперсия погрешности D (Х) характеризует степень рассеивания (разброса) отдельных значений погрешности относительно математического ожидания.
+ ¥
D (Х) = ò [х - М (Х)]2 j (х) d (х).
- ¥
Чем меньше дисперсия, тем меньше разброс, тем точнее выполнены измерения. Следовательно, дисперсия может служить характеристикой точности проведенных измерений. Однако дисперсия выражается в единицах погрешности в квадрате. Поэтому в качестве числовой характеристики точности измерений используют среднее квадратическое отклонение
s (Х) = Ö D (Х).
Оценку параметра назовем точечной, если она выражается одним числом. Любая точечная оценка, вычисленная на основании опытных данных, является их функцией и поэтому сама должна представлять собой случайную величину с распределением, зависящим от распределения исходной случайной величины, от самого оцениваемого параметра и от числа опытов n.
К точечным оценкам предъявляется ряд требований, определяющих их пригодность для описания самих параметров.
1. Оценка называется состоятельной, если при увеличении числа наблюдений она приближается (сходится по вероятности) к значению оцениваемого параметра.
2. Оценка называется несмещенной, если ее математическое ожидание равно оцениваемому параметру.
3. Оценка называется эффективной, если ее дисперсия меньше дисперсии любой другой оценки данного параметра.
На практике не всегда удается удовлетворить одновременно все эти требования, однако выбору оценки должен предшествовать ее критический анализ со всех перечисленных выше точек зрения.
Существует несколько методов определения оценок. Наиболее распространен метод максимального правдоподобия, теоретически обоснованный математиком Р.Фишером. Идея метода заключается в следующем. Вся получаемая в результате многократных наблюдений информация об истинном значении измеряемой величины и рассеивании результатов сосредоточена в ряде наблюдений Х1, Х2,..., Хn, где n - число наблюдений. Их можно рассматривать как n независимых случайных величин с одной и той же дифференциальной функцией распределения rх (х; Q; sх). Вероятность Рi получения в эксперименте некоторого результата Хi, лежащего в интервале хi ± Dх, где Dх - некоторая малая величина, равная соответствующему элементу вероятности Рi = rх (хi; Q; sх) Dх.
Независимость результатов наблюдений позволяет найти априорную вероятность появления одновременно всех экспериментальных данных, т. е. всего ряда наблюдений Х1, Х2,..., Хn как произведение этих вероятностей
n n
Р (Х1, Х2,..., Хn) = Õ Рi = Dхп Õ rх (хi; Q; sх).
i = 1 i = 1
Если рассматривать Q и sх как неизвестные параметры распределения, то, подставляя различные значения Q и sх в эту формулу, мы будем получать различные значения вероятности Р (Х1, Х2,..., Хn) при каждом фиксированном ряде наблюдений Х1, Х2,..., Хn. При некоторых значениях Q = Q (Х1, Х2,..., Хn) и sх = sх (Х1, Х2,..., Хn) вероятность Р (Х1, Х2,.., Хn) получения экспериментальных данных достигает наибольшего значения. В соответствии с методом максимального правдоподобия именно эти значения и принимаются в качестве точечных оценок истинного значения и среднего квадратического отклонения результатов наблюдений.
Таким образом, метод максимального правдоподобия сводится к отысканию таких оценок Q и sх, при которых функция правдоподобия
n
g (Х1, Х2,..., Хn; Q; sх) = Õ rх (хi; Q; sх)
i = 1
достигает наибольшего значения. Постоянный сомножитель Dхп не оказывает влияния на решение и поэтому может быть отброшен. Полученные оценки Q и sх истинного значения и среднего квадратического отклонения называются оценками максимального правдоподобия.
Наряду с методом максимального правдоподобия при определении точечных оценок широко используется метод наименьших квадратов. В соответствии с этим методом среди некоторого класса оценок выбирают ту, которая обладает наименьшей дисперсией, т. е. наиболее эффективную оценку.
5.3.3. Интервальные оценки параметров распределения
Смысл оценки параметров с помощью интервалов заключается в нахождении интервала, за границы которого погрешность не выйдет с некоторой вероятностью. Этот интервал называют доверительным интервалом, характеризующую его вероятность - доверительной вероятностью, а границы этого интервала доверительными значениями погрешности.
В практике измерений применяют различные значения доверительной вероятности, например: 0,90; 0,95; 0,98; 0,99; 0,9973 и 0,999. Доверительный интервал и доверительную вероятность выбирают в зависимости от конкретных условий измерений. Так, например, при нормальном законе распределения случайных погрешностей со средним квадратическим отклонением s (Х) часть пользуются доверительным интервалом от +3 s (Х) до -3 s (Х), для которого доверительная вероятность равна 0,9973. Такая доверительная вероятность означает, что в среднем из 370 случайных погрешностей только одна погрешность по абсолютному значению будет больше 3 s (Х). Так как на практике число отдельных измерений редко превышает несколько десятков, появление даже одной случайной погрешности, большей, чем 3 s (Х), маловероятное событие, наличие же двух подобных погрешностей почти невозможно. Это позволяет с достаточным основанием утверждать, что все возможные случайные погрешности измерения, распределенные по нормальному закону, практически не превышают по абсолютному значению 3 s (Х) (правило «трех сигм»).
В общем случае доверительный интервал может быть установлен, если известен вид закона распределения погрешности и основные числовые характеристики этого закона.
5.3.4. Обнаружение грубых погрешностей
Для устранения грубых погрешностей желательно еще перед измерениями определить значение искомой величины приближенно, с тем чтобы в дальнейшем можно было сконцентрировать внимание лишь на уточнении предварительных данных. Если оператор в процессе измерений обнаруживает, что результат одного из наблюдений резко отличается от других, и находит причины этого, то он, конечно, вправе отбросить этот результат и провести повторные измерения. Но необдуманное отбрасывание резко отличающихся от других результатов может привести к существенному искажению характеристик рассеивания ряда измерений, поэтому повторные измерения лучше проводить не взамен сомнительным, а в дополнение к ним.
Наиболее часто для обнаружения промаха используют так называемый критерий Райта. Согласно этому критерию, если случайное отклонение какого-либо измерения от среденго арифметического значения превышает 3 s (Х), то есть основание считать, что данное измерение содержит промах. Критерий Райта в таком виде целесообразно применять при не очень большом числе измерений (s £ n £ 20). Если же число измерений 20 < n £ 100, то рекомендуется вместо значения 3 s (Х) использовать значение 4 s (Х).
Более обоснованная, хотя и более громоздкая процедура исключения грубых погрешностей базируется на одном из разделов математической статистики - статистической проверке гипотез.
Проверяемая гипотеза состоит в утверждении, что результат наблюдения Хi не содержит грубой погрешности, т. е. является одним из значений случайной величины Х с законом распределения Fх (х), статистические оценки параметров которого предварительно определены. Сомнительным может быть в первую очередь лишь наибольший Х max или наименьший Х min из результатов наблюдений. Поэтому для проверки гипотезы следует воспользоваться распределениями величин
n = (Х max - Х) / Sx или n = (Х - Х min) / Sx.
Функции их распределения определяются методами теории вероятностей. Они совпадают между собой и для нормального распределения результатов наблюдений протабулированы и представлены в таблицах. По данным таблиц, при заданной доверительной вероятности a или уровне значимости q = 1 - a можно для чисел измерения n = 3 - 25 найти те наибольшие значения na, которые случайная величина n может еще принять по чисто случайным причинам.
Если вычисленное по опытным данным значение n окажется меньше na, то гипотеза принимается; в противном случае ее следует отвергнуть как противоречащую данным наблюдений. Тогда результат Х max или соответственно Х min приходится рассматривать как содержащий грубую погрешность и не принимать его во внимание при дальнейшей обработке результатов наблюдений.
5.3.5. Математическая обработка результатов прямых измерений
Предположим, что истинное значение измеряемой величины равно а и выполнено n аналогичных измерений, результаты которых равны х1, х2,..., хn. Каждый из результатов хi, подлежащих совместной обработке для получения результата измерения, называют
результатом наблюдения. Результатом измерения является оценка а значения измеряемой величины, вычисленная на основании всей совокупности результатов наблюдений х1, х2,..., хn. Разность Di = хi - а есть погрешность i-го наблюдения. Относительно этой погрешности сделаем следующие допущения:
- погрешность Di является случайной величиной с нормальным законом распределения;
- математическое ожидание погрешности М [ Di ] = 0, т.е. отсутствует систематическая погрешность;
- погрешность Di имеет дисперсию s2, одинаковую для всех измерений, т.е. измерения равноточные;
- погрешности отдельных наблюдений независимы.
Допущение о нормальности закона распределения погрешности основано на том, что случайная погрешность обычно вызывается целым рядом различных причин, а следовательно, какие бы законы распределения ни имели отдельные ее составляющие, при одинаковом порядке их малости закон распределения результирующей погрешности будет близок к нормальному.
Тогда плотность распределения любого результата хi запишется в виде
f = (хi, a) = e - (xi - a)^2 / 2 s^2 / Ö 2 p s.
Так как результаты отдельных наблюдений независимы, то плотность распределения системы случайных величин х1, х2,..., хn
n
f (х1, х2,..., хn, а) = Õf (хi, a).
i = 1
Плотность распределения системы случайных величин и представляет собой функцию правдоподобия, которую обозначим
n é n ù
L = (х1, х2,..., хn, а) = Õf (хi, a) = (2p) -n/2 s-n exp ê- (1/ 2s2 ) å (хi - a)2 ê. (2.6)
i = 1 ë i = 1 û
Использовав метод максимального правдоподобия, найдем оценку а таким образом, чтобы при а = а достигалось
L (х1, х2,..., хn, а) = max. (2.7)
n
å (хi - a)2 = min. (2.8)
i = 1
Условие (2.8) является формулировкой критерия наименьших квадратов. Отсюда следует, что при нормальном законе распределения случайной величины оценки по методам максимального правдоподобия и наименьших квадратов совпадают. Обозначим
тогда оценку а найдем из условия
n
å (хi - a)2 =
i = 1
^ n
¶Q/¶ а = - 2 å (хi - a) = 0. (2.9)
i = 1








